I've a couple of "honest" questions. Some here are real software developers as Nick others seems to know their fair share either about hardware/micro-electronic and software, I'm just a geek, so no offence ")
First in regard to the comparison between SwiftShader and intel HD3000.
There's x5 difference in the 3D mark06 score. OK.
*What is the cost of running ShiftShader "itself" on the CPU? Is it in the same ball park as running the HD3000 drivers? Or higher, if yes significantly?
*In regard to power consumption, what is the usual power consumption of a CPU running 3Dmark06 on a discrete GPU? As I think it would be fair to consider the incompressible/fixed CPU cost to run something as 3Dmark.
*Overall can we consider the overall cost (in power and compute power) of swiftshader in the same ballpark as drivers?
*Another thing the HD3000 is not tiny by any mean if this floormap correct, it looks more like equal ~2 cores:
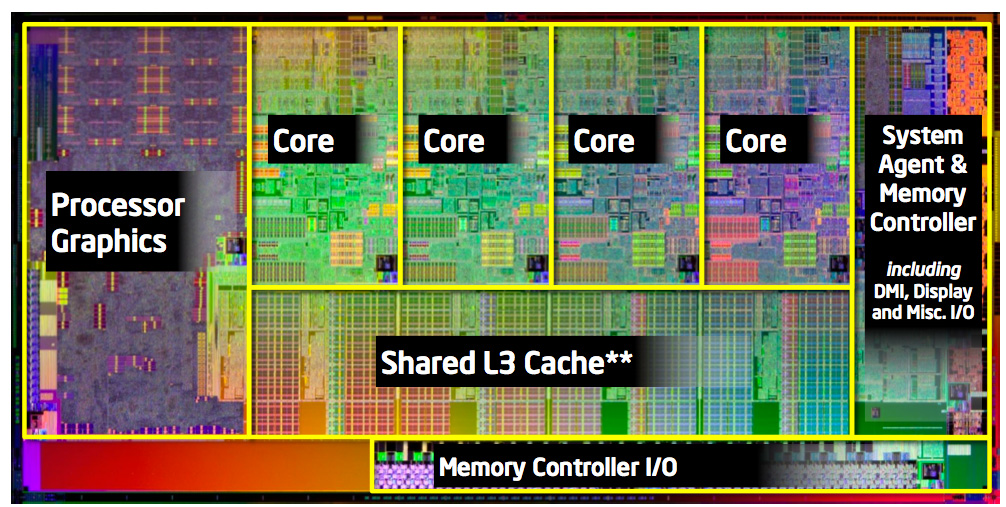
Overall it would be more fair to compare a quadcore to a dual core+IGP. From a costumer POV what serves the most? A quadcore? a dual core+ (shitty anyway)IGP? In regard to power how a HD3000 compares to two SnB cores? I guess that tough to find out. Anyway the IGP is likely way better in perfs per Watts by quiet an healthy margin.
Some questions more specifically aimed at you Nick.
* Is swiftShader optimized for AVX already?
* What are your expectations in regard to for example 3Dmark06 if it were implement if not straight to the metal using various libraries? How close do you think it would come to the IGP/HD3000?
* Say a bench or game were desgin with a CPU as hardware target, how close to think the end result would compare to an IGP (the HD3000 can serve as ref). Say you pass on some calculations and use more complex, bigger datastructures so more precompute values, do sacrifices clever trick elsewhere. Devs could count on 4GB or more of RAM, lot of cache, etc.
Basically do you think that it would be possible achieve for a quad-cores the "same" result as with an IGP+dual cores.
First in regard to the comparison between SwiftShader and intel HD3000.
There's x5 difference in the 3D mark06 score. OK.
*What is the cost of running ShiftShader "itself" on the CPU? Is it in the same ball park as running the HD3000 drivers? Or higher, if yes significantly?
*In regard to power consumption, what is the usual power consumption of a CPU running 3Dmark06 on a discrete GPU? As I think it would be fair to consider the incompressible/fixed CPU cost to run something as 3Dmark.
*Overall can we consider the overall cost (in power and compute power) of swiftshader in the same ballpark as drivers?
*Another thing the HD3000 is not tiny by any mean if this floormap correct, it looks more like equal ~2 cores:
Overall it would be more fair to compare a quadcore to a dual core+IGP. From a costumer POV what serves the most? A quadcore? a dual core+ (shitty anyway)IGP? In regard to power how a HD3000 compares to two SnB cores? I guess that tough to find out. Anyway the IGP is likely way better in perfs per Watts by quiet an healthy margin.
Some questions more specifically aimed at you Nick.
* Is swiftShader optimized for AVX already?
* What are your expectations in regard to for example 3Dmark06 if it were implement if not straight to the metal using various libraries? How close do you think it would come to the IGP/HD3000?
* Say a bench or game were desgin with a CPU as hardware target, how close to think the end result would compare to an IGP (the HD3000 can serve as ref). Say you pass on some calculations and use more complex, bigger datastructures so more precompute values, do sacrifices clever trick elsewhere. Devs could count on 4GB or more of RAM, lot of cache, etc.
Basically do you think that it would be possible achieve for a quad-cores the "same" result as with an IGP+dual cores.
Last edited by a moderator: