I think those results suggest it is quite heavy.
Do we have any info on the size of XESS and DLSS?
You can probably open the model and take a peak at how many layers and how many inputs. But they have more than 1 NN in DLSS and several steps inbetween. They do at least 1 for AA and at least 1 for upscaling. Then there is optical flow and probably interim steps as well and I believe 1 more NN for frame gen.
I recall a very old Super Resolution demo available for download by MS that leverages Nvidia's model. That might actually be a starting point. But there's just no comparison point here between PSSR and DLSS. If we can never run PSSR on PC, we will never know how big or small it is.
If you want to go deep into how Tensor Cores work and the math behind them this is the best place for it:
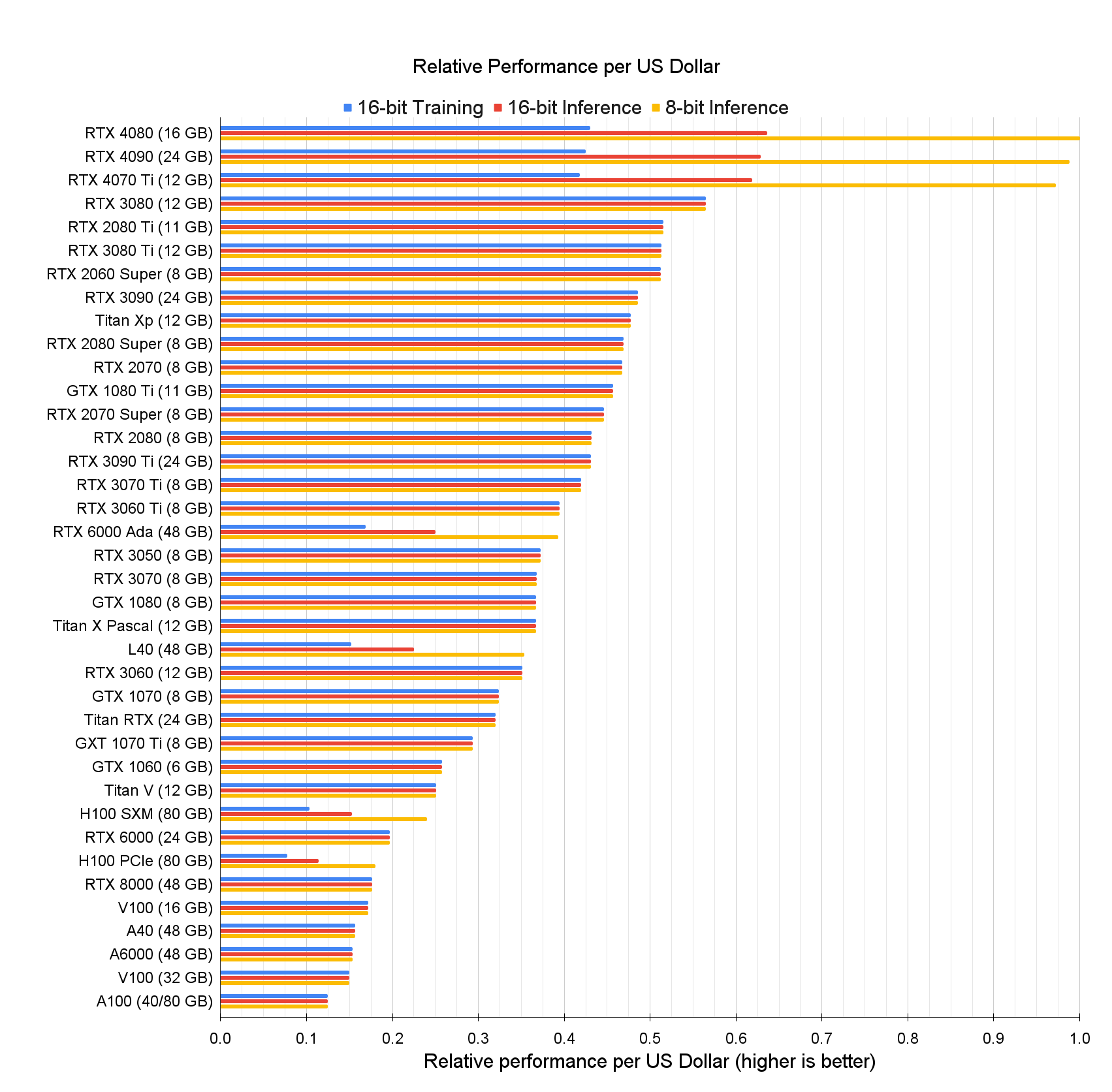
Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.

timdettmers.com
I don't think the 5Pro is bad at it, perse, I do believe that if they hit 300TOPs with CU, those would be the customizations. It does save a TON of silicon and brings the costs down significantly over having separate silicon that may never be leveraged. But as you pointed out, CUs need to share this with rendering, so it cannot do work in parallel, perhaps at best via async compute, but it's not the type fo task you can just switch into and out of.
But also, as you say, extremely bandwidth heavy. So the bottleneck is more likely to be bandwidth than it is compute here.
that being said, the bandwidth for running a model and training a model are very different. There is a whole section on memory bandwidth and cache bandwidth as being a factor in the article. It's important to leverage the knowledge here, but 5Pro is only required to run the model, not train it, and that's significantly less work to do.
but for those of you who aren't interested in reading (believe me, it is well worth the read because everyone seems to have a very strong understanding of graphical pipelines, take some time to learn the ML ones too!)
Memory Bandwidth
From the previous section, we have seen that Tensor Cores are very fast. So fast, in fact, that they are idle most of the time as they are waiting for memory to arrive from global memory. For example, during GPT-3-sized training, which uses huge matrices — the larger, the better for Tensor Cores — we have a Tensor Core TFLOPS utilization of about 45-65%, meaning that even for the large neural networks about 50% of the time, Tensor Cores are idle.
This means that when comparing two GPUs with Tensor Cores, one of the single best indicators for each GPU’s performance is their memory bandwidth. For example, The A100 GPU has 1,555 GB/s memory bandwidth vs the 900 GB/s of the V100. As such, a basic estimate of speedup of an A100 vs V100 is 1555/900 = 1.73x.
") At least not in perf mode and increase internal res. In 30fps mode different story.
At least not in perf mode and increase internal res. In 30fps mode different story.