Like I said before, I don't see any fundamental problem with something like Flex FP. Keep calling it a coprocessor for all I care, but the x87 coprocessor most definitely got unified into x86. So you're not going to win this argument by changing the meaning of unified. If there comes an architecture that can extract high ILP and high DLP using a homogeneous ISA, and is fully viable as a CPU and low-end GPU, I will consider my theory proven.The argument was specifically for the coprocessor model of the x87 FPU. So if anything, I addressed the exact strawman you introduced to the discussion.
Let's go back in time again to when the GPU's vertex and pixel processing were separate and fixed-function. Anyone suggesting unification would have heard a lot of arguments why it's not a good idea. But when things became programmable, and then floating-point, it had progressed a lot closer to being feasible and desirable. And still even right before the GeForce 8800 was launched, NVIDIA's David Kirk was saying the cost of unification is huge. Today, not having unified shader would be unimaginable.And if you look back through the (hijacked?) Larrabee thread, you will find we (including others, especially 3dilletante for instance sketching the coprocessor model for CUs in the post following the linked one) talked about some kind of a coprocessor model for throughput tasks already quite some time ago. But you want a "true" unification, not some throughput CU(s) sitting next to the latency optimized cores to which the latency optimized cores can shift the execution (or call [asynchronous] subroutines there as I described it in this thread as a variation of it). So we went through all the arguments already almost two years ago. No need to repeat that.
The morale here is that any person who brought up unification in the early days of the GPU should not be told to shush because they've been over all the arguments already. Clearly they had not.
Neither do I think we've been over all the arguments for CPU-GPU unification yet. Year after year more actual convergence can be observed, and new techniques are identified to continue convergence, as well as hard laws of physics that either enable it or force us into it. But