firstminion
Newcomer
+reg gfx10 mmSUPER_SECRET mmio 0x12345670

Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
+reg gfx10 mmSUPER_SECRET mmio 0x12345670
It simplifies what the software has to do in order to support the multi-chip GPU. The cache invalidation process is heavyweight enough that I'm not sure about the extent of the delay that could be added by another GPU performing the same invalidation. The microcode processors and separate hierarchies wouldn't normally be trying to check externally, so there would be additional synchronization on top of that.Oh, I see. I think that's weird to want, because you loose all the flexibility it could give.
On the other hand, EPYC doesn't look like 1 CPU core transparently just wider. Maybe that "complete" degree of transparency wasn't exactly asked for from chiplets (or threadlets, corelets, modulets), rather something more realistic.
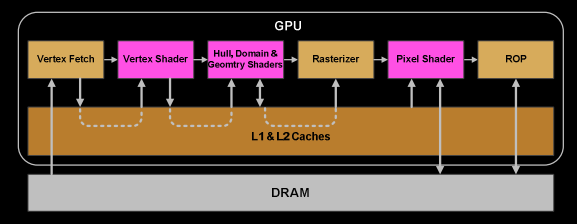
The infinity fabric itself is agnostic to the topology that might be chosen for an implementation. If the topology in question that moves ROPs off-chip differs from the more recently discussed systems with constrained connectivity to the stacks, it can avoid the general-purpose memory from being blockaded by the mostly unidirectional traffic of the export bus. The challenge of taking a broad bus off-chip is that the orders of magnitude worse power and physical constrains reveal what costs the design used to treat as effectively "free", or what elements of the design are not prepared to deal with arbitration involving a sea of formerly invisible competing clients if it's all going over a single general-purpose connection.In Infinity Fabric, compute nodes are multi-ported. The question is whether the base logic die under a stack of memory is a compute node or a memory node in an IF system.
GPUs generally tolerate latency in the data path to DRAM. GCN's wait counts give something of an idea of the relative weights the architecture has between the vector path to heavily contended external memory, and bespoke internal paths the architecture has hardwired limits on. I would expect a change in the costs and behavior of exports may require an evaluation of the bits devoted to export counts. Vega has shifted things substantially in favor tolerating vector memory stalls, given the extra bits it gave to VMCNT.Obviously GPUs don't mind latency in general. So then bandwidth is the real question. In graphics, ROPs are the primary bandwidth hog, but too much imbalance in favour of intra-PIM bandwidth is going to hurt compute.
The most recent discussion centered on solutions without interposers--which for this use case are even worse-off, but that aside I am fine with 2.5D and/or 3D integration and manufacturing.This is the fundamental question that we're really struggling for data on, so I'm not trying to suggest it's easy. Obviously an interposer is seen as a solution to bandwidth amongst chips. I don't share your utter disdain for interposers, for what it's worth. They, or something very similar, are the target of lots of research simply because the pay-off is so great.
There's still latency. The shader engine front end pipeline and workgroup/wavefront arbitration path are significantly less parallel. Their interactions with more of the traditional graphics abstractions and command processor elements relative to CU-dominated compute means there are interactions with elements with low concurrency and wide scope.I think it would be useful to think in terms of bandwidth amplification and coherence separately. ROPs and BR rely entirely upon both of these things.
The L1s are rather small and thrash-prone to isolate them more than mitigate the impact of on-die L2 latency and the current scatter/gather. Possibly corner cases with lookup tables/textures, distant entries in a hierarchical detail structure, compression metadata, etc. The coalescing behavior of the L1 is also rather limited, last I checked. Adjacent accesses within a given wave instruction could be coalesced, but even mildly out of order yet still equivalently coalesce-able addresses might translate into separate L2 hits.Vega now provides L2 as backing for "all" clients (obviously TEX/Compute have L1, so they're partially isolated). e.g. Texels are fairly likely to only ever see a single CU in any reasonably short (intra-frame) period of time. So that's not amplification. It's barely coherence, too. And so on.
Atomics, although they could be presumed to be part of the L2 if it's being placed in the PIM.I'm now wondering what fixed-function units should be in PIM, beyond ROPs and BR.
The natural tendency is to stripe addresses across channels to provide more uniform access behavior and to higher bandwidth utilization. An EPYC-like MCM solution that keeps the usual physical association between L2 slices and their nearest channels would stripe a roughly equal number of accesses to local and remote L2s.Remember these are fairly coarse tilings of texture and render targets. Large bursts to/from memory imply substantial tiles.
It simplifies what the software has to do in order to support the multi-chip GPU. The cache invalidation process is heavyweight enough that I'm not sure about the extent of the delay that could be added by another GPU performing the same invalidation. The microcode processors and separate hierarchies wouldn't normally be trying to check externally, so there would be additional synchronization on top of that.
