
Interesting. For several tests the perf/MHz looks about the same. My bet is that only minor changes were made at the core level, at best, and that other improvements came in the uncore (more L3 cache, lower latency L3, lower latency main RAM, more parallelism in the memory controller, etc) and improved ability to sustain clock speeds under dual-core loads.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Apple A8 and A8X
- Thread starter ltcommander.data
- Start date
Some of the integer and FP tests show a >20% improvement.Interesting. For several tests the perf/MHz looks about the same. My bet is that only minor changes were made at the core level, at best, and that other improvements came in the uncore (more L3 cache, lower latency L3, lower latency main RAM, more parallelism in the memory controller, etc) and improved ability to sustain clock speeds under dual-core loads.
4th column is 3rd/2nd*100, 5th is 4th*1.3/1.4.
Code:
Integer 1448 1673 115.54 107.29
Integer Multicore 2807 3281 116.89 108.54
AES 963 1136 117.96 109.54
AES Multicore 1908 2247 117.77 109.36
Twofish 988 1026 103.85 96.43
Twofish Multicore 1955 2060 105.37 97.84
SHA1 4393 4550 103.57 96.18
SHA1 Multicore 8621 9097 105.52 97.98
SHA2 2366 2538 107.27 99.61
SHA2 Multicore 4700 5053 107.51 99.83
BZip2 Compress 1097 1282 116.86 108.52
BZip2 Compress Multicor 2155 2530 117.40 109.02
BZip2 Decompress 1394 1543 110.69 102.78
BZip2 Decompress Multic 2738 3038 110.96 103.03
JPEG Compress 1187 1342 113.06 104.98
JPEG Compress Multicore 2302 2719 118.11 109.68
JPEG Decompress 1569 1837 117.08 108.72
JPEG Decompress Multico 3051 3589 117.63 109.23
PNG Compress 1416 1565 110.52 102.63
PNG Compress Multicore 2760 3144 113.91 105.78
PNG Decompress 1300 1503 115.62 107.36
PNG Decompress Multicor 2485 2943 118.43 109.97
Sobel 1539 1946 126.45 117.41
Sobel Multicore 2983 3782 126.79 117.73
Lua 1361 1787 131.30 121.92
Lua Multicore 2698 3454 128.02 118.88
Dijkstra 1137 1507 132.54 123.07
Dijkstra Multicore 1946 2651 136.23 126.50
Code:
Floating Point 1335 1569 117.53 109.13
Floating Point Multicor 2619 3095 118.17 109.73
BlackScholes 1311 1769 134.94 125.30
BlackScholes Multicore 2589 3466 133.87 124.31
Mandelbrot 897 1144 127.54 118.43
Mandelbrot Multicore 1787 2282 127.70 118.58
Sharpen Filter 1145 1317 115.02 106.81
Sharpen Filter Multicor 2187 2621 119.84 111.28
Blur Filter 1316 1453 110.41 102.52
Blur Filter Multicore 2504 2913 116.33 108.02
SGEMM 1193 1338 112.15 104.14
SGEMM Multicore 2331 2620 112.40 104.37
DGEMM 1118 1256 112.34 104.32
DGEMM Multicore 2203 2460 111.67 103.69
SFFT 1503 1670 111.11 103.17
SFFT Multicore 2972 3265 109.86 102.01
DFFT 1614 1831 113.44 105.34
DFFT Multicore 3189 3542 111.07 103.14
N-Body 1588 1969 123.99 115.14
N-Body Multicore 3158 3902 123.56 114.73
Ray Trace 1975 2313 117.11 108.75
Ray Trace Multicore 3904 4592 117.62 109.22
Code:
Memory 1441 1651 114.57 106.39
Memory Multicore 1753 1849 105.48 97.94
Stream Copy 2083 2485 119.30 110.78
Stream Copy Multicore 2374 2478 104.38 96.93
Stream Scale 1295 1490 115.06 106.84
Stream Scale Multicore 1587 1681 105.92 98.36
Stream Add 1249 1395 111.69 103.71
Stream Add Multicore 1562 1652 105.76 98.21
Stream Triad 1282 1441 112.40 104.37
Stream Triad Multicore 1607 1700 105.79 98.23I still can't agree with some of the sentiment here and from Ryan Smith that a GX6650 at a similar clock to A7's GPU would result in only a 50% performance increase nor that said configuration would score only around 20 fps in GfxBench 3.0 Manhattan offscreen. I am expecting a score in that range, though, from the A8, so I'm guessing Apple saved the die area and didn't pick a GX6650 for iPhone 6.
That's subject to the frequency of the GPU itself; any former estimates were with a lower frequency than for the A7 GPU (at 400MHz 18-21fps makes a difference of up to 60% with a by over 10% lower frequency). Unfortunately there's not enough data so far available for Rogues with and without low power ALUs. I can't access the Kishonti database right now, but if memory serves well a G6230 (600MHz/A80) scores in Manhattan around 15% higher than a G6200 (600MHz/MT6595), meaning that if frequencies here aren't wrong the FP16 ALUs don't seem to bring any big increases at least in a synthetic benchmark like GFXbench (***edit: now that it's working again, forget it the provided data doesn't help to draw any conclusion...in real devices the 6595 turns out even slightly faster than the A80....)
The first thing I'm curious about, is whether iOS 8.x carries any GPU drivers with performance improvements; there's been only one faster performing driver from the advent of Gfxbench3.0 which gave the A7 a boost from 11 to 13 fps.
Some of the integer and FP tests show a >20% improvement
True, but the CPU clock operating frequency doesn't necessarily stay fixed at 1.3GHz and 1.4GHz on iPhone 5S and iPhone 6, respectively, either. These specified frequencies are the minimum CPU clock operating frequencies that one would see for most CPU or browser benchmarks, not the maximum frequencies attained. See frequencies over the first 120 seconds in the chart below (note that the throttling beyond 120 seconds is largely academic because most CPU or browser benchmarks will not run that long in the first place):
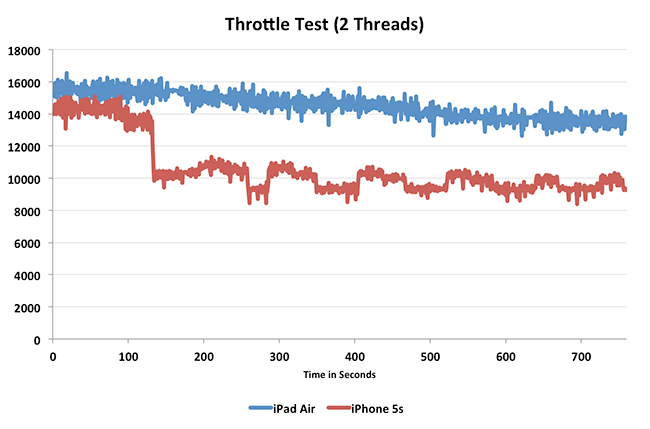
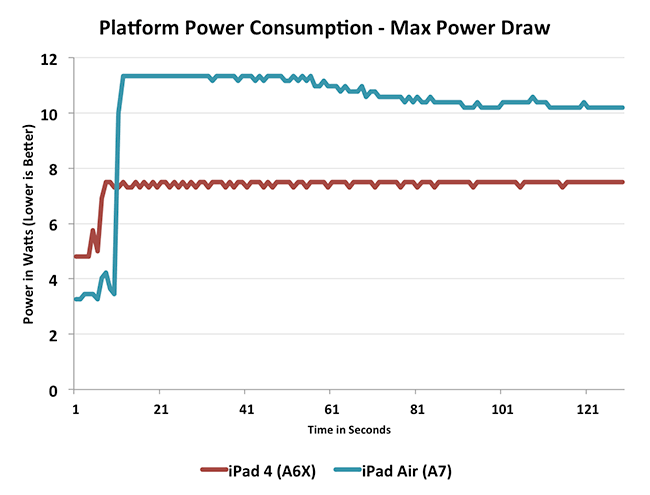
Note that the wide OoO Cyclone CPU cores in the A7 SoC are so power hungry to begin with (even relative to the Swift CPU cores in the A6X SoC) that Apple was only able to marginally boost CPU performance in the A8 SoC:
Last edited by a moderator:
Redo my comparison against iPad Air which doesn't seem to throttle as much and you'll see the improvements still holdTrue, but the CPU clock operating frequency doesn't necessarily stay fixed at 1.3GHz and 1.4GHz on iPhone 5S and iPhone 6, respectively, either. These specified frequencies are the minimum CPU clock operating frequencies that one would see for most CPU or browser benchmarks, not the maximum frequencies attained. See frequencies over the first 120 seconds in the chart below (note that the throttling beyond 120 seconds is largely academic because most CPU or browser benchmarks will not run that long in the first place):
")
http://browser.primatelabs.com/geekbench3/compare/805644?baseline=800566
Redo my comparison against iPad Air which doesn't seem to throttle as much and you'll see the improvements still hold
http://browser.primatelabs.com/geekbench3/compare/805644?baseline=800566
Again, 1.3GHz (for iPhone 5S) and 1.4GHz (for iPad Air and iPhone 6) is only the minimum CPU clock operating frequency attained in the CPU or browser benchmarks, not the average or peak CPU clock operating frequencies attained. More likely than not, the CPU in A8 is able to achieve slightly higher average and peak CPU clock operating frequencies compared to any A7 CPU variant while consuming the same or slightly less power overall due to the improved fab process.
And FWIW, there is very little difference in the Geekbench scores posted earlier for the iPhone 5S vs. the iPad Air scores posted above.
Last edited by a moderator:
To the best of my knowledge it has never been proven that A7 frequency goes higher than the 1.3/1.4 GHz mentioned. Did I miss that information?Again, 1.3GHz (for iPhone 5S) and 1.4GHz (for iPad Air and iPhone 6) is only the minimum CPU clock operating frequency attained in the CPU or browser benchmarks, not the average or peak CPU clock operating frequencies attained. More likely than not, due to the improved fab process, the CPU in A8 is able to achieve slightly higher average and peak CPU clock operating frequencies compared to any A7 CPU variant while consuming the same or slightly less power.
And if your hypothesis was correct the speedup would be more regular than it is across the Geekbench benchmarks. I'm pretty convinced Apple changed a few things in the micro-architecture.
To the best of my knowledge it has never been proven that A7 frequency goes higher than the 1.3/1.4 GHz mentioned. Did I miss that information?
See the y-axis in the "Throttle Test" graph that Anand created above.
And if your hypothesis was correct the speedup would be more regular than it is across the Geekbench benchmarks. I'm pretty convinced Apple changed a few things in the micro-architecture.
Virtually all the Geekbench 3 individual line items see a slight increase in CPU performance for A8 vs. A7, which seems to imply that actual attained average and peak CPU clock operating frequencies are slightly higher for A8 vs. A7 too, and any CPU architectural tweaks appear to be minor at best (which makes some sense given the risk in moving so quickly to to a brand new fab process node).
See the y-axis in the "Throttle Test" graph that Anand created above.
The y-axis is likely just a performance number, not the clock rate. In the article (http://www.anandtech.com/show/7460/apple-ipad-air-review/3):
AnandTech said:By the end of the test the iPhone 5s has throttled to 900MHz, while the iPad Air drops to around 1.2GHz. At this point the iPad Air’s performance advantage grows to almost 40%.
But you can see that in the graph iPad Air dropped to ~13,500 at the end, compared to ~15,500 at the start. It's likely that Anand derived the 1.2GHz number from the relative performance from the full 1.4GHz at the start (1.4/15500 * 13500 ~= 1.2).
The y-axis is likely just a performance number, not the clock rate.
No, it actually is the CPU clock operating frequency. Note that Anand's test is an in-house test to determine throttling of frequencies over time, so a raw benchmark score would have no meaning here.
Note that the minimum frequencies charted over time in the graph's y-axis are close to 1.2GHz and 0.9GHz as mentioned casually in the article, and the in-house test data does not necessarily end at 750 seconds either even if the graph does.
And looking back at the article, Anand says that "the 5s throttles back it's CPU frequency to about 1GHz after the two minute mark", which is exactly what is shown in the graph for y and x-axes.
Last edited by a moderator:
Anandtech's study of the Cyclone cores in A7 found that it apparently had the ability to be configured for keeping significantly more instructions in flight in the iPad Air versus the iPhone's implementation. I wonder if Apple really needed to do much architectural enhancement to the CPU core itself for A8 to get the extra performance beyond the clock uptick.
Some of the graphics benchmarks after updating prior devices to iOS 8 seem to suggest that the new OS incurs some heavier overhead but also features subtly better drivers leading to some small performance improvements (and a few degradations) across various GPU benchmarks.
About the performance improvement that a G6x30 core delivers above a G6x00 GPU, I calculated it a while back using Intel's numbers from Moorefield versus Merrifield, in an attempt to reduce obscuring variables like different vendors' SoC and software/driver implementations. I don't remember exactly what I determined, but I don't think I remember it being much higher than a 15% improvement if it even reached quite that much.
Some of the graphics benchmarks after updating prior devices to iOS 8 seem to suggest that the new OS incurs some heavier overhead but also features subtly better drivers leading to some small performance improvements (and a few degradations) across various GPU benchmarks.
About the performance improvement that a G6x30 core delivers above a G6x00 GPU, I calculated it a while back using Intel's numbers from Moorefield versus Merrifield, in an attempt to reduce obscuring variables like different vendors' SoC and software/driver implementations. I don't remember exactly what I determined, but I don't think I remember it being much higher than a 15% improvement if it even reached quite that much.
ltcommander.data
Regular
http://arstechnica.com/apple/2014/09/ios-8-thoroughly-reviewed/11/The first thing I'm curious about, is whether iOS 8.x carries any GPU drivers with performance improvements; there's been only one faster performing driver from the advent of Gfxbench3.0 which gave the A7 a boost from 11 to 13 fps.
