You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Hey! It's the 13th. I want my juicy info!!
- Thread starter oddfellow
- Start date
surfhurleydude said:Stryyder said:surfhurleydude said:Stryyder said:True, must of the article is already common knowledge but there is some interesting information
Quote:
NVIDIA UltraShadow II for 4 times the performance in highly shadowed games (e.g. Doom III) comparing to older GPUs
Confirmation of a 32x0 mode
128 pixel shader operation /clock
They mean 4 times the performance of their older GPU's not ATI's
AFAIK, the NV3x was actually ahead of ATi in terms of shadow performance, as the line simply dominated in all early Doom III benchmarks, and NV35 contained all sorts of upgrades "recommended" by JC himself.
Drinking the Cool Aid?? Doom III was the only game with shaders that the NV3x didn't choke on and die. Since the NV35 was built to play doom and Doom was coded to run on the NV35 this shouldn't be suprising. Unfortunately most people will play more than just Doom 3 and JC will have to release a product that is coded to the DX9x spec.
Can I ask what the hell you are rambling on about? Fact of the matter is, UltraShadow was put in the NV35 line up because of JC's request, and it enhances STENCIL op performance, not shader performance.
That was after how many people bought the POS NV30? They then come out with a patent pending technolgy that is not a part of DX9 that specifically overcomes the shortcomings of their architecture.
It is in Open GL 1.5 but not Direct X and they are trying to lock the technology up with a patent which improves performance in only two games that I know of with only one of them being available today. I just don't think that I would base by purchasing decisions on NVIDIA convincing the developers of the world to start coding on a standard that doesnt exist in DX9.
2x2 may or may not be important. Many 2D texture coordinate manipulations only require two components. Plus everyone seems to be missing the fact that the compiler could break some 4x4 instructions into multiple 2x2 instructions. These extra instructions could be used to keep a shader unit doing useful work when it might normally be stalled due to data dependencies. Even if they don't do this now, they could. Flexible is good.
I agree that their little blurb doesn't say anything about the limitation of the second unit but I am under the impression that both units are identical.
I agree that their little blurb doesn't say anything about the limitation of the second unit but I am under the impression that both units are identical.
Me said:This isn't QUITE true.LeStoffer said:They get to the 128 operations/clock like this:
a) 16 pipelines with...
b) 2 Shader Units each...
c) that can each do 4 instructions (on RGB+Alpha) per cycle (per clock I assume)
Thus: 16 x 2 x 4 = 128
16 pipes, each with 2 shaders.
Each of those shaderss can execute 2 instructions.
Those 2 instructions can have a total of 4 ops.
ie vec3/scalar, or 2 vec2s.
So there are 128 operations, but only 64 instructions the way I read it.
The difference is that if you have 4 scalar adds in a row they all can't execute in 1 clock on one shader.
It would be a stupid shader to hit this case though.
I agree, I meant to write ops not instructions! Doh! It seems I'm getting a little ahead of my self today...
Riff said:2x2 may or may not be important. Many 2D texture coordinate manipulations only require two components. Plus everyone seems to be missing the fact that the compiler could break some 4x4 instructions into multiple 2x2 instructions. These extra instructions could be used to keep a shader unit doing useful work when it might normally be stalled due to data dependencies. Even if they don't do this now, they could. Flexible is good.
I agree that their little blurb doesn't say anything about the limitation of the second unit but I am under the impression that both units are identical.
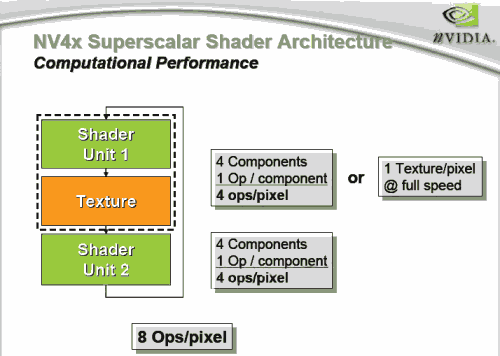
I thought the slide was quite clear.
Shader Unit 1 is highlighted with RGB+A
Shader Unit 2 is highlighted with RG+BA
Shader Unit 1 was also shown to be used to do texture addressing in the previous slide. I tend to think this indicates that the 2 units are different.
Zeross said:You're only talking about co-issue 3/1 VS 2/2 here but GF 6800 has two units each capable of co-issue.
Wasn't it already the case with the NV35 ? I believed the first NV30 had one FP Unit (also responsible for texturing) and two FX units, and NV35 had two FP units.
