A blog post detailing some of the changes in the directx 12 agility sdk. Bunch of these improvements look interesting.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Game development presentations - a useful reference
- Thread starter liolio
- Start date
SDK for Neural Texture Compression released. Contains a bunch of links for more info.

 github.com
github.com
GitHub - NVIDIA-RTX/RTXNTC: NVIDIA Neural Texture Compression SDK
NVIDIA Neural Texture Compression SDK. Contribute to NVIDIA-RTX/RTXNTC development by creating an account on GitHub.
github.com
Render Path-Traced Hair in Real Time with NVIDIA GeForce RTX 50 Series GPUs
New article on ray tracing hair and fur with hardware ray tracing support for the linear swept sphere (LSS) primitive.

 developer.nvidia.com
developer.nvidia.com
New article on NVIDIA RTX Mega Geometry
 developer.nvidia.com
developer.nvidia.com
New blog post on the RTX Neural Kit with links on sample projects for all of the different technologies.
 developer.nvidia.com
developer.nvidia.com
New article on ray tracing hair and fur with hardware ray tracing support for the linear swept sphere (LSS) primitive.
Render Path-Traced Hair in Real Time with NVIDIA GeForce RTX 50 Series GPUs | NVIDIA Technical Blog
Hardware support for ray tracing triangle meshes was introduced as part of NVIDIA RTX in 2018. But ray tracing for hair and fur has remained a compute-intensive problem that has been difficult to…
developer.nvidia.com
New article on NVIDIA RTX Mega Geometry
NVIDIA RTX Mega Geometry Now Available with New Vulkan Samples | NVIDIA Technical Blog
Geometric detail in computer graphics has increased exponentially in the past 30 years. To render high quality assets with higher instance counts and greater triangle density…
developer.nvidia.com
New blog post on the RTX Neural Kit with links on sample projects for all of the different technologies.
Get Started with Neural Rendering Using NVIDIA RTX Kit | NVIDIA Technical Blog
Neural rendering is the next era of computer graphics. By integrating neural networks into the rendering process, we can take dramatic leaps forward in performance, image quality…
developer.nvidia.com
Solving the Dense Geometry Problem
A new article on AMD's Dense Geometry Format (DGF).
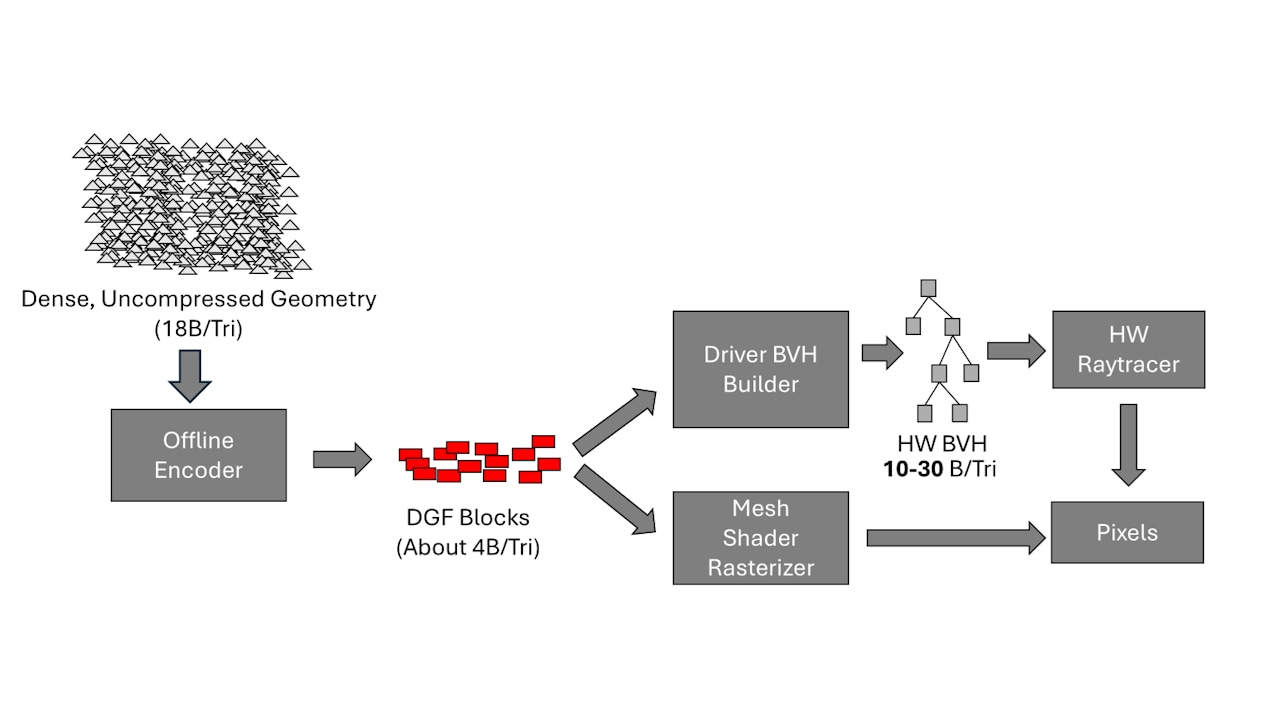
 gpuopen.com
gpuopen.com
A new article on AMD's Dense Geometry Format (DGF).
Solving the Dense Geometry Problem
Discover how AMD's Dense Geometry Compression Format (DGF) revolutionizes graphics by compressing complex models for efficient real-time rendering, bridging the gap between rasterization and ray tracing.
gpuopen.com
raytracingfan
Newcomer
It will be interesting to see how DGF fits with Mega Geometry, if both become standardized by the graphics APIs. They are both used with triangle clusters and could complement each other in theory, although I wonder if the tessellation examples Nvidia is showing up would work with DGF. Also, if Linear Swept Spheres are standardized by the graphics APIs, standardized geometry compression formats like DGF should support them.
Maybe other geometric primitives like bilinear patches will also get HWRT support one day.
New article on ray tracing hair and fur with hardware ray tracing support for the linear swept sphere (LSS) primitive.
Render Path-Traced Hair in Real Time with NVIDIA GeForce RTX 50 Series GPUs | NVIDIA Technical Blog
Hardware support for ray tracing triangle meshes was introduced as part of NVIDIA RTX in 2018. But ray tracing for hair and fur has remained a compute-intensive problem that has been difficult to…
The earlier material published on LSS made it seem as if the radius would be constant, so only pill-shaped capsules could be represented. Varying radii makes LSS significantly more flexible. If future versions of LSS support providing an angle of revolution then semi-capsules, semi-cones, and other partially-revolved capsules and cones could be represented too. That might not provide much value if the LSS is only a few pixels wide as the article says, but neither would varying radii, and Nvidia chose to support that.The LSS primitive is a thick, round 3D line with varying radii. Multiple linear swept spheres can be chained together to build 3D curves, sharing vertices where they overlap, similar to how triangles are used to build 3D surfaces. LSS is shaped like a cylindrical or conical tube with spheres optionally capping either end.
Maybe other geometric primitives like bilinear patches will also get HWRT support one day.
It can be a disk format for clusters. The point of DGF is that it's trivially converted to whatever the silly raytracing APIs desire.It will be interesting to see how DGF fits with Mega Geometry
Honestly I'm a bit disappointed in the second author. After wrangling raytracing in doing it right at Intel, he's now bending over backwards to facilitate raytracing in doing it wrong at AMD.
Last edited:
Not sure if I like the direction of DGF for what it means for broader adoption vs. what NV has seemingly schemed.Solving the Dense Geometry Problem
A new article on AMD's Dense Geometry Format (DGF).
Solving the Dense Geometry Problem
Discover how AMD's Dense Geometry Compression Format (DGF) revolutionizes graphics by compressing complex models for efficient real-time rendering, bridging the gap between rasterization and ray tracing.
One requires a new hardware unit, and one does not. Realistically only AMD will have production on that hardware unit in the mid term so no RDNA1, no RDNA 2, no RDNA 3 (maybe not even RDNA4?), no Turing, no Ampere, no Ada Lovelace, no Blackwell, no Arc, no Battlemage. Where as we have seen Mega Geo at its base already working on RTX 2000 and is not locked into adding a decompression unit to the GPU for this singular purpose.
Competing standards here with one requiring new decompression unit... yeah... not sure that is the way forward.
edit: how does DGF factor into dynamic tessellation as well?
Last edited:
I think here I am just not sure making a format as the basis is the right idea. Like @raytracingfan, they kind of fit into one another to a degree and are not mutually exclusive, but one idea at solving the problem is eminently less portable.Can’t support legacy hardware forever. If AMD’s stuff works well then having the hardware now will speed adoption in the future similar to RT. Software alternatives are fine in the short term.
Not 1:1 relevant, but thinking about Direct Storage GPU decompression (which I think has been a failure at this point for adoption). It mandates format according to my conversation with Nixxes, and that has made it usage far more troublesome.
DXR left a lot of room for innovation below its broad spec with version 1.0 - that is how we had 3 different vendors come up with 3 different solutions with that broader spec. But with a compression format for geometry, being codified in hardware, we are instead seeing one way to tackle the problem being *the only way* for the immediate XXX years after the next PlayStation comes out/next Direct X comes out. Do Intel and Nvidia then by necessity implement this hardware or format? Or do they pay the price of recompression? Ehhhh I am not liking this.
As a reminder - the consoles are setting the pacing for API advancement seemingly and AMD is *the consoles*.
Edit: Perhaps this requires a different thread before we start clogging up this one
Last edited:
It's a wash, they are basically the same. Only difference is that DGF is serializabe, CLAS isn't.It will be interesting to see how DGF fits with Mega Geometry, if both become standardized by the graphics APIs. They are both used with triangle clusters and could complement each other in theory, although I wonder if the tessellation examples Nvidia is showing up would work with DGF.
Tessellation is done by sub-division and re-clustering of the base mesh.
There' no overlap between the two concepts. You won't construct BLASes of objects containing triangles and LSSes at the same time. You construct two seperate BLASes of different type.Also, if Linear Swept Spheres are standardized by the graphics APIs, standardized geometry compression formats like DGF should support them.
Neither is either or. Nvidia emulates on older hw (or uses a programmable traversal & intersection processor; probably not the case otherwise they'd have jumped on intel's traversal shader proposal) same as suggests AMD could manage architecture backwards compatibility. In both cases the actual CLAS-type or DGF is custom and new, distinct from current ASes.Not sure if I like the direction of DGF for what it means for broader adoption vs. what NV has seemingly schemed.
One requires a new hardware unit, and one does not.
DGF is also not locked into needing a hardware block supporting it.Where as we have seen Mega Geo at its base already working on RTX 2000 and is not locked into adding a decompression unit to the GPU for this singular purpose.
I also think S3TC and BC were bad suggestions. Software lossy compression with programmable filtering woud have been much better. /sCompeting standards here with one requiring new decompression unit... yeah... not sure that is the way forward.
DFG proposes block compression for geometry, with selectable bitrate, while at the same time synergizing with clustering. If you want this, you have to bite the bullet and converge/cooperate on some format.
Exactly the same way.edit: how does DGF factor into dynamic tessellation as well?
DegustatoR
Legend
I'm not that sure that MG and DGF are tackling the same thing.
Presumably Nvidia h/w already does some sort of geo/BVH compression, DGF seem to just move that to storage instead of it being wholly on GPU runtime thing.
Both can co-exist and neither should prevent each other from being used IMO.
Presumably Nvidia h/w already does some sort of geo/BVH compression, DGF seem to just move that to storage instead of it being wholly on GPU runtime thing.
Both can co-exist and neither should prevent each other from being used IMO.
raytracingfan
Newcomer
AMD has its own interesting idea for RT LOD, which allows per-ray LOD selection during traversal without needing to store multiple LOD instances in memory.So if I read Mega Geometry right, Cluster LODs are not selected in the ray traversal, but a BLAS with the appropriate LODs is build for each frame? If so I preferred Intel's attempt.
Besides, AMD's BVH has always been 2 to 3 times the size of NVIDIA's BVH since Turing. Now, with Blackwell's claimed 75% BVH size on top, this would translate into 2.7 - 4x compression ratios for BVH when compared to the current AMD products, which should exceed or match the DGF compression ratios for BVH that AMD depicts in this image.Presumably Nvidia h/w already does some sort of geo/BVH compression, DGF seem to just move that to storage instead of it being wholly on GPU runtime thing.
The issue with DFG is that it requires compressing geometry, whereas MG does not require any additional compression from the engine to function.
As a result, MG has broader hardware and sw support, does not require any content preprocessing from engine, and provides the same if not better compression ratios for BVH, so what's the point of DFG then for anyone other than AMD?
Last edited:
Looks like a good substitute for Nanite's runtime structure with native hardware support.The issue with DFG is that it requires compressing geometry, whereas MG does not require any additional compression from the engine to function.
As a result, MG has broader hardware and sw support, does not require any content preprocessing from engine, and provides the same if not better compression ratios for BVH, so what's the point of DFG then for anyone other than AMD?
Mesh-shader support is hinted at.
DegustatoR
Legend
Some savings on storage and bandwidth. Dunno if its significant for the geometry - with full detail Nanite like meshes it could be?so what's the point of DFG then for anyone other than AMD?
And why exactly would you want to replace something that works on practically all hardware with something that works on none?Looks like a good substitute for Nanite's runtime structure with native hardware support.
The only possible reason could be achieving higher compression ratios for the DFG or perhaps noticeably better performance.
However, the claimed 4 bytes per triangle for DFG are quite comparable to the nanite's geometry compression ratio, which should be of a similar level. I have also never seen a game where decompressing nanite's storage format has been an issue or a performance bottleneck.
Regarding potential frame time spikes, which AMD mentions in its blog when transcoding from the storage format, the decompression speed of the early version of nanite's storage format was around 50 GB/s on the PS5 with unoptimized software. This is already much faster than what the PS5 SSD can provide. We have yet to see a game where those rates would be fully saturated. In existing titles, there is no scenario where those sw decompression rates would cause frame time spikes.
I also think S3TC and BC were bad suggestions.
I see your point but it’s not a perfect analogy. Compressed texture mips are self-contained and don’t have to worry about continuous LOD or cluster seams etc that complicate triangle meshes. DGF also doesn’t seem to handle other geometry structures like LSS.
If DGF solves all those problems, encourages a highly efficient cache architecture, enables faster runtime tracing and raster and allows for continued innovation then wide adoption will be great for everyone. Tall order though.
Sounds like good reasons.And why exactly would you want to replace something that works on practically all hardware with something that works on none?
The only possible reason could be achieving higher compression ratios for the DFG or perhaps noticeably better performance.
BVH construction is a big performance problem. CLAS construction forces one to transcode and then still build all of those Nanite clusters. With DGF neither is necessary, you put what you have on disk directly into the hierarchy.However, the claimed 4 bytes per triangle for DFG are quite comparable to the nanite's geometry compression ratio, which should be of a similar level. I have also never seen a game where decompressing nanite's storage format has been an issue or a performance bottleneck.
You don't mix and match triangles and spheres in the same BLAS for the same purpose. Having the equivalent of DGF for AABBs or OBBs or Spheres or LSS or Lozenges is something that can be complemented.I see your point but it’s not a perfect analogy. Compressed texture mips are self-contained and don’t have to worry about continuous LOD or cluster seams etc that complicate triangle meshes. DGF also doesn’t seem to handle other geometry structures like LSS.
We can encourage this direction if we see the glass half full instead of half empty and be constructive (good faith) along with critizism. Exploration is valuable, paths to solutions are not always linear, nor should they be unilateral.If DGF solves all those problems, encourages a highly efficient cache architecture, enables faster runtime tracing and raster and allows for continued innovation then wide adoption will be great for everyone. Tall order though.
An implementation of virtualized geometry is excessively complicated and intrusive. If the available support in the API/hw is such that it eventually just requires calling a handful of (portable) functions, then it's of benefit for every developer, big and small.
Similar threads
- Replies
- 2
- Views
- 3K
- Replies
- 21
- Views
- 10K
- Replies
- 90
- Views
- 17K