GS should just be another thread type for the same units to process (more or less) in R600.trinibwoy said:Wouldn't making each shader in a unified design GS capable be a fundamental design change? I always expected GS to be a separate unit in R600 as well.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The People Behind DirectX 10: Part 3 - NVIDIA's Tony Tamasi
- Thread starter Hanners
- Start date
Previously only specific tesselation algorithms like n-patches (Truform) and rt-patches have been supported by the APIs. So generalized tesselation likely means the developer isn't restricted to a specific method, but has the ability to create their own scheme through a program.Tammuz said:What would be "generalized tesselation"?
Rys said:GS should just be another thread type for the same units to process (more or less) in R600.
Bueno.
Rys said:GS should just be another thread type for the same units to process (more or less) in R600.
Okay, then the more difficult question --if there are 48 or 64 or [insert flavor of the day here] of these GS-capable units in R600, then why do the whispers on the wind seem to be expecting less-than-impressive performance for GS from next-gen parts? Is it just a "v1" bigotry expectation? If not, then what's so special about GS functionality that can't be beaten into some reasonable facsimile of submission by that many units?
Edit: And baaaad geo for not just looking at ATI's dx10 material, which has shown up many places, and says right in it that "Common Shader engine used to execute vertex, geometry, and pixel, maximizing shader performance efficiencies". http://www.hardocp.com/image.html?image=MTE0NjQxNzgxNmFxQ3hpUHdDNG5fM182X2wuanBn
But the question remains --are our expectations for GS performance too low? If it is going to be less-than-impressive, then why, with all those units to throw at it? Is the bottleneck not the units? Or is the volume of instructions to be really useful so much bigger than what we've seen so far with PS and VS?
For extra credit, discuss whether --if the "NV unified VS and GS, but not PS" crowd are correct-- might there be a signficant difference in GS performance between the IHVs? Or might NV have spent some healthy portion of their budget pumping up the # of GS/VS units rather than PS compared to G71? Will the great Talmudic discussions at B3D move from PS/Tex ratio to PS/GS ratio?
")
And for the gold star. . .are Green and/or Red working feverishly on some kick ass GS demos for next-gen release?
The main bottleneck with GS isn't the compute power, it's the programing model. Unfortunately, it's not very parallel. All triangles of the first GS thread must complete (in order) before you can move on to the next GS thread. If you run several GS threads simultaniously, you need storage for all but the first one to save up all the generated triangles until you can rasterize them in API order.geo said:why do the whispers on the wind seem to be expecting less-than-impressive performance for GS from next-gen parts?
Let's say a GS outputs 4 triangles out of each input triangle, and you have 4 vec4 attributes per vertex. Let's also say you have 64 GS units runing simultaniously, and each one is running 8 threads to cover its own latency. That means you need storage for approximately 64 * 4 * 4 * 4 * 4 * 8 = 128 KB of dedicated (on-chip?) storage.
If you have more vertex attributes, or are outputing more triangles, you must run less GS threads (which reduces your shader efficiency), or you must add more storage (costs $$$).
Chalnoth said:From that description it sounds like both IHV's may be implementing their own separate GS units.
No ATI have already confirmed that everything is unified. It would expect that the number of GS threads that will run at the same time will be limited depending on the max output value of the GS program.
Bob said:The main bottleneck with GS isn't the compute power, it's the programing model. Unfortunately, it's not very parallel. All triangles of the first GS thread must complete (in order) before you can move on to the next GS thread. If you run several GS threads simultaniously, you need storage for all but the first one to save up all the generated triangles until you can rasterize them in API order.
Let's say a GS outputs 4 triangles out of each input triangle, and you have 4 vec4 attributes per vertex. Let's also say you have 64 GS units runing simultaniously, and each one is running 8 threads to cover its own latency. That means you need storage for approximately 64 * 4 * 4 * 4 * 4 * 8 = 128 KB of dedicated (on-chip?) storage.
If you have more vertex attributes, or are outputing more triangles, you must run less GS threads (which reduces your shader efficiency), or you must add more storage (costs $$$).
Ah ha. Thanks. The implication of that then is it isn't a "next gen hardware" issue at all, but something we may have to live with for the duration of D3D10 (and, I suppose, possibly beyond). Any hints it's on the drawing board with MS to improve the performance limitations imposed by the api model?
Jawed
Legend
According to:
http://download.microsoft.com/download/f/2/d/f2d5ee2c-b7ba-4cd0-9686-b6508b5479a1/Direct3D10_web.pdf
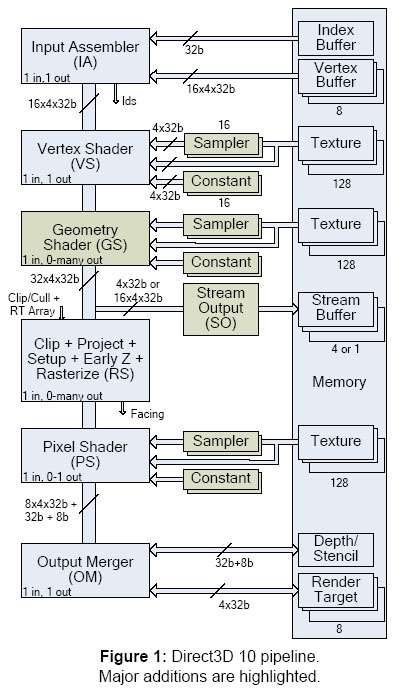
each primitive can output 1024 32b values (e.g. 256 Vec4 FP32s), which is 4KB - the diagram doesn't agree with the text indicating only 128 32b values (32x4x32b) for some reason
indicating only 128 32b values (32x4x32b) for some reason
There's no reason to expect that ATI hardware would be working with such large batches as 64 pipes x 8 primitives = 512 primitives in a batch.
The batch size for vertices/primitives/fragments will prolly all come out the same. I'm gonna guess that it'll be 64 objects per batch: 16-wide and four clocks long (R580 is 12 wide and four clocks long, Xenos is 16 wide and 4 clocks long).
So a single GS batch could write as much as 64 input primitives x 4KB = 256KB. That's even more memory than Bob indicated. I'd guess that's about 100x more memory than a DX9 GPU's post vertex transform cache (which normally only deals with 10s of vertices and their attribute data at a time, maximum).
(which normally only deals with 10s of vertices and their attribute data at a time, maximum).
Even as a minimum, with a unified design shading 64 vertices in a batch, the post-VS cache would prolly be 2x as big as in a DX9 GPU (32 vertices, say). And that doesn't provide any lee-way for load-balancing twixt stages, which a unified architecture needs.
While the GS is producing vertices and their attributes, putting them into the post-GS cache, the following stages (Clip+Project+...) are consuming the vertices - "pixel shading consumes the vertex data". The relative rates at which vertices are put into, and taken out of PGSC are obviously unpredictable (taken out: how many triangles are culled?; how many fragments are produced by each triangle?; how long are the pixel shaders?, etc.).
Since a unified architecture is predicated upon using inter-stage queues to smooth out the scheduling of batches, perhaps it's worth arguing that the cost of a large PGSC isn't so troublesome - unified architectures seem to use lots of memory as a trade for enhanced per-ALU utilisation (the register file seems to be over-sized, too). Memory is cheap (and easy to make redundant for good yield). Though as memory increases, it gets slower and harder to access.
You could deliberately size the PGSC so that it can only absorb, say, 128 32b values (instead of 1024) per primitive. The command processor would then issue "smaller" batches than normal if the PGSC can't hold all the data produced by the GS program (e.g. when it wants to output the full 1024 32b values). I dare say the command processor doesn't know in advance how much data that's going to be, so it might be forced to simply junk the GS-output of some pipes and re-submit those primitives in a following batch. So the overall throughput of primitives is cut (as though some pipes are running empty) as the amount of per-primitive data produced by the GS increases.
I suppose you have to ask what's going to be the typical data amplification produced by GS and how will ATI and NVidia choose to support data amplification.
It seems to me that future D3D10 GPUs can scale performance (concurrent primitives being shaded) by increasing the size of the post-GS cache, as well as increasing the total number of pipes for GS. Is GS-vertex-amplification an "architectural by-way" that'll be circumvented by D3D11? I doubt it, what's the alternative to data-amplification within GS?
I get the strong feeling that 1024 32b values per primitive has been cut down from a much larger number. Whether that's because, with batching, the PGSC just gets silly huge or because one IHV thinks that's already way too big compared to a DX9 GPU's PVTC, who knows?
Jawed
http://download.microsoft.com/download/f/2/d/f2d5ee2c-b7ba-4cd0-9686-b6508b5479a1/Direct3D10_web.pdf
each primitive can output 1024 32b values (e.g. 256 Vec4 FP32s), which is 4KB - the diagram doesn't agree with the text
There's no reason to expect that ATI hardware would be working with such large batches as 64 pipes x 8 primitives = 512 primitives in a batch.
The batch size for vertices/primitives/fragments will prolly all come out the same. I'm gonna guess that it'll be 64 objects per batch: 16-wide and four clocks long (R580 is 12 wide and four clocks long, Xenos is 16 wide and 4 clocks long).
So a single GS batch could write as much as 64 input primitives x 4KB = 256KB. That's even more memory than Bob indicated. I'd guess that's about 100x more memory than a DX9 GPU's post vertex transform cache
Even as a minimum, with a unified design shading 64 vertices in a batch, the post-VS cache would prolly be 2x as big as in a DX9 GPU (32 vertices, say). And that doesn't provide any lee-way for load-balancing twixt stages, which a unified architecture needs.
While the GS is producing vertices and their attributes, putting them into the post-GS cache, the following stages (Clip+Project+...) are consuming the vertices - "pixel shading consumes the vertex data". The relative rates at which vertices are put into, and taken out of PGSC are obviously unpredictable (taken out: how many triangles are culled?; how many fragments are produced by each triangle?; how long are the pixel shaders?, etc.).
