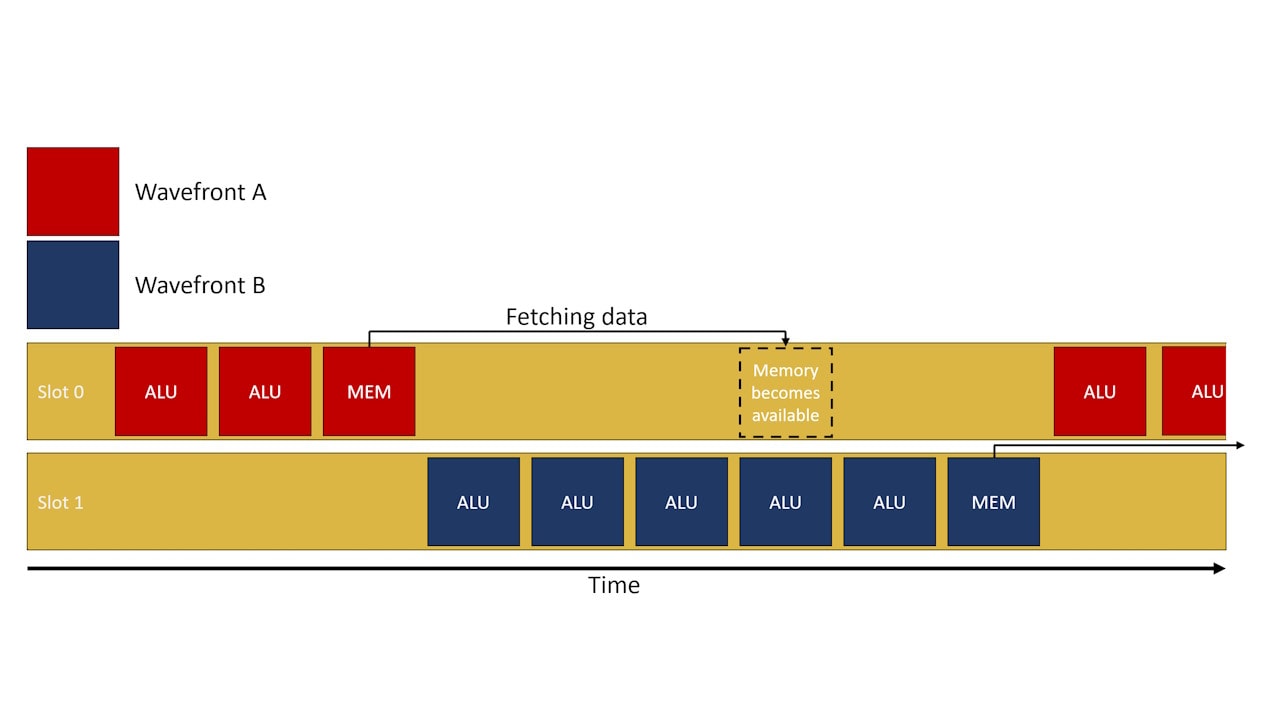
You’re assigning wins based on PPT slides
Not even AMD considers this a major win, so I don't know where the extreme enthusiasm is coming from? We've seen Variable Rate Shading falter, Mesh Shaders, Sampler Feedback, DirectStorage take ages to be adopted, even DX12/Vulkan themselves were a trainwreck that arguably benefitted no one in PC gaming, and gave no advantage to any single hardware vendor while giving the users/gamers a whole set of new headaches and inconveniences, what makes anyone think that WorkGraphs would any different?
The only somewhat successful API in recent years has been DXR, because it had the backing of NVIDIA behind it, which allowed it so spread quickly among AAA and AA developers, and allowed tangible visual improvements to be made after DX12 stalled on that front for years.
How about AMD steps up their game to achieve user experience parity with NVIDIA, because as of right now, the gulf of experience between NVIDIA and AMD is so vast it's not even funny.
An enthusiast gamer purchasing an RTX GPU will have vastly superior AI upscaling, AI denoising, AI HDR, significantly faster RT performance, lower latency as well as frame gen which is just available in many many more games. So now the user has faster frames, lower latency and better visuals (due to better upscaling, better denoising and better HDR) not available on AMD GPUs. This is the difference that counts to the user. Literally nothing else counts.
because the recent Marvel's Spider-Man games in RT mode do ~1 million
hmm, the same Spider Man where the
3080 is
65% faster than
6800XT using max RT settings, and 45% faster using medium RT settings?
Even without heavy scenes, the 3080Ti is 45% faster than 6900XT at both 1440p and 2160p using max RT settings.
Marvel's Spider-Man Remastered – это обновленное и переработанное издание игры, который содержит глобальные новшества в в

gamegpu.com
like advanced GPU driven functionality
AI is GPU driven rendering, the ultimate goal is detach rendering from relying on the CPU with it's added latency and threading issues, and AI is one way to do this.

developer.nvidia.com