Rogame, who has good track record so far, claims it's 80 CUs for Big Navi
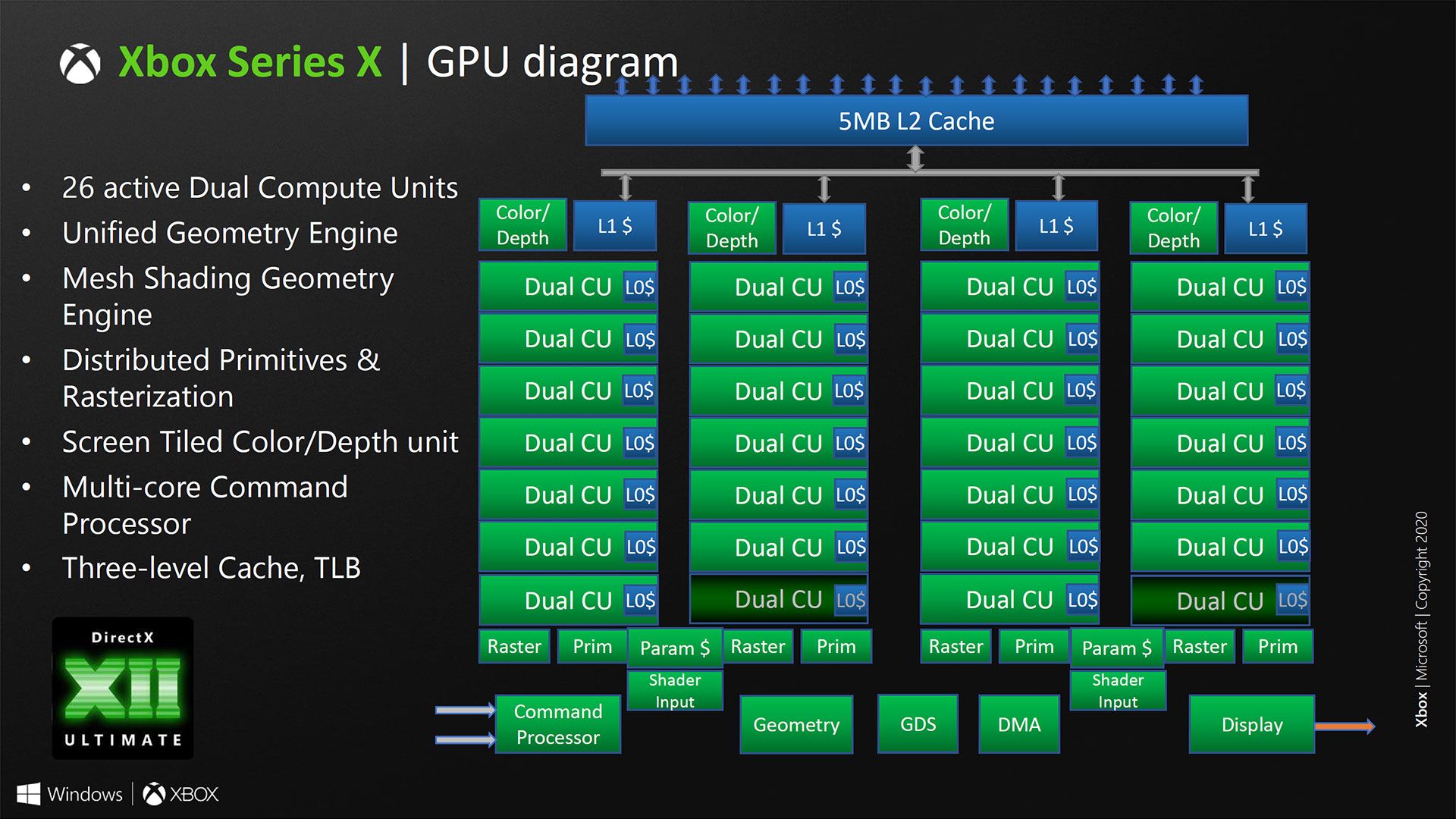
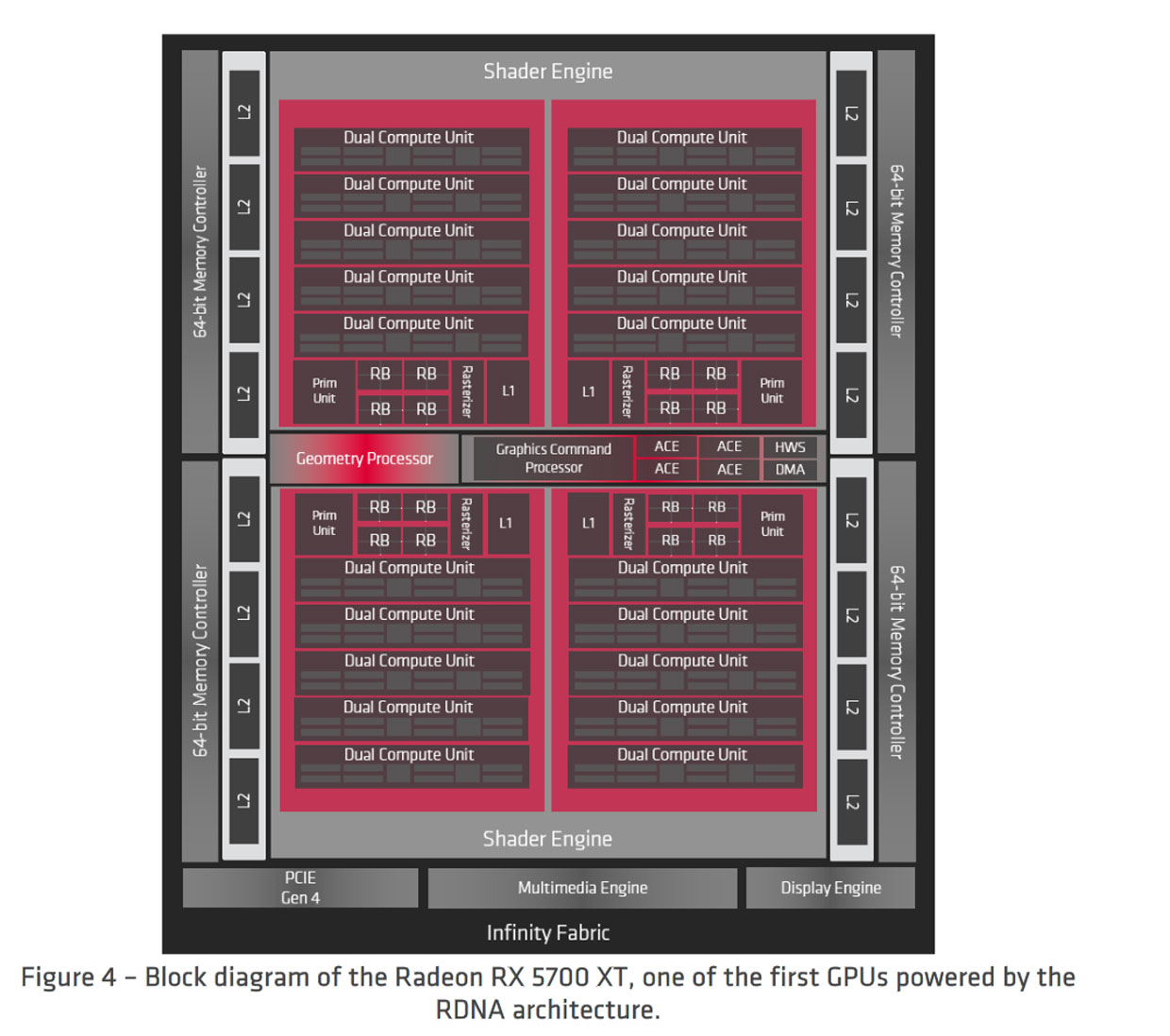
The table seems to imply bringing the RBE arrangement back in-line with the shader engine count, versus shader arrays in RDNA1. Other elements, like the geometry units and L1 caches were also arranged along those lines, so how that would be handled could be an area of change as well.
I'm not sure I've seen the context around that term. I have seen driver references to RB+ modes, but those would be a much older concept than RDNA.Wasn’t there a reference a little while back about RBE+? Something new?
:smile2:
Over the generations, the RBEs have been moved from direct links to the memory controllers to be clients of the L2, then L1, in addition to compression. The relatively modest debut of the DSBR included some indications of bandwidth savings as well.hum..... so 64 ROPs @ 2GHz = 1TB/s for FP16 writes or blending INT8 (8 bytes per pixel). Until GDDR6/HBM2, there wouldn't have been enough bandwidth to feed more fillrate anyway (@ Hawaii & Vega clocks on GDDR5/HBM1), compute needs aside.
There are optimizations for particle effects tuned to the tiny ROP caches that can lead to significant bandwidth amplification, and moving the RBEs inside larger cache hierarchies can give at least some additional bandwidth.
For clarity, is the first statement about not needing SerDes carrying over to the description of the IFOP link?That depends on the packaging tech. If they use 2.5D TSV, SerDes is likely unnecessary since it can be dense enough to carry all the links as if they are on-chip 32B/64B data buses. Though having a read at the Zen 2 ISSCC presentation, there seem to be an argument against interposers (?).
Zen 2 CCD is 74 mm2, with the IFOP taking ~8% of the space, meaning ~6 mm^2. Each gives 32B read + 16B write per clock. Assuming one IFOP per two GDDR6 channels, that'd gives 8 IFOPs for ~48 mm^2, providing 384-768 GB/s aggregate at 1-2 GHz.
