Stage merging/reordering was made possible by 'unified shaders', that's R600/R700 era, but NGG also claimed better multithreading where the 4 geometry units would process 'more than 17' (?!!) primitives instead of only 4 per cycle. And that probably did not work as expected in real-world scenarios.
The whitepaper gives the following statement:
"The “Vega” 10 GPU includes four geometry engines which would normally be limited to a maximum throughput of four primitives per clock, but this limit increases to more than 17 primitives per clock when primitive shaders are employed."
The key phrase is likely "when primitive shaders are employed", and in this context probably means the total number of primitives processed (submitted + culled).
The compute shaders used to cull triangles in Frostbite (per a GDC16 presentation) cull one triangle per-thread in a wavefront, which is 16-wide per clock. There would be more than one clock per triangle, but this peak may be assuming certain shortcuts for known formats, trivial culling cases, and/or more than one primitive shader instantiation culling triangles.
Factors such as cache bandwidth between fixed function triangle processing blocks and general purpose processing units could have been the limit, even if inefficient scheduling of small batches was not. Navi should have improved upon this with larger caches and narrower SIMD wavefronts with better locality, which could have finally enabled the benefits of the 'automatic' path.
Going by how culling shaders work elsewhere, there's also the probability that a given wavefront doesn't find 100% of its triangles culled, the load bandwidth of the CUs running the primitive shaders is finite, and there's likely a serial execution component that increases with the more complex shader.
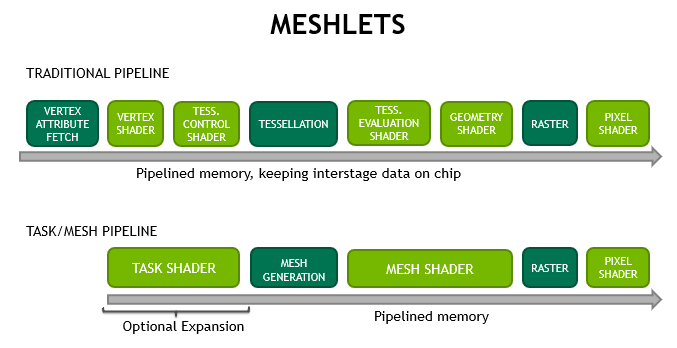
The merged shader stages don't eliminate the stages so much as they create a single shader with two segments that use LDS to transfer intermediate results.
Navi does do more to increase single-threaded execution, doubles per-CU L1 bandwidth, and the shared LDS may allow for a workgroup to split the merged shader work across two CUs.
I understand this is based on a
PS4 'triangle sieve' technique when the vertex shader is compiled and executed twice - first through the computer shader 'stage', only to compute the position attributes and then discard invisible primitives (back-faced triangles) from the draw call, and then as the 'real' full vertex shader 'stage' on the remaining primitives. That explains these references to 'general-purpose' and 'compute-like' execution and the statistics of '17 or more' primitives from 4 geometry processing blocks.
It does have significant similarities conceptually with compute shader culling and primitive shaders. Versus compute shaders, the PS4's method has microcoded hooks that allow this shader to pass triangles to the main vertex shader via a buffer that can fit the L2, which a separate compute shader pass cannot manage. That said, Mark Cerny even stated that this was optional since it would require profiling to determine if it was a net win.
AMD's primitive shader would have done more by combining the culling into a single shader invocation that had tighter links to the fixed-function and on-die paths, versus the long-latency and less predictable L2. The reduced overhead and tighter latency would have in theory made culling more effective since the front end tends to be significantly less latency-tolerant. However, it's redundant work if fewer triangles need culling, and the straightline performance of the CU and increased occupancy of the shader might have injected marginally more latency in a place where it is more problematic than in later pixel stages.
It's also possible that there were hazards or bugs in whatever hooks the primitive shader would have had to interact with the shader engine's hardware. There are mostly-scrubbed hints at certain message types and a few instructions that mention primitive shaders or removing primitives from the shader engine's FIFOs, which might have been part of the scheme. However, fiddling with those in other situations has run into unforgiving latency tolerances or possible synchronization problems.
If AMD is able to analyze code dependencies to discard instructions that do not contribute to final coordinate output, they don't even need programmer's input in making this 'automatic' shader very efficient to run.
That was AMD's marketing for Vega, right up until they suddenly couldn't. Existing culling methods show that it frequently isn't difficult to do (PS4, Frostbite, etc.), but for reasons not given it wasn't for Vega.
Navi supposedly has the option available, but what GFX10 does hasn't been well-documented.
However, AMD also said in the Vega 10 whitepaper there could be other usage scenarios beyond primitive culling - though they did not pursue these possibilities so far:
It's fine in theory, and some of the descriptions of the overheads avoided with deferred attributes came up a few times with AMD and with Nvidia's mesh shaders.
I've categorized all those as some kind of primitive shader 2.0+ variant, and haven't given them as much thought given AMD hadn't gotten to 1.0 (still not sure what version Navi's would be).

")