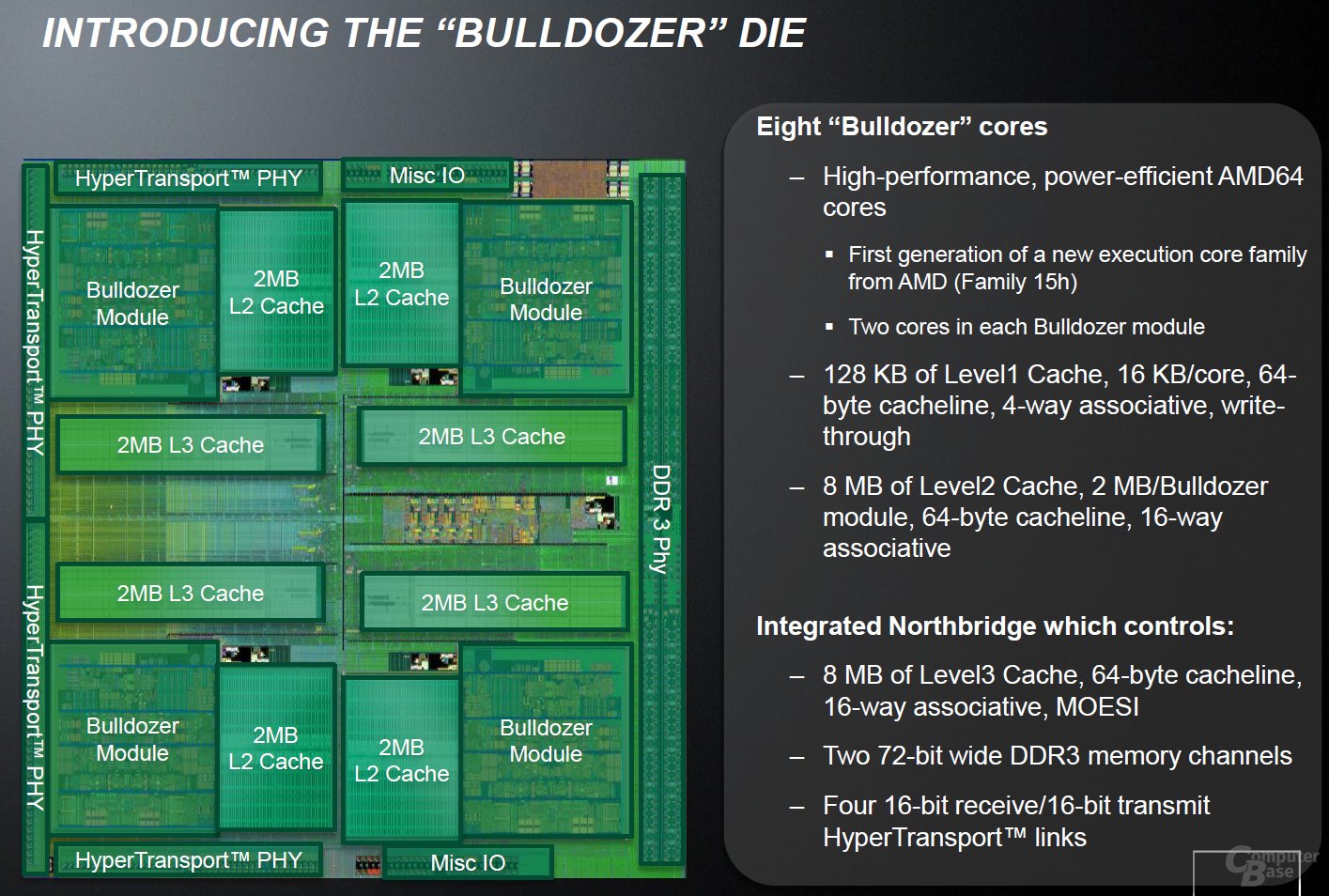
The team that did all the great design work for Athlon 64/Opteron is gone. Forced out or quit in disgust. They now work at Apple, Oracle, misc. startups, and, in my case, changed careers.
...The team that designed the K6-2 was the CMD team, which was formed by the acquisition of a company called Nexgen. That team also designed Athlon 64 and Opteron (Athlon was designed by the TMD team). By 2007, all the key CMD folks were gone. The team that was left sucks, and has accomplished little since then other than shrinks to smaller technology and bolting more of the same cores on
....Yeah. Like replacing the 40-man team that designed A64 with a 250 man team for minor design changes. And like throwing away all the EDA tools because the vapor tools from the texas design team would be better if they ever were finished....
The new CEO [Dirk Meyer] is a guy that once told the design team (when he was a manager in Texas) "if you don't like it, quit" - and 60 out of 100 people in Sunnyvale quit within a month. They used to hand place and hand instantiate each cell in the design for maximum efficiency and speed - now they rely on tools which perform 20% worse than humans (in order to save money). ..
.
Guys - I have nothing to be disgruntled about. I left on my own accord. I had great times at AMD making a64 and creating amd64. AMD paid me enough to pay for a house in silicon valley and a porsche. I quit on my own and was not pressured to do so. They were sad to see me go, and i was sad to leave
...
I am not disgruntled. I am sad. Sad that AMD squandered their lead because new management decided that the way to compete was design CPUs the way that chips in toasters are designed. And worse, to do it with giant teams of unskilled designers instead of a small team of highly experienced engineers who know how to design transistor by transistor. ....
And the biggie on how Hector's Fusion strategy stabbed the remaining carcass:
.What did happen is that management decided there SHOULD BE such cross-engineering ,which meant we had to stop hand-crafting our CPU designs and switch to an SoC design style. This results in giving up a lot of performance, chip area, and efficiency. The reason DEC Alphas were always much faster than anything else is they designed each transistor by hand. Intel and AMD had always done so at least for the critical parts of the chip. That changed before I left - they started to rely on synthesis tools, automatic place and route tools, etc. I had been in charge of our design flow in the years before I left, and I had tested these tools by asking the companies who sold them to design blocks (adders, multipliers, etc.) using their tools. I let them take as long as they wanted. They always came back to me with designs that were 20% bigger, and 20% slower than our hand-crafted designs, and which suffered from electromigration and other problems.
That is now how AMD designs chips. I'm sure it will turn out well for them [/sarcasm]