Joe DeFuria said:NV4x is able to process dual instructions at the same time. It's not clear from their diagram, but it sounds like each PS unit can process either 3/1 or 2/2 operations. So, NV4x could execute dual 3/1 operations per pipeline per clock.
The way I read the diagram (that's now offline so I can't check again) is that, beyond twice the shading power, the distinct feature of NV40 over earlier chips is that it can do 2+2 also. So in normal 1,3,1+3,4 mode it would only be twice as fast, but in 2+2 mode four times as fast. However, 2+2 is not very common, so I don't think this extra flexibility will matter much. That is has twice the shading however of course will.
Joe DeFuria
Legend
Colourless said:I thought the slide was quite clear.
Shader Unit 1 is highlighted with RGB+A
Shader Unit 2 is highlighted with RG+BA
Shader Unit 1 is also shown to be used to do texture addressing.
Yes, but it could be presented that way to higlight the fact that either unit is capable of operating in either mode.
In other words, I don't have high confidence (either way), on whether Shader Unit 2 is "limited" to RG+BA type co-issue or not.
Riff said:I agree that their little blurb doesn't say anything about the limitation of the second unit but I am under the impression that both units are identical.
We have to wait and see, but apparently you can either use Shader Unit1 to do your 4 ops or do 1 texture ops (FP?) at full speed, which implies some sharing of ressources like on the NV3x architecture.
Colourless said:I thought the slide was quite clear.
Shader Unit 1 is highlighted with RGB+A
Shader Unit 2 is highlighted with RG+BA
Shader Unit 1 was also shown to be used to do texture addressing in the previous slide. I tend to think this indicates that the 2 units are different.
I think that it was just for illustration purpose
NV4x can do this as 3/1 or 2/2 pairing of components
Notice that nothing is said concerning limitations on which unit can perform what kind of pairing. It would be really silly to impose such a restriction :?
That's how I interpreted it, too. Shader1 is clearly linked to tex in the first slide.Colourless said:I thought the slide was quite clear.
Shader Unit 1 is highlighted with RGB+A
Shader Unit 2 is highlighted with RG+BA
Shader Unit 1 was also shown to be used to do texture addressing in the previous slide. I tend to think this indicates that the 2 units are different.

dan2097 said:Do you have any idea whether their figure of 128 operations/clock is comparable to ATIs 9800XT value of 40 pixel shader operations/clock from here:
http://www.hardocp.com/image.html?image=MTA2NDg1OTI2NEFrQm9pUVd0ZU5fMV83X2wuanBn
dont' think so, ati were including their texture unit and counting an instruction on a 3 part vector as 1 op.
going on basis set in the PR at digitlife then nv40 is 8ops/pixel/clock or 1 texture + 4ops/clock. r300 is afaik 1 texture and 4 to 8 ops/pixel/clock.
so in total that's 16 textures + 64ops or 128ops for nv40 and 8 textures + 32 to 64 ops/clock (since the mini alus in r300 only do the basic instructions and may not be used) for r300.
of course thats assuming the pr blurb is true, nv30 was claimed to have 8 pipelines orginally and this isn't even official PR for certain yet (digitlife once again pull down an article put up too early
)Damn these things are looking more and more like cpu's. I dunno if the 3/1 2/2 is really a big impact you save a few % but I dunno how much. The dual ALUs probably will have a real impact maybe not in the current gen games bu t in the next gen games I really think will make a difference I'm sure if someone sat down and worked it out there would be 15-40% preformance gain but hey thats just a ball park figure. I'm damn to lazy to work it out meself.
Per pipe:
The NV3x was 1 op (impeded by tex op) + up to 2 limited ops, wasn't it?
The R3xx was 1 op (unimpeded by tex op) + 1 limited op, wasn't it? Or, for clearer connection to subsequent "inflating", 1 op + 1 limited op + 1 tex op.
Neither figure counting coissue or vector component "inflation" counting.
From the discussion here (I missed the chart):
The NV40 looks like 1 op (impeded by tex op) + 1 (possibly smarter or less limited) limited op?
Using the coissue inflation used by ATI to arrive at 40 ops per clock, that would be 4 ops per pipe * 16, then, for 64 ops per clock? This doesn't compare their coissue dispatch structure, though, which determines likelihood...was the NV40 1+3 OR 2+2, or just 2+2 (EDIT: from Colourless' comment, it is less likely for the first op, and equally likely for the 2nd...which might actually work well with what ops can be done in each case, as isn't a 2 component texture access at the least somewhat reasonable?)
The (useless, except for gigaflop type marketing) vector component inflation is 128 "ops" (more like "values computed") per clock, then?
Any information on precision limitations or their lack for any of this? Was the texture op "impediment" indicated to still be present, or to be newly absent (EDIT: from Colourless' comment, apparently it is still there)? Did I understand incorrectly in some aspect of the above?
About shadows:
Doom 3 results were a staged marketing event, using them for logical support is barely specious, let alone valid. That said, the NV35 at the least seems to have advantages in its UltraShadow, bandwidth, and Doom 3's demands at the time, such that it is quite believable to me that it would lead in no AA/no AF situations with minor (not "nVidia minor") image quality tradeoffs. It is just that we don't have any actual figures that illustrate the impact of this advantage without being masked by an engineered marketing situation with one vendor misrepresented.
The NV3x Ultrashadow outputs 8 stencil elements per clock for NV35 (and NV30 if it was called that), which brought it up to the R3xx capability with 8 pixel pipes.
The NV40's apparent stencil element output of 32 per clock is 4 times both the R3xx and NV30/35.
The NV3x was 1 op (impeded by tex op) + up to 2 limited ops, wasn't it?
The R3xx was 1 op (unimpeded by tex op) + 1 limited op, wasn't it? Or, for clearer connection to subsequent "inflating", 1 op + 1 limited op + 1 tex op.
Neither figure counting coissue or vector component "inflation" counting.
From the discussion here (I missed the chart):
The NV40 looks like 1 op (impeded by tex op) + 1 (possibly smarter or less limited) limited op?
Using the coissue inflation used by ATI to arrive at 40 ops per clock, that would be 4 ops per pipe * 16, then, for 64 ops per clock? This doesn't compare their coissue dispatch structure, though, which determines likelihood...was the NV40 1+3 OR 2+2, or just 2+2 (EDIT: from Colourless' comment, it is less likely for the first op, and equally likely for the 2nd...which might actually work well with what ops can be done in each case, as isn't a 2 component texture access at the least somewhat reasonable?)
The (useless, except for gigaflop type marketing) vector component inflation is 128 "ops" (more like "values computed") per clock, then?
Any information on precision limitations or their lack for any of this? Was the texture op "impediment" indicated to still be present, or to be newly absent (EDIT: from Colourless' comment, apparently it is still there)? Did I understand incorrectly in some aspect of the above?
About shadows:
Doom 3 results were a staged marketing event, using them for logical support is barely specious, let alone valid. That said, the NV35 at the least seems to have advantages in its UltraShadow, bandwidth, and Doom 3's demands at the time, such that it is quite believable to me that it would lead in no AA/no AF situations with minor (not "nVidia minor") image quality tradeoffs. It is just that we don't have any actual figures that illustrate the impact of this advantage without being masked by an engineered marketing situation with one vendor misrepresented.
The NV3x Ultrashadow outputs 8 stencil elements per clock for NV35 (and NV30 if it was called that), which brought it up to the R3xx capability with 8 pixel pipes.
The NV40's apparent stencil element output of 32 per clock is 4 times both the R3xx and NV30/35.
If both shader units could co-issue 3/1 or 2/2 then i would have expected the slide to look something like this:

But it doesn't.
But it doesn't.
I think i'll also add this. What would the required complexity be in order to support 3/1 and 2/2 in the same unit?
Well, firstly you'd have 2 components that always have the same instruction (rg). You'd then have a scaler than can be a different instruction (a). Lastly you'd have another scaler that must have the same instruction as one of the others (b which must be rgb or ra), and that doesn't really make much sense. At least not to me. If you are going to the trouble to unlink blue from both RG and A, why not let it execute it's own instruction instead of requiring that it must use on of the other's instruction. You would have a 2 component vector unit and 2 scaler units.
Well, firstly you'd have 2 components that always have the same instruction (rg). You'd then have a scaler than can be a different instruction (a). Lastly you'd have another scaler that must have the same instruction as one of the others (b which must be rgb or ra), and that doesn't really make much sense. At least not to me. If you are going to the trouble to unlink blue from both RG and A, why not let it execute it's own instruction instead of requiring that it must use on of the other's instruction. You would have a 2 component vector unit and 2 scaler units.
Joe DeFuria
Legend
Original

Colourless'
I know what you're saying Colourless, but this wouldn't be the first time that a marketing slide disn't eaxctly convey how things are in reality. Not saying you're wrong, just that the fact that a marketing slide could have been better, doesn't make you right.
Colourless'
I know what you're saying Colourless, but this wouldn't be the first time that a marketing slide disn't eaxctly convey how things are in reality. Not saying you're wrong, just that the fact that a marketing slide could have been better, doesn't make you right.
Similar threads
- Replies
- 25
- Views
- 3K
- Replies
- 16
- Views
- 1K