I thought IFOP still used SerDes, at 4x transfers per fabric clock.
I'm hazy on whether this figure includes the controllers along with the PHY blocks, which may change the per-link area. Whether a GPU subsystem with more thrash-prone caches would also prefer symmetric read/write bandwidth may also be an area adder.
The 16 seems to be inherent to the way the L2 slices serve as the coherence agents for the GPU's memory subsystem. A little less clear for RDNA/GCN is how the write path's complexity has changed. The RDNA L1 is listed as a read-only target, so how CU write clients are handled may add additional paths. One area I'm curious about is the RBEs and how their write traffic works the the L1, since AMD stated the RBEs were clients of the L1.In RDNA 1 they have reduced the L1-L2 fabric complexity from a 64/16 to 5/16. I had wondered why they even bother to have 16 servers for only 5 clients in the design. Now in retrospect, it looks like an incremental change over Vega towards this, given teasers like "X3D stacking".
(late edit: One thing I forgot to add is that in the 5/16 arrangement, each L1 can make 4 requests per clock, so the L2's slice activity isn't limited by L1 count.)
One thing to evaluate at some point is what it has meant in the past that AMD's subsystem has maxed out at 16 texture channel caches, which are another term for the L2 slices. At least internal to the L2, per-clock bandwidth would seem to be constant between RDNA1 and RDNA2, barring a change in the L2 design. If the RBEs are L1 clients like they were in RDNA, what that means for L1 distribution in big Navi and the internal bandwidth situation could be interesting angles to investigate. A straightforward carry-over from RDNA1 would leave the metric of per-clock internal bandwidth the same across RDNA1 and RDNA2 implementations with 256-bit buses or wider.
Last edited: