This is really no problem as the hardware access is behind so many layers that you can make it transparent on the API level. DX11 co-exists with DX12 for that reason. DX12 already has all the API needed to cover chiplets, but well, if you don't want to even see that there are chiplets, then drop in an alternative kernel implementation which has exactly one graphics queue, and one compute queue, for compatibility sake. Or lift it up to DX13.
Is the alternative kernel with one queue for each type expected to scale with an MCM GPU, or is it expected to perform at 1/N the headline performance on the box? Is it expected to run with 1/N the amount of memory?
One interpretation of the statements of the then-head of RTG was that AMD's plans were have developers manage the N-chip case explicitly, not extend the abstraction.
I think this would reduce the desirability of such a product for a majority of the gaming market, absent some changes and a period of time where AMD proves that this time it's different. There's been evidence in the past that SLI on a stick cards lost ground against the largest single-GPU solutions, and multi-GPU support from the IHVs has in recent products regressed.
If there's certainty that competing products will make the same jump to multi-GPU and with the AMD's claimed level of low-level exposure, then it might be able to make the case that there is no alternative. Even then, legacy code (e.g. everything at hardware launch time) might hinder adoption versus the known-working prior generations.
If the possibility exists that a larger and more consistent single-GPU competitor might launch, or gains might not be consistent for existing code, that's a riskier bet for AMD to take.
Further, if the handling of the multi-adapter case is equally applicable to an MCM GPU as it is to two separate cards, how does MCM product distinguish itself?
From experience I can tell you, bringing a engine to support multi-core CPUs was a way way more prolonged and painful path then bringing one to support multi-GPU. The number of bugs occuring for the former is still very high, by the nature of it, the number of bugs occuring for the latter is ... fairly low, because it's all neatly protectable [in DX12] and bakable into management code.
At this point, however, I would cite that nobody can buy a one-core CPU and software can be expected to use at least 2-4 cores at this point. There's been limited adoption and potentially a negative trend for SLI and Crossfire. The negative effect that those implementations have had on user experience for years isn't easily forgotten, and we have many games that are not implemented to support multi-GPU while the vendors are lowering the max device count they'll support.
Fair or not, the less-forgiving nature of CPU concurrency has been priced in as an unavoidable reality, and the vendors have made the quality of that infrastructure paramount despite how difficult it is to use.
I wish I could address individual CUs already, so I could have my proto-chiplet algorithms stabalize before hitting the main target.
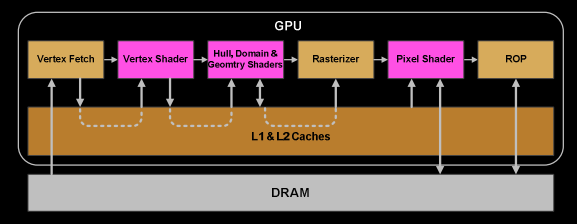
This gives me the impression of wanting things both ways. The CUs are currently held beneath one or two layers of hardware abstraction and management within the ASIC itself, and those would be below the layers of software abstraction touted earlier. There are specific knobs that console and driver devs might have and high-level constructs that give some hints for the low level systems, but there are architectural elements that would run counter to exposing the internals further.
In any case, for GPUs, I don't believe you have to drop all this behaviour into the circuits, you have the luxury of thick software layers which you can bend.
Not knowing the specifics of the implementation, there's potentially the game, engine, API, driver(userspace/kernel), front-end hardware, and back-end hardware levels of abstraction, with some probable omissions/variations.
The lack of confidence in many of those levels is where the desire for a transparent MCM solution comes from.
A super-cluster has no hardware to make the cluster itself appear coherent, but it has software to do so to some degree. The scheduling is below a thick layer of software, it has to be, it's way too much sub-systems involved to do this yourself.
I think there are a number of implementation details that can change the math on this, and if a cluster uses message passing it could skip the illusion of coherence in general. The established protocols are heavily optimized for throughout the stack, however. I'm not sure how comparable the numbers are for some of the cluster latency figures versus some of those given for GPU synchronization.
I wonder about the impact of the x86 memory model on people's mind-set. I had to target ARM multi-core lately, and uggg, no coherence sucks if all your sync and atomic code depends on it. But then the C+11 threaded API was a great relief, because I only need to state what I need and then it will be done one way or another.
Relying on the C++ 11 standard doesn't remove the dependence on the hardware's memory model. It maps the higher-level behaviors desired to the fences or barriers provided for a given architecture. For the more weakly-ordered accesses that aren't considered synchronized, the regular accesses for x86 are considered too strong, but for synchronization points x86 is considered only somewhat more strong than is strictly necessary. Its non-temporal instructions are considered too weak.
More weakly-ordered architectures have more explicitly synchronized accesses or heavyweight barriers, and the architectural trend for CPUs from ARM to Power has been to implement a more strongly-ordered subset closer to x86 for the load-acquire/store release semantics.
The standard's unresolved issues frequently cover when parts of its model are violated, often when it comes to weaker hardware models turning out not being able to meet the standard's assumptions or potentially not being able to without impractically heavy barriers.
That aside, the question isn't so much whether an architecture is as strongly-ordered as x86, but whether the architecture has defined and validated its semantics and implementations, or has the necessary elements to do so. The software standard that sits at the higher level of abstraction assumes the foundation they supply is sound, and some of its thornier problems arise when it is not. The shader-level hierarchy would be nominally compliant with the standard, but the GPU elements not exposed to the shader ISA are not held to it and have paths that go around it.

")