You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AI Co-Processors: could this be the best thing to happen to gaming since the GPU?
- Thread starter onQ
- Start date

Are you sure they're not just referring to Compute Units used for Physics and AI?
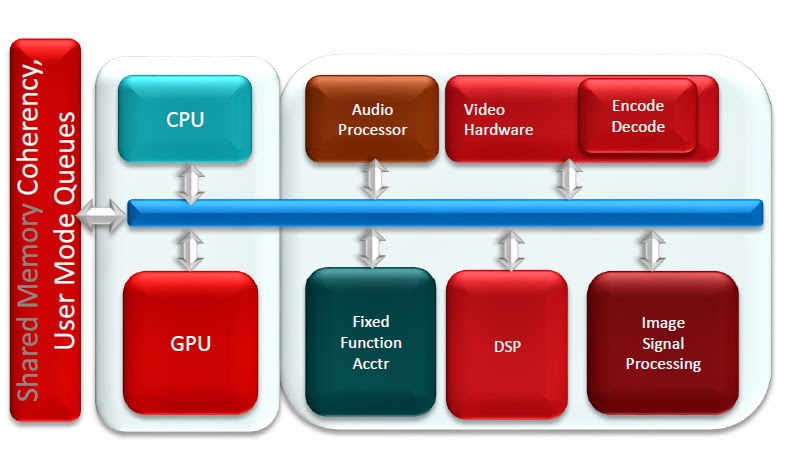
Maybe but one of the key features of HSA is being about to add DSP's & Fixed Function Accelerators to the SoC so that the hardware that's best suited for each task can do most of the work & take the load off of the CPU & GPU.
Perhaps they include a brain in each chip 
Seriously though, I don't even know what an AI chip would be. Perhaps something to speed up search? Though that is more a memory thing.
I suppose you could create a SANE black box to learn all the players nuances across all the different games they play. That way you could provide a system level custom made AI solution that could be just plugged into games that need it.
Or maybe they just mean giving up some compute time to search?
Seriously though, I don't even know what an AI chip would be. Perhaps something to speed up search? Though that is more a memory thing.
I suppose you could create a SANE black box to learn all the players nuances across all the different games they play. That way you could provide a system level custom made AI solution that could be just plugged into games that need it.
Or maybe they just mean giving up some compute time to search?
D
Deleted member 13524
Guest
There were video demos for a dedicated AI processor that was thought to be used for games.
This was not long after the AGEIA PhysX cards came into market.
It was supposedly coming from from a company named AIseek and the co-processor was called "Intia" (I guess an acronym for Intelligent IA).
As anyone can guess, it didn't really lift of, since even the company's website was discarded.
I think the only thing that shows in that demo is dynamic path finding, which eventually was done through GPGPU in AMD's Froblins demo for the RV700 family.
Again, it never appeared in a game AFAIK. Maybe because this would only be good for RTS games with huge unit counts.. which is pretty much an extinct genre.
Nonetheless, I don't know if path finding alone could be called an AI co-processor.. and I'm not even sure what could deserve such a name...
AI isn't just path-finding... It's decision-making based on environmental factors, adaptation capabilities, etc. AFAIK most of that research is being done in robot football, not games.
What is the thing we have that can better emulate an enormous amount of neurons and synapses in hardware? A very large and very fast FPGA?
This was not long after the AGEIA PhysX cards came into market.
It was supposedly coming from from a company named AIseek and the co-processor was called "Intia" (I guess an acronym for Intelligent IA).
As anyone can guess, it didn't really lift of, since even the company's website was discarded.
I think the only thing that shows in that demo is dynamic path finding, which eventually was done through GPGPU in AMD's Froblins demo for the RV700 family.
Again, it never appeared in a game AFAIK. Maybe because this would only be good for RTS games with huge unit counts.. which is pretty much an extinct genre.
Nonetheless, I don't know if path finding alone could be called an AI co-processor.. and I'm not even sure what could deserve such a name...
AI isn't just path-finding... It's decision-making based on environmental factors, adaptation capabilities, etc. AFAIK most of that research is being done in robot football, not games.
What is the thing we have that can better emulate an enormous amount of neurons and synapses in hardware? A very large and very fast FPGA?
Last edited by a moderator:
I don't understand the point of an AI coprocessor. Eventually you'd have so many functional units there'd be nothing for the CPU to do! Id on't think anything can be better suited to conventional AI than a decent CPU with excellent branch and memory handling. The only reason for specialist silicon I can see is to implement something exotic like neural nets at a hardware level, which is beyond the scope of CE device. Plenty of CPU power is all that's needed to enable great AI - that and decent algorithms.
Actually, that's true. Pathfinding is pretty brute-force solution at the moment. I don't think its acceleration via GPU is particular efficient.Dedicated logic for pathfinding...
I would think that collision detection is precisely in the realm of raycasting, which the SPEs were already good at, and which modern GPUs should be even better at. Resogun shows this amply.
So personally, no, I'm not yet buying it. Physics and AI Co-Processor screams 'this is what we mainly use CUs for' ...
So personally, no, I'm not yet buying it. Physics and AI Co-Processor screams 'this is what we mainly use CUs for' ...
I don't understand the point of an AI coprocessor. Eventually you'd have so many functional units there'd be nothing for the CPU to do! Id on't think anything can be better suited to conventional AI than a decent CPU with excellent branch and memory handling. The only reason for specialist silicon I can see is to implement something exotic like neural nets at a hardware level, which is beyond the scope of CE device. Plenty of CPU power is all that's needed to enable great AI - that and decent algorithms.
The CPU & GPGPU will be creating the tasks that the fixed function hardware will be handling. This is the point of the Heterogeneous System Architecture.
Think of the SoC as "The Cell" , the CPU (& also the programmable part of the GPGPU ) is the PPE handing off the work to the SPE's but the difference is that the "SPE's" are now actually hardware built to handle these functions.
Remember my Voltron statement I'm not as crazy as some of you try to make me out to be.
PS. I think you locked a important thread lately.
There is only an actual win in a coprocessor if actually doing the work is more expensive than packaging up the requests and sending them off to the coprocessor and unpacking the results when they come back.
The issue with things like ray or volume casting for AI is that a lot of code is conditional, so you dependently cast additional rays or volumes, the latency of a coprocessor in those cases becomes a killer.
The issue with things like ray or volume casting for AI is that a lot of code is conditional, so you dependently cast additional rays or volumes, the latency of a coprocessor in those cases becomes a killer.
AI is more developer limited than processor limited (ie. for better AI, write more scripts).
...and may be more variety in animation and facial expression so the AI can show different states visually.
There is only an actual win in a coprocessor if actually doing the work is more expensive than packaging up the requests and sending them off to the coprocessor and unpacking the results when they come back.
The issue with things like ray or volume casting for AI is that a lot of code is conditional, so you dependently cast additional rays or volumes, the latency of a coprocessor in those cases becomes a killer.
Who says that you have to package , send off & unpack the data?

Who says that you have to package , send off & unpack the data?
Not really talking about the same sort of packaging, you'll need to put the data in some form that is useful to the accelerator, and do something with the result. This could be trivial, but it's not free.
As an example In the case of Raycasting, you may need to share some scene description with both the accelerator and the CPU, which may be suboptimal for the CPU, or duplicate the data for both. If the compute model is fundamentally different it's doubtful the same data would be optimal for both.
Just not sure AI is really all that limited by CPU cycles today. Some sort of collision accelerator might help. but I'm not even sure that's true.
Not really talking about the same sort of packaging, you'll need to put the data in some form that is useful to the accelerator, and do something with the result. This could be trivial, but it's not free.
As an example In the case of Raycasting, you may need to share some scene description with both the accelerator and the CPU, which may be suboptimal for the CPU, or duplicate the data for both. If the compute model is fundamentally different it's doubtful the same data would be optimal for both.
Just not sure AI is really all that limited by CPU cycles today. Some sort of collision accelerator might help. but I'm not even sure that's true.
What if the fixed function accelerator isn't actually a fixed function piece of hardware but a co processor that's able to handle a few different fixed function pipelines but sharing the same resource . say A Vector Co-Processor connected to the CPU that's getting different jobs handed off to it from the GPGPU many ALU's.
We have some amazingly powerful CPUs now and they'll only get more powerful. Every bit of custom hardware makes the code more complex and reduces system flexibility (programmable hardware vs fixed function). CPUs have been designed around handling branchy, memory searching designs, ideal for AI processors. So why leave the CPU with no work to do and put in dedicated AI silicon that can't do anything else? Why not just use a CPU that you can turn to any task? You'd need to prove that the AI requirements are beyond the CPU's abilities.The CPU & GPGPU will be creating the tasks that the fixed function hardware will be handling. This is the point of the Heterogeneous System Architecture.
...And the 'PPE' in HSA is a very capable piece of hardware and not an anaemic sloth like Cell's PPE. PPE had to hand work off to the SPEs because it wasn't fast enough to do it itself. The CPU in HSA is fast enough, generally, depending on what workloads. And with physics on the GPU and sound on the DSP, you have less and less work for the CPU to do.Think of the SoC as "The Cell" , the CPU (& also the programmable part of the GPGPU ) is the PPE handing off the work to the SPE's but the difference is that the "SPE's" are now actually hardware built to handle these functions.
Be careful with terminology as that's where silly arguments crop up. Don't use a term assuming other people are interpreting it how you mean it. eg. By co-processor, do you mean discrete silicon on a bus connected to the CPU, or do you mean a functional block in the CPU like an FPU? Just take a moment to add a clear description of what you are suggesting. eg.What if the fixed function accelerator isn't actually a fixed function piece of hardware but a co processor that's able to handle a few different fixed function pipelines but sharing the same resource . say A Vector Co-Processor connected to the CPU that's getting different jobs handed off to it from the GPGPU many ALU's.
say A Vector Co-Processor connected to the CPU (functional block in the CPU) that's getting different jobs handed off to it from the GPGPU many ALU's.
We have some amazingly powerful CPUs now and they'll only get more powerful. Every bit of custom hardware makes the code more complex and reduces system flexibility (programmable hardware vs fixed function). CPUs have been designed around handling branchy, memory searching designs, ideal for AI processors. So why leave the CPU with no work to do and put in dedicated AI silicon that can't do anything else? Why not just use a CPU that you can turn to any task? You'd need to prove that the AI requirements are beyond the CPU's abilities.
...And the 'PPE' in HSA is a very capable piece of hardware and not an anaemic sloth like Cell's PPE. PPE had to hand work off to the SPEs because it wasn't fast enough to do it itself. The CPU in HSA is fast enough, generally, depending on what workloads. And with physics on the GPU and sound on the DSP, you have less and less work for the CPU to do.
Be careful with terminology as that's where silly arguments crop up. Don't use a term assuming other people are interpreting it how you mean it. eg. By co-processor, do you mean discrete silicon on a bus connected to the CPU, or do you mean a functional block in the CPU like an FPU? Just take a moment to add a clear description of what you are suggesting. eg.
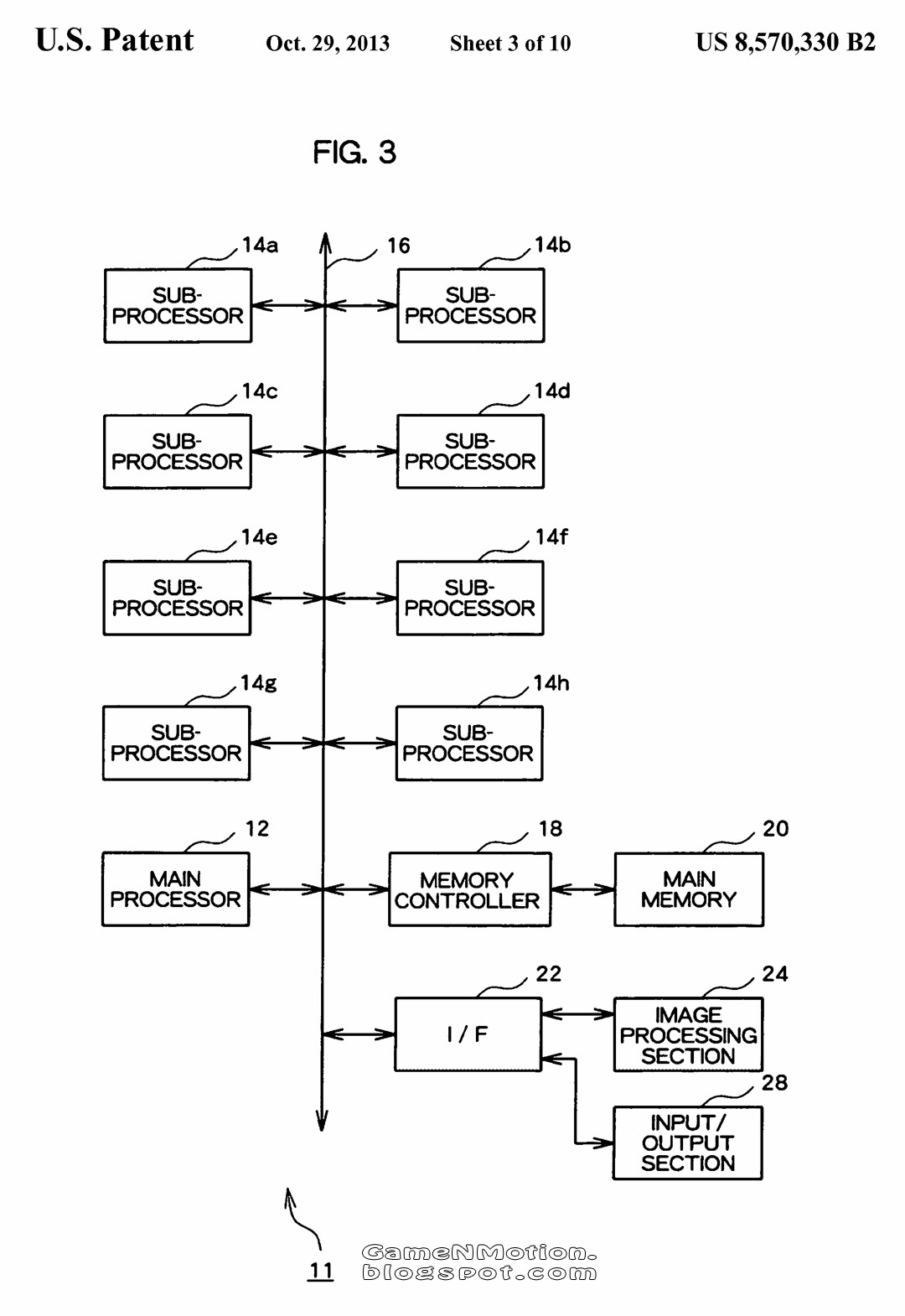
I mean 8 Sub-Processors (Vector Units? ) connected to the CPU.
Last edited by a moderator:
I mean 8 Sub-Processors (Vector Units? ) connected to the CPU.
Like Cell? How is this patent related to the PS4. Its a diagram for the PS3.
Similar threads
- Locked
- Replies
- 27
- Views
- 3K
- Replies
- 52
- Views
- 6K
- Replies
- 175
- Views
- 12K