Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Navi Speculation, Rumours and Discussion [2019-2020]
- Thread starter Kaotik
- Start date
- Status
- Not open for further replies.
DavidGraham
Veteran
#RTXOn is simply a context to win prizes by leaving comments on social media about which game the user wants to see RTX integrated into it. It has nothing to do with Xbox or PlayStation or whatever. It's a running theme through all E3 content regardless of vendors.Btw is this even legal?
You are forgetting that the infamouos R9 3xxx series and Fury was her fault.And assuming the Vega situation was inevitable yeah after that AMD(appears to) steered in the right direction.
Xbox is launch at the end of 2020 so it it more probably the next navi launched in 2020 to be the one with RT.
I dunno look at Pascal ray tracing, it doesnt have any hardware at all and is running it acceptably imo. At least for the methods implemented in actual games, like tomb raider or battlefield.
Also from what I've gathered its async compute performance is what holds it back in demanding scenes.
AMD async compute is much better so should perform better right?
I think it would be a mistake not to support it in some form even software would be sufficient. Sure they would get destroyed in benchmarks but they're gettin beaten pretty bad anyway so why not.
Also from what I've gathered its async compute performance is what holds it back in demanding scenes.
AMD async compute is much better so should perform better right?
Nvidia's way of handling compute and graphics in parallel had issues in past generations. Nvidia's expectations seemed to have the two types more separate, or there was a conflict in how it tracked the two that forced broader stalls and context switches at first, and also less flexibility in allocating SMs to one type or the other. That improved with each generation, such that by Pascal I'd say feature-wise it was in the ballpark of at of some GCN implementations, though some of the later GCN additions might not have directly corresponding features.
The differences are less stark with modern hardware, and the benefits of GCN's implementation were sometimes debatable because its graphics context processing could bottleneck frame times to the point where an Nvidia GPU could get close or do better running the compute synchronously.
There are some possible caveats with ray-tracing, at least going by initial Turing implementations. Ray-tracing on an SM seemed to place a barrier that restricted it from also launching compute, though it's not clear if that was a long-term architectural or implementation limit or a case of teething issues.
While I won't try to interpret the nature of the various rectangles too much, at a glance it seems like this GPU does move more elements into the center of the die, with the shader core section ringing what might be the command processors and part of the cache hierarchy.
0.25 a first view.
While not a perfect match to other layouts, this may mean the L2 or whatever the upper level cache is came in from the sides of the die. That and the way the compute section appears have its blocks to flip orientation twice as much as prior GCN arrays, and without the same symmetry of clusters across all of the new mid-lines is another difference. (Not quite what Nvidia does, but it's closer than before.)
How the hardware for compute and graphics is distributed, or what all of the area in the middle strip and around the center portends should be interesting to hear more on.

If the video is supposed to be of a 40 CU GPU, the arrangement has 20 blocks in the shader array section. Not sure which blocks to interpret as the front end or the L/S and cache blocks. It's possible that since the LLVM changes mention a mode where a workgroup can exist in two CUs that a pair of CUs sharing a front end and possibly other hardware is what was called a workgroup processor.
Those 2x8 pins are confirmed now...

More pins - more power!
anexanhume
Veteran
Rough math says they're now 80-90% of Nvidia on FLOPs translating to game performance comparatively. Much better than Vega.
edit: This seems new.
https://videocardz.com/81012/amd-radeon-rx-5700-xt-and-radeon-rx-5700-final-specs
Radeon Multimedia Engine – Seamless Streaming
Navi Stats
- Improved Encoding (New HDR/WCG Encode HEVC)
- 8K Encode (HEVC & VP)
- 40% encoder speedups
New Compute Unit Design
- 40 RDNA Compute Units
- 80 Scalar Proessors
- 2560 Stream Processors
- 160 64b bilinear filter units
- Multilevel Cache
- 4MB L2, 512Kb L1
- 2x V$L0 Load Bandwidth
- DCC Everywhere
- Streamlined Graphics Engine
- Geometry Engine (4 Prisms Shader Out, 8 Prim Shader In)
- 64 Pixel Units
- 4 Asynchronous Compute Enginers
- Balanced Work Distirbution & Redistribution
- Designed for higiher frequences at lower power
Great Compute Efficiency For Diverse Workloads
- 2x Instruction Rate (enabed by 2x Scalar Units and 2x Schedulers)
- Single Cycle Issue (enabled by Executing Wwave32 on SIMD32)
- Dual Mode Execution (Wave 32 and Wave 64 Modes Adapt for Workloads)
- Resource Pooling (2 CUs Coordiate as a Work Group Processor)
Last edited:
Okay, time for a slight revision: AMD's next Mid-Range GPU is a 225 Watt Mini-Housefire with a blower fan. Going by AMD's SOP it's also overvolted as hell to keep the yield up. In terms of process normalized performance per-watt it's still behind Turing by ~50%. With the HBM joker AMD can get to something High-End'ish next year, maybe around the 2080 Ti, but overall nothing that in any way threatens nVidia's dominant position. I'll probably buy one anyway, because I'm a sucker for housefire silicon.AMD's next "Mid-Range" GPU is a 300 Watt Housefire with a blower fan, the memes write themselves at this point.
Jawed
Legend
https://videocardz.com/81012/amd-radeon-rx-5700-xt-and-radeon-rx-5700-final-specs
https://videocardz.com/81012/amd-radeon-rx-5700-xt-and-radeon-rx-5700-final-specs
with typos fixed:
This refers to SIMD32s")
The scalar ALUs have been really beefed up.
https://videocardz.com/81012/amd-radeon-rx-5700-xt-and-radeon-rx-5700-final-specs
with typos fixed:
New Compute Unit Design
- 40 RDNA Compute Units
- 80 Scalar Processors
- 2560 Stream Processors
- 160 64b bilinear filter units
- Multilevel Cache
- 4MB L2, 512Kb L1
- 2x V$L0 Load Bandwidth
- DCC Everywhere
- Streamlined Graphics Engine
- Geometry Engine (4 Prims Shader Out, 8 Prims Shader In)
- 64 Pixel Units
- 4 Asynchronous Compute Engines
- Balanced Work Distribution & Redistribution
- Designed for higher frequencies at lower power
Great Compute Efficiency For Diverse Workloads
- 2x Instruction Rate (enabled by 2x Scalar Units and 2x Schedulers)
- Single Cycle Issue (enabled by Executing Wwave32 on SIMD32)
- Dual Mode Execution (Wave 32 and Wave 64 Modes Adapt for Workloads)
- Resource Pooling (2 CUs Coordinate as a Work Group Processor)
This refers to SIMD32s
The scalar ALUs have been really beefed up.
Intresting! what about the central area?So this is what I think we might have:
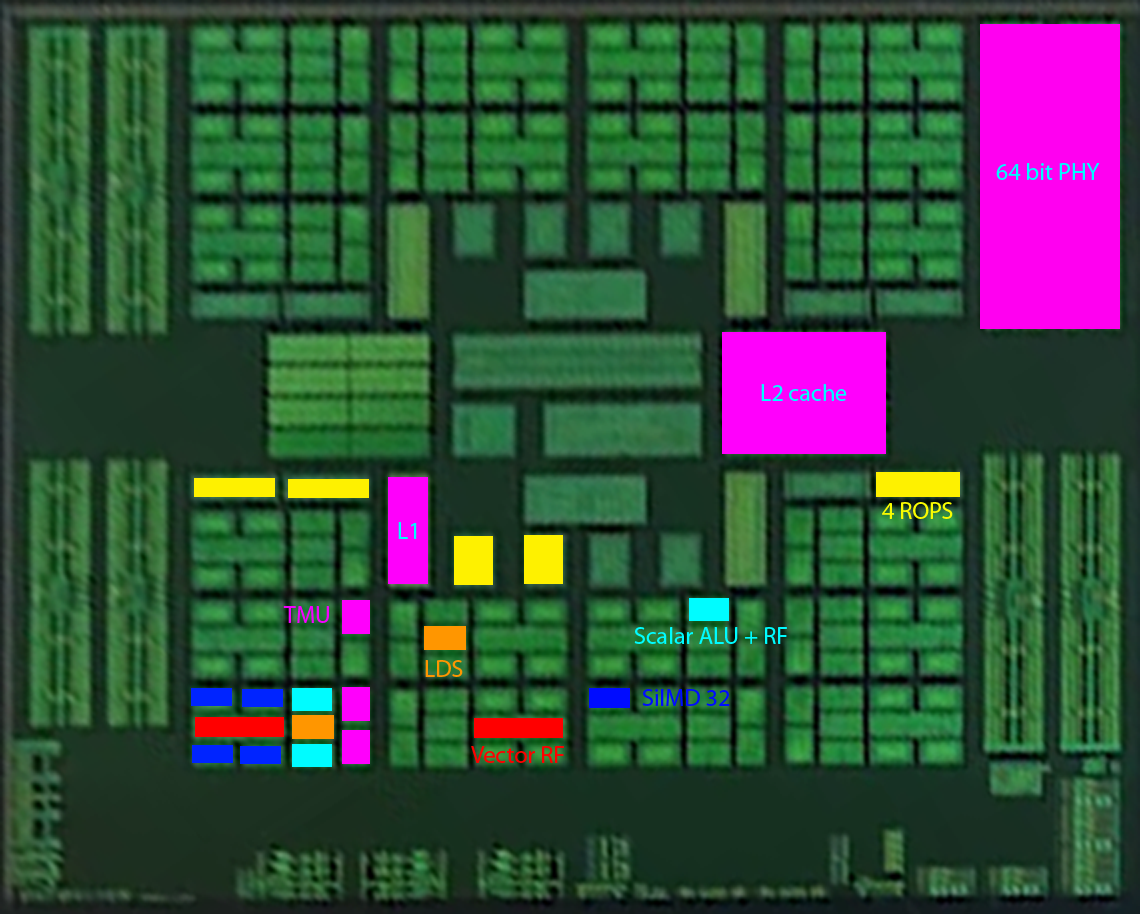
In summary, I think the RF and LDS are shared by two compute units, each with 2x SIMD-32, SALU and TMU.
Each "quarter" is two shader engines, with 2 sets of 2xROP-4s, 64 ROPs in total.
I only see 8 * 4 ROPS, what do I missing?So this is what I think we might have:
In summary, I think the RF and LDS are shared by two compute units, each with 2x SIMD-32, SALU and TMU.
Each "quarter" is two shader engines, with 2 sets of 2xROP-4s, 64 ROPs in total.
anexanhume
Veteran
I think so. AMD had a patent on variable wavefront sizing.Does that mean wavefront size can be either 32 or 64 or do I misunderstand this...
Oh, and apparently full speed fp16 texture filtering, catching up with nvidia (since fermi IIRC) there...
Jawed
Legend
Stuff! Too coarse-grained to say much about those blocks.Intresting! what about the central area?
Fascinating that work can be issued in 32-work item hardware threads. I was expecting 64 and 128...Does that mean wavefront size can be either 32 or 64 or do I misunderstand this...
I've added extra yellow blocks to the picture. Hopefully the picture will update soon to show them.I only see 8 * 4 ROPS, what do I missing?
I also added L1, just for the sake of it.
- Status
- Not open for further replies.