Not that I know of. I have nothing omitted, except the mentioned redundant texture fillrate tests.
.
Thank you for the Info.
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
Not that I know of. I have nothing omitted, except the mentioned redundant texture fillrate tests.
.
Yeah, been a while since I've seen filtering performance broken down, but supposedly new architecture so could be interesting.Alas, that's a rather ancient OpenGL Test. Will see if I can run it tomorrow in the office. But IIRC the results have been... strange for a couple of other cards a few years back, so I stopped using it on a regular basis. I still don't see, however, how I can correlate certain filtering modes to ALUs. Except the results between filtering modes differ wildly from the one in Fiji/Polaris - which the ones tested with the modern B3D suite do not indicate.
Fragments not rasterised save ALU, TEX and ROP.But that doesn't hold for the texture units. AFAIK, there are no tiler consequences there.
What if Vega doesn't have TMUs? With the 2xFP16(INT16?) and 4xINT8 they could be filtering with the shader cores. Then lower bandwidth and/or register pressure slowing things down. With everything seemingly programmable that makes sense. Could apply to ROPs as well. Still leaves the question of what's taking up all the space.
How would tiling help with a low level micro-benchmark that only tests texture bandwidth?Fragments not rasterized save ALU, TEX and ROP.
Worrying thought: you know how Ryzen performance has some dependence on the memory clock, because infinity fabric clock and memory clock are linearly related? Well, what if infinity fabric in Vega is related to HBM clock and ...
Worrying thought: you know how Ryzen performance has some dependence on the memory clock, because infinity fabric clock and memory clock are linearly related? Well, what if infinity fabric in Vega is related to HBM clock and ...
I would think so, hence all the unexplained space. The alternative might be the ability to issue multiple vector instructions simultaneously or the FLOPs are a bit misleading. I had a theory on dual FMAs per lane using SMT that would probably require L0 cache to make work. Doubles or possibly quadruples flops under ideal conditions.Wouldn't that immediately warrant an increase in ALU/NCU amount compared to Fiji, given the performance target?
I had the same thought a while back, but we're seeing benchmarks at 1050 and 1100MHz with 8-Hi stacks. So unless HBM2 is far faster than anyone knew, they should have been able to design around it. Ryzen memory clocks were low initially, Vega FE looks to be ahead of the curve.Worrying thought: you know how Ryzen performance has some dependence on the memory clock, because infinity fabric clock and memory clock are linearly related? Well, what if infinity fabric in Vega is related to HBM clock and ...
I'd Like to think thousands of engineers are AMD are not that stupid.
What is this supposed to mean?If they were merely that stupid, Vega would have better bandwidth numbers for 3 of the 4 memory test cases.
If it were merely a matter of the data fabric being tied the speed of the memory controller, the bandwidth should be higher.What is this supposed to mean?
Radeon RX Vega is on its way—but before that, we’re bringing it to you. We’re making a few stops to show it off in action: we’re packing up a few Radeon RX Vega GPUs and embarking on a mini community tour, and we’re hoping you join us!
At our stops, we’re setting up a Radeon RX Vega Experience area where you’ll be able to game on the upcoming graphics card and take in the experience, tradeshow-style.
Would those be pre-launch-post-pre-launches?
Would those be pre-launch-post-pre-launches?
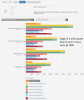
Do note that (while I haven't seen what the B3D test actually does):1 - Texel fillrate (per TMU per clock) is pretty terrible compared to Polaris and even Fiji (maybe connected to new ROPs as L2 cache clients?)
2 - Effective bandwidth is actually lower than Fiji