Since a unified architecture is predicated upon using inter-stage queues to smooth out the scheduling of batches, perhaps it's worth arguing that the cost of a large PGSC isn't so troublesome - unified architectures seem to use lots of memory as a trade for enhanced per-ALU utilisation (the register file seems to be over-sized, too). Memory is cheap (and easy to make redundant for good yield). Though as memory increases, it gets slower and harder to access.
You could deliberately size the PGSC so that it can only absorb, say, 128 32b values (instead of 1024) per primitive. The command processor would then issue "smaller" batches than normal if the PGSC can't hold all the data produced by the GS program (e.g. when it wants to output the full 1024 32b values). I dare say the command processor doesn't know in advance how much data that's going to be, so it might be forced to simply junk the GS-output of some pipes and re-submit those primitives in a following batch. So the overall throughput of primitives is cut (as though some pipes are running empty) as the amount of per-primitive data produced by the GS increases.
I suppose you have to ask what's going to be the typical data amplification produced by GS and how will ATI and NVidia choose to support data amplification.
It seems to me that future D3D10 GPUs can scale performance (concurrent primitives being shaded) by increasing the size of the post-GS cache, as well as increasing the total number of pipes for GS. Is GS-vertex-amplification an "architectural by-way" that'll be circumvented by D3D11? I doubt it, what's the alternative to data-amplification within GS?
I get the strong feeling that 1024 32b values per primitive has been cut down from a much larger number. Whether that's because, with batching, the PGSC just gets silly huge or because one IHV thinks that's already way too big compared to a DX9 GPU's PVTC, who knows?
Jawed
Last edited by a moderator:
Poor nVidia... I can foresee R600 will win all PS/VS/GS specific benchmarking tests.
It is needed to have a well representative benchmarking program that reflect the real-world gaming PS/VS balance. Otherwise, if the benchmark is bias to either PS/VS/GS then G80 will be all screwed...
most ppl do not understand the technical reasons behind... if they see R600 is the best in the results, it will be the best selling card!! <<
What do you guys think?
It is needed to have a well representative benchmarking program that reflect the real-world gaming PS/VS balance. Otherwise, if the benchmark is bias to either PS/VS/GS then G80 will be all screwed...
most ppl do not understand the technical reasons behind... if they see R600 is the best in the results, it will be the best selling card!! <<
What do you guys think?
Jawed said:each primitive can output 1024 32b values (e.g. 256 Vec4 FP32s), which is 4KB - the diagram doesn't agree with the text
If I remember correctly this text (I read it when it was released), it talks about 1024 32bits value per shader invocation, not per primitive. It seemed quite low when I read it.
Well, the majority of benchmarks are still game benchmarks. Pure synthetics are only very rarely used any longer. So it's not all that much of a concern.ccsharry said:most ppl do not understand the technical reasons behind... if they see R600 is the best in the results, it will be the best selling card!! <<
What do you guys think?
Jawed
Legend
I'm confused about the difference in meaning between "invocation" and "per-primitive".Tridam said:If I remember correctly this text (I read it when it was released), it talks about 1024 32bits value per shader invocation, not per primitive. It seemed quite low when I read it.
A GS program can amplify the number of input primitives by emitting additional primitives subject to a per-invocation limit of 1024 32-bit values of vertex data.
(sigh, kept crashing IE when I pasted that!!!)
I can't tell what an invocation is...
Do you have any independent evidence for the correct value? Are you saying that 1024 per primitive is too low?
Jawed
Last edited by a moderator:
Jawed said:I'm confused about the difference in meaning between "invocation" and "per-primitive".
I can't tell what an invocation is...
Do you have any independent evidence for the correct value? Are you saying that 1024 per primitive is too low?
My understanding is that a GS invocation occurs on a batch of primitives. 1024 32bits values would then be per batch of primitive and not per primitive, that's why it seemed low to me. Of course I could be wrong about that.
Jawed said:I suppose if there's an implicit batch size of 8 that's been used for the sake of the diagram, then that would make sense.
Hmm... So 1024x 32b per batch (if a batch is 64 primitives) could be pretty disastrous...
Oh well.
Jawed
It would still be possible to loop around VS/GS with the stream output to amplify more. Of course it would be costly.
Tridam said:My understanding is that a GS invocation occurs on a batch of primitives. 1024 32bits values would then be per batch of primitive and not per primitive, that's why it seemed low to me. Of course I could be wrong about that.
The GS program runs one time for every primitive. It will see all vertices of the primitive as input parameter.
...And is able to output up to 1024 32bit values.Demirug said:The GS program runs one time for every primitive. It will see all vertices of the primitive as input parameter.
P.S.: Say your GS outputs just float4 position, then you'll be able to generate up to 256 vertices. If you add say a 2D texture coordinate then you can only generate 170 vertices.
Last edited by a moderator:
Demirug said:The GS program runs one time for every primitive. It will see all vertices of the primitive as input parameter.
Ok, thanks.
It will also see adjacent vertices (-> up to 6 vertices), won't it ?
Similar threads
- Locked
- Replies
- 10
- Views
- 825
- Replies
- 37
- Views
- 2K
- Replies
- 34
- Views
- 3K