They were not. For Vega it was "at the same frequency", but for Navi it's for a particulars product, so not at the same frequency, but for a product "as is".no , they claimed exactly the same with VEGA
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: Navi Speculation, Rumours and Discussion [2019-2020]
- Thread starter Kaotik
- Start date
- Status
- Not open for further replies.
They were not. For Vega it was "at the same frequency", but for Navi it's for a particulars product, so not at the same frequency, but for a product "as is".
Actually Vega 20 has the same perf./watt. as NAVI + NAVI RDNA should add 1,25x performance per clock over older GCN products. However we don´t know how these changes affect max. frequency = Navi might clock lower than Vega, etc. IPC gain is not cost free....
snc
Veteran
Lol at this screen is written: 1.25 per at the same power. With navi they claim 1.5 per at the same power.no , they claimed exactly the same with VEGA , 1,25x performance and 1,5x perf./watt
https://images.anandtech.com/doci/13923/next_horizon_david_wang_presentation-06.png
Lol at this screen is written: 1.25 per at the same power. With navi they claim 1.5 per at the same power.
No, you just confuse "performance" with "perf./watt." metric.
snc
Veteran
So explain me whats the difference beetwen performance at the same power vs per/wNo, you just confuse "performance" with "perf./watt." metric.

DavidGraham
Veteran
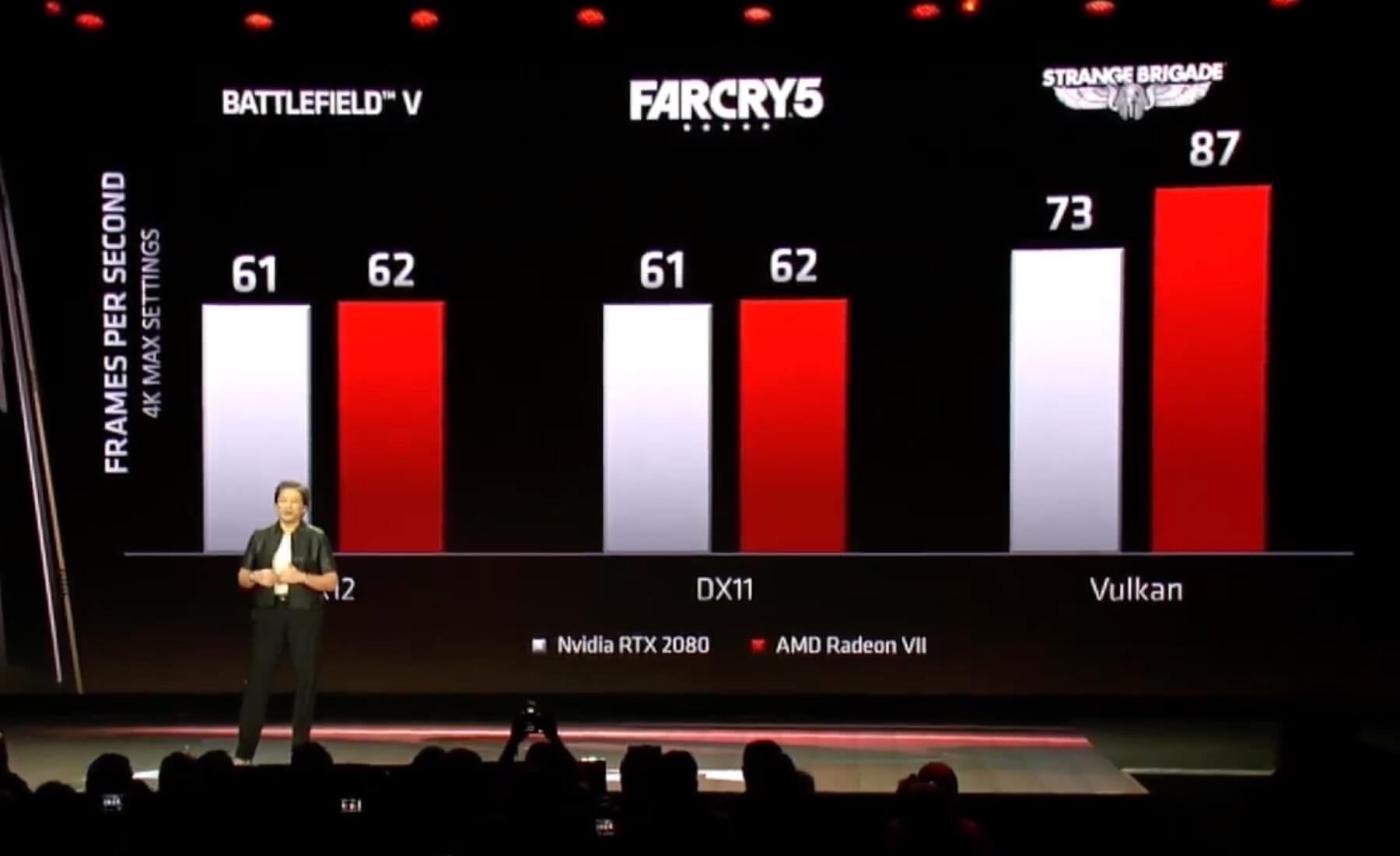
They did so in Vulkan as to show a situation where they are largely ahead. They never showed a game where they had lower performance in any API, despite claiming to win some and lose some versus Turing, so they DID cherrypick their best results in all APIs.AMD presented RVII performance in three games representing three APIs (DX11, DX12, Vulkan). They haven't cherry picked only "their absolute best result".