Zen's coherent caches and generalized fabric make it generally the case that execution will proceed equivalently regardless of which CCX or chip its processes may span. It's true that it doesn't pretend to be one core, but that's where the graphics context differs. A GPU has a heavier context and abstraction, since it is actually a much less cohesive mass of processors.
So finally, in Vega, AMD made all graphics blocks clients of L2. AMD took its sweet time making this change. So, yes, it is clearly something you do cautiously and PIM with remote L2s adds another layer of complexity.The infinity fabric itself is agnostic to the topology that might be chosen for an implementation. If the topology in question that moves ROPs off-chip differs from the more recently discussed systems with constrained connectivity to the stacks, it can avoid the general-purpose memory from being blockaded by the mostly unidirectional traffic of the export bus. The challenge of taking a broad bus off-chip is that the orders of magnitude worse power and physical constrains reveal what costs the design used to treat as effectively "free", or what elements of the design are not prepared to deal with arbitration involving a sea of formerly invisible competing clients if it's all going over a single general-purpose connection.
I'm thinking about compute algorithms here, rather than graphics. The issue I see is that while it might be possible to have say 4:1 intra-PIM:extra-PIM, compute algorithms running outside of PIM (on ALUs which are too hot for a stack of memory) may not tolerate that. So taking Vega as an example, let's say the ROPs have 400GB/s to themselves and the rest of the chip has to share 100GB/s. That will surely hurt compute, but might be completely fine for graphics.How extreme would the ratio have to be in order to deeply cut into the external path's effectiveness?
Those functions aren't latency sensitive though.There's still latency. The shader engine front end pipeline and workgroup/wavefront arbitration path are significantly less parallel. Their interactions with more of the traditional graphics abstractions and command processor elements relative to CU-dominated compute means there are interactions with elements with low concurrency and wide scope.
ROPs do very little work on the fragment data they receive and spend very little time doing that work (deciding which fragments to write, blending/updating MSAA and depth/stencil).The ROPs traditionally were meant to brute-force their high utilization of the DRAM bus with their assembly-line handling of import/export of tiles, which is less about having the capacity to handle unpredictable latency than it is having a generally consistent stream coming over the export bus.
Yes, precisely. L1s are more "cache by name" than "cache by nature". At least for TEX. But for writes there's more value. It's really hard to find anything really concrete.The L1s are rather small and thrash-prone to isolate them more than mitigate the impact of on-die L2 latency and the current scatter/gather. Possibly corner cases with lookup tables/textures, distant entries in a hierarchical detail structure, compression metadata, etc. The coalescing behavior of the L1 is also rather limited, last I checked. Adjacent accesses within a given wave instruction could be coalesced, but even mildly out of order yet still equivalently coalesce-able addresses might translate into separate L2 hits.
They're definitely allowed to be bigger...Still, putting the L2 at a remove over another connection makes the limited buffering capacity of the L1 less effective, and the costs of the connection would encourage some additional capacity.
AMD has recently been increasing instruction cache sizes. Constant cache is another major performance enhancer...The shared instruction and scalar caches may need some extra capacity or backing store, given that vector memory handling is the main focus of GCN's latency hiding.
Naively, it's very tempting to characterise a chiplet approach as consisting of three types:One relative exception could be a video display engine or media processor, which might benefit from proximity in otherwise idle scenarios. That might point to a specific media/IO chiplet with a more modest buffer. Virtualization/security co-processors might do better separate.
Sigh, seems I've gone full circle right back to the start of the thread. So, erm, literally no progress.A key point of the paper is that the logic in the base die has access to substantially higher bandwidth from within the stack (4x). I'm not sure if this is actually possible with HBM. One could argue that a new variant of the HBM stack could be designed such that intra-stack bandwidth would be monstrous but ex-stack bandwidth would be a fraction of that value.
It's a matter of degree.Well, thread migration sucks, always. There is no processor where this is free or even cheap.
For the graphics domain elements in question, there is no coherence or correctness ever. Without going to a higher driver/OS function, they're either wrong or physically incapable of contending.Threaded contention of the cache-lines mapping the same memory region sucks even more. There is only slow coherence over time, which is automatic, true, but very expensive.
At issue here is that CPU semantics have well-defined behaviors and rules for multiple processors. At the hardware level, there is an implementation of both single-processor and multi-processor function as parts of the hardware-enforced model presented to software and developers.In the end, a multi-threat core needs to be spoken too in a very different manner than a single core - even ignoring the change of the algorithm.
These products are intended to be sold to a customer base that would have almost purely legacy software relative to an architecture that mandates explicit multi-adapter as the basis for any future improvement, and the reality of the graphics portion is that this is entrusting the architecture to the work ethic of the likes of EA and Ubisoft, or the average level of competence of software on Steam.Few software engineer do that. When the architecture offers you another more optimal minimum, you rewrite your algorithms. The kernels of high performing algorithms have permutations for even minor architecture changes.
Those who've seen what the industry does if there's even a remote amount of fragility or have software written prior to the introduction of said product.Who would wants this transparent behaviour? And who would see a chance to make the problem being solved faster with the very same amount of traditional GPU resources distributed over more disparate "cores", even compensating some some degree of coherency overhead? I would believe the latter fraction is larger.