Ars Technica found about a 9% boost on T-Rex offscreen, but not much change on Manhattan offscreen on the A7 between iOS 8 and 7.1.2 so the drivers aren't likely playing a big role.
No, it actually is the CPU clock operating frequency. Note that Anand's test is an in-house test to determine throttling of frequencies over time, so a raw benchmark score would have no meaning here.
If it's actually the clock rate, don't you think it's weird that the unit of y-axis is not MHz or GHz, but 100kHz? And Anand never mentioned anything about iPad Air being able to boost to near 1.6GHz. I think that's something very worth mentioning since this information is not available anywhere else.
Also, I have done some tests with my iPad Air when I saw Anand's claim that A7 is a 6-way machine. I haven't been able to get anything more than 1.4G x 4 with integer instructions or 1.4G x 6 with integers+floating point instructions, even in tests lasting much less than 2 minutes. If iPad Air is able to "boost" to 1.6GHz, that wouldn't be the case.
Nebuchadnezzar
Legend
The A7 does not go over 1.3/1.4GHz and that y-axis is not frequency but a performance value for the stress test.
Some of the integer and FP tests show a >20% improvement.
Yes, but nothing that rules out anything I posted about, IMO. But it depends on one's definition of minor changes. I'd consider SB to IB, for example, to include minor changes, and you could see almost as large improvements in some tests there. I guess we'll see what the GCC configuration files say, but that's about it.. we'll probably never really learn what they changed. Testing is going to have to go far beyond what's been done so far to really start to characterize uarch design..
It'd be nice if someone ran some performance counters during Geekbench tests to get a better idea of what the tests are doing. I'd be curious as to which tests are easily memory bandwidth limited for a lot of the time (with decent prefetchers) vs ones that have a lot of random accesses that don't hit cache/don't prefetch well. The memory tests seem to show that total bandwidth available to both cores has only improved very modestly, while individual bandwidth to a core in isolation has improved more.
The A7 does not go over 1.3/1.4GHz and that y-axis is not frequency but a performance value for the stress test.
Fair enough, I stand corrected. Still, the shape of the graph would be virtually the same if frequency was used for the y-axis, because performance is directly affected by frequency. And what the graph appears to show is that CPU clock operating frequency fluctuates on A7 even in the first two minutes of the "throttle test" run.
The difference between peak performance and trough performance for the A7 SoC in the first two minutes of the "throttle test" run is at least 10-15%. So if the A8 SoC can maintain performance closer to peak than the A7 SoC throughout a given benchmark (which it should be able to do at the same or lower power consumed given the more advanced fab process node), then that should explain in part why the CPU benchmark scores are a bit higher across the board in comparison. Note that the Geekbench 3 Single Core and Multi-Core overall score is only ~ 15% higher on iPhone 6 than on iPhone 5s.
Last edited by a moderator:
Definitely, I just wanted to provide dataYes, but nothing that rules out anything I posted about, IMO.
I guess you meant LLVM, not GCC.But it depends on one's definition of minor changes. I'd consider SB to IB, for example, to include minor changes, and you could see almost as large improvements in some tests there. I guess we'll see what the GCC configuration files say, but that's about it.. we'll probably never really learn what they changed. Testing is going to have to go far beyond what's been done so far to really start to characterize uarch design..
I guess you meant LLVM, not GCC.
Yes, oops. I was confusing it with the GCC pipeline description files that give some hints on ARM uarchs (Cortex-A7, etc)
ltcommander.data
Regular
https://www.ifixit.com/Teardown/iPhone+6+Plus+Teardown/29206
iFixit iPhone 6 Plus teardown underway.
https://d3nevzfk7ii3be.cloudfront.ne...JUSleWNZGkYX5P
http://www.micron.com/products/dram/...fullPart&306=2
Ram looks like 1GB LPDDR3-1600 this time by Micron (F8164A3PM-GD-F) consistent with leaks.
iFixit iPhone 6 Plus teardown underway.
https://d3nevzfk7ii3be.cloudfront.ne...JUSleWNZGkYX5P
http://www.micron.com/products/dram/...fullPart&306=2
Ram looks like 1GB LPDDR3-1600 this time by Micron (F8164A3PM-GD-F) consistent with leaks.
Similar threads
- Replies
- 6
- Views
- 2K
- Replies
- 42
- Views
- 35K
- Replies
- 52
- Views
- 23K
- Replies
- 126
- Views
- 45K