NVIDIA never released a driver where they publicly stated it improves Strange Brigade performance in any meaningful capacity.Nvidia released drivers, which boosted performance in Strange Brigade, so situation changed.
That one recently recieved a driver update from NVIDIA with official notes stating it increased performance by 18% in Vulkan.Strange Brigade was never "their absolute best result" and is not even today. E. g. Radeon VII in World War Z @2560×1440 performs 28 % faster than RTX 2080. That would be probably "their absolute best result" to present Navi if(!) the architecture prefers the same workloads.
I don't know, maybe because this one game favors both?Why should we expect, that a game, which was fine with Vega architecture, will be the best choice for Navi architecture? There are several games, which like Polaris, but don't like Fiji.
That IS a speculation.It's not likely, that Navi prefers the same type of workloads as Vega, because the compute/fillrate and compute/geometry ratios were completely changed. It will have significantly lower compute performance, but significantly higher geometry performance than Vega.
itsmydamnation
Veteran
So your answer is you dont know for NAVI? correct?
Bondrewd
Veteran
No one does, that's the point.So your answer is you dont know for NAVI? correct?
So explain me whats the difference beetwen performance at the same power vs per/w
yes, you´re right , I did a wrong math. This slide with 50% lower power with Vega 20 confused me... sorry for that. Navi perf/watt is indeed better than Vega20.
no , they claimed exactly the same with VEGA , 1,25x performance and 1,5x perf./watt
https://images.anandtech.com/doci/13923/next_horizon_david_wang_presentation-06.png
That slide shows 1.5 X perf/watt at same frequency, and 1.25 X perf/watt at the same power.
Perf/watt changes depending on frequency because power doesn't scale linearly with frequency.
snc
Veteran
Your welcomeyes, you´re right , I did a wrong math. This slide with 50% lower power with Vega 20 confused me... sorry for that. Navi perf/watt is indeed better than Vega20.
itsmydamnation
Veteran
Depends if this was a full or a cutdown SKU, the funny thing is we will know all this in like 10 days.so my assumption is if they got 1,25 perf/watt gain over Vega 20 and RDNA offer 1,25 x performance/clock, then NAVI should clock wise end at the same frequency as Radeon VII, right ?
Also you can see the FPS on the demo (top left) the 2070 appears to match this 2070, which was uploaded like a day ago :
NAVI demo
D
Deleted member 13524
Guest
Navi pictured next to Matisse:

https://news.mynavi.jp/article/20190530-833748/
This was still taken at an angle, but maybe we can get better measurements.
EDIT: Using Paint without any scientific angle correction, I'm getting 13.7mm width and 18.8mm height, for a total of 257mm^2.
I used anandtech's measurements of Matisse as comparison.
https://news.mynavi.jp/article/20190530-833748/
This was still taken at an angle, but maybe we can get better measurements.
EDIT: Using Paint without any scientific angle correction, I'm getting 13.7mm width and 18.8mm height, for a total of 257mm^2.
I used anandtech's measurements of Matisse as comparison.
Last edited by a moderator:
So explain me whats the difference beetwen performance at the same power vs per/w
Car Analogy:
Old Engine could finish the race at 100 Kilometers per hour using 10 Litres of fuel.
New Engine can finish the race at 125 Kilometers per hour using 6.6 Litres of fuel.
One is about performance, the other is about efficiency.
Nebuchadnezzar
Legend
We have some better pictures of Matisse/Navi alongside a ruler - I still stand by my measurement of around 275mm².Navi pictured next to Matisse:
https://news.mynavi.jp/article/20190530-833748/
This was still taken at an angle, but maybe we can get better measurements.
EDIT: Using Paint without any scientific angle correction, I'm getting 13.7mm width and 18.8mm height, for a total of 257mm^2.
I used anandtech's measurements of Matisse as comparison.
D
Deleted member 13524
Guest
Oh since you apparently didn't publish those, I thought you had used random press photos and image editing.We have some better pictures of Matisse/Navi alongside a ruler - I still stand by my measurement of around 275mm².
Which is why I was also confused by the claimed 5% margin of error, to be honest.
anexanhume
Veteran
Smaller GPUs usually have a larger proportion of their area taken up by controllers and hardware outside of the primary graphics area, so even if smaller on absolute terms, a 256-bit GDDR6 setup can have more of an impact than a quad-HBM2 Vega 7, depending on other factors.
However, one of the other factors is that Vega 7 has an unusually large amount of area around the graphics core, which seems to contribute to the area bloat versus an ideal shrink from 14nm.
One of the possible residents on the die is additional infinity fabric blocks to connect the other HBM controllers, and possibly more mesh connecting the two sides--taking up non-zero area. GDDR6 likely takes up 3 or possibly 3.x sides, and may require a more sprawling interconnect.
There's comments about bank conflicts that seems to indicate that there's a best-effort attempt at gather operands by the CU, and if the conflicts are significant enough there will be stalls. There's no indication of any encoding changes for the instructions to indicate that software has any other means of handling conflicts besides paying attention to the register IDs that belong to the same banks.
https://github.com/llvm-mirror/llvm...b3561b2#diff-1fe939c9865241da3fd17c066e6e0d94
(from GCNRegBankReassign.cpp -- note that it's not called RDNARegBankReassign)
As far as L0, there's more than one context that term has been used. If discussing a destination cache in register file patents, AMD described the output flops of the register file as serving as an L0 for repeated accesses to the same ID, rather than describing the register output cache.
The L0 in the LLVM changes appears to be a CU-local memory pool that plays a role in memory access ordering and can impact data visibility to wavefronts in other CUs, which seems distinct from the question of augmenting the register file and result forwarding within a SIMD.
There seems to be an implication from the above code comments that there are 4 banks of vector register file, and unlike prior GCN architectures it's not a foregone conclusion that an instruction has guaranteed access to them. Going by the description of the stall behavior, it's possible that an FMA could source 3 in the same cycle with the appropriate register allocation pattern.
A significant motivation for the super-SIMD patent is to use the lost operand access cycles and this could entail dual-issue or faster issue latency. The odd way the GFX10 changes document latencies may be consistent with something along those lines.
I'm not clear on the full purpose of it, but it's called an L0 and there's mention of an L1 as well. Possibly, there's an L2 or something else beyond. The HBCC in Vega is past all the cache layers, and since its job is paging resources into the local VRAM pool it's not specced to handle something like all the local cache output of the CUs.
I agree about the negative area on Vega 20. I wonder if it is at all related to needing a 7nm pipe cleaner (i.e. quick turn design) or if it’s a simple function of power and heat density. Perhaps they couldn’t go smaller because they needed the pins to move current and avoid excessive IR losses.
snc
Veteran
There is no slide that telling 1.5 X perf/watt at same frequency. There is navi slide that claims 1.25 X perf per clock and also 1.5 X perf/watt. Slides for amd vii claims 1.25x per at the same power which is the same as 1.25x per/w ( The watt (symbol: W) is a unit of power - wikipedia)That slide shows 1.5 X perf/watt at same frequency, and 1.25 X perf/watt at the same power.
Perf/watt changes depending on frequency because power doesn't scale linearly with frequency.
anexanhume
Veteran
It’s self consistent. Radeon 7 has 1.25 perf/Watt, Navi has 1.25x perf clock. Multiplying the 2 gives you ~1.5X. Actually a small regression which may be rounding error or power penalty of GDDR6 vs. HBM2.There is no slide that telling 1.5 X perf/watt at same frequency. There is navi slide that claims 1.25 X perf per clock and also 1.5 X perf/watt. Slides for amd vii claims 1.25x per at the same power which is the same as 1.25x per/w ( The watt (symbol: W) is a unit of power - wikipedia)
- Status
- Not open for further replies.