Fermi introduced the read/write cache hierarchy and L2. It didn't massively change Nvidia's client fortunes, but might have had long-term economic effects with compute. Maxwell's significant change seems to stem from Nvidia's pulling techniques from its mobile lines into the mainline, with bandwidth and power efficiency gains. Some of those techniques turned out to be early versions of DCC and tile-based rendering, which did heavily leverage the L2 in ways AMD did not prior to Vega.We could ask why AMD has stayed away from this for so long when it's been a key part of NVidia's GPUs since, erm ... Fuzzy memory alert. A long time... Was NVidia's adoption of an L2 based architecture the fundamental reason it killed AMD with Maxwell onwards?
For Nvidia, it does seem like many of those do rely heavily on the L2. Does geometry flow through the L2?Distributed, load-balancing rasterisation (relies upon geometry flowing easily), delta colour compression, tiled rasterisation. All these things rely upon L2 being at the heart of the architecture, as far as I can tell.
It could be a half-attempt, given some of its anomalies seem to align with not disturbing the old paths.Vega just looks like a half-broken first attempt with many "anomalies" in bandwidth-sensitive scenarios and awesomely bad performance per watt.
One thing I noted when comparing the earlier TOP-PIM concepts versus AMD's exascale chiplets is that there may have been a change in AMD's expectations of processing in memory.I'm thinking about compute algorithms here, rather than graphics. The issue I see is that while it might be possible to have say 4:1 intra-PIM:extra-PIM, compute algorithms running outside of PIM (on ALUs which are too hot for a stack of memory) may not tolerate that.
I was thinking of DICE's method for triangle culling in compute citing the risks of not quashing empty indirect draw calls, since the command would be submitted to the command processor, which would then sit on it while reading the indirect draw count from memory. The whole GPU could not hide more than a handful of those.Those functions aren't latency sensitive though.
I recall Vega reduced the maximum number of CUs that could share an instruction front end to allow for higher clocks. That's a modest increase per-CU in a maximal shader array, though I think the instruction cache is still the same size.AMD has recently been increasing instruction cache sizes. Constant cache is another major performance enhancer...
Going by AMD's exascale concept, items like PCIe might be built into the interposer as well.Naively, it's very tempting to characterise a chiplet approach as consisting of three types:
- an interface chiplet - PCI Express, pixel output, video and audio engines, top-level hardware scheduling
- shader engine chiplets - CU with TEX
- PIMs - ROPs, BR
I remember L2 being key in the tessellation data flow.For Nvidia, it does seem like many of those do rely heavily on the L2. Does geometry flow through the L2?
https://techreport.com/review/30328/amd-radeon-rx-480-graphics-card-reviewed/2I recall Vega reduced the maximum number of CUs that could share an instruction front end to allow for higher clocks. That's a modest increase per-CU in a maximal shader array, though I think the instruction cache is still the same size.
So, not an increase in cache size, but a tweak to how the cache is used.If many wavefronts (AMD's name for groups of threads) of the same workload are set to be processed, a new feature called instruction prefetch lets executing wavefronts fetch instructions for subsequent ones. The company says this approach makes its instruction caching more efficient. Polaris CUs also get a larger per-wave instruction buffer, a feature that's claimed to increase single-threaded performance within the CU.
Actually just like he said, they reduced the number of CUs that can share same instruction & constant cache from 4 to 3, while the cache itself is the same size as before.So, not an increase in cache size, but a tweak to how the cache is used.
YES Post-Transform Geometry stays on-Chip in the L2.For Nvidia, it does seem like many of those do rely heavily on the L2. Does geometry flow through the L2?
And there is a bit of emphasis on the cache coherency in that slide, which is why I wonder if AMD solution is just not as flexible or efficient in this context.YES Post-Transform Geometry stays on-Chip in the L2.
i am not allowed to post links, yet. but i try
https://www.techpowerup.com/img/17-03-01/f34e39b49c7c.jpg
And there is a bit of emphasis on the cache coherency in that slide, which is why I wonder if AMD solution is just not as flexible or efficient in this context.
In keeping with “Vega’s” new cache hierarchy, the geometry engine can now use the on-chip L2 cache to store vertex parameter data.
This arrangement complements the dedicated parameter cache, which has doubled in size relative to the prior-generation “Polaris” architecture. This caching setup makes the system highly tunable and allows the graphics driver to choose the optimal path for any use case.
Maybe I missed it, but where do you see the L2 mentioned?About geometry on NV, it always routes through L2
http://on-demand.gputechconf.com/gt...bisch-pierre-boudier-gpu-driven-rendering.pdf
Once the warp has completed all instructions of the vertex-shader, its results are being processed by Viewport Transform. The triangle gets clipped by the clipspace volume and is ready for rasterization. We use L1 and L2 Caches for all this cross-task communication data.