DmitryKo
Veteran
The common part is that both generate an upscaled image from a lower rendering resolution. This image is either 1) upsampled using user-defined sample patterns, then filtered down to backbuffer resolution for presentation to display (MSAA), or 2) upsampled using predefined sample patterns selected by motion estimation derived from motion vectors, then kept at that higher resolution for presentation (TAA).There's nothing in common between MSAA and these TAA-based upscalers.
MSSA API could be extended to apply custom filters that generate the upscaled image by working with front and back buffers, depth buffer, and new motion vector and coverage/reactivity mask buffers, and send it for presentation; also, the same motion vectors can be used for interpolated frame generation at almost no additional cost. This would require modifications to DXGI swapchain management to handle the upsampled and/or interpolated frames (which previously required proprietary APIs in the kernel-mode display driver).
IMHO this should make it easier for developers to modify their code to support Super Resolution, as it would just look like a new MSAA mode to the application - even though from hardware point of view, MSAA works during rasterization as part of the rendering pipeline, while TAA engages after the rendering is fully complete as a post-processing step. Microsoft will probalby have their own ideas though.
DirectML isn't viewed as a real time API
It is, it's right on the intro page:
... You can develop such machine learning techniques as upscaling, anti-aliasing, and style transfer, to name but a few. Denoising and super-resolution, for example, allow you to achieve impressive raytraced effects with fewer rays per pixel.
... If you're counting milliseconds, and squeezing frame times, then DirectML will meet your machine learning needs.
For reliable real-time, high-performance, low-latency, and/or resource-constrained scenarios... you can integrate DirectML directly into your existing engine or rendering pipeline.

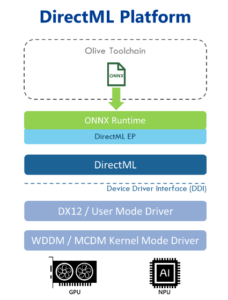
Introduction to DirectML
Direct Machine Learning (DirectML) is a low-level API for machine learning (ML).
learn.microsoft.com
DirectML was positioned for tasks like realtime upscaling/antialisasing right from its introduction back in 2018. It's designed to be hardware-accelerated by Direct3D12 GPUs with the help of metacommands, which expose GPU architecture-specific implementations of common inference operations, and these are combined into Direct3D12 command lists to execute graph-based workflows.

DirectML is coming to Windows 10 in Spring 2019 - OC3D
DirectML is coming to Windows 10 in Spring 2019 Microsoft has released an update on the upcoming DirectML API, an addition to the DirectX 12 API that will act in a similar way to DXR (DirectX Raytracing). Instead of adding support for ray tracing, DirectML is designed to add support for...
Accelerating GPU inferencing with DirectML and DirectX 12
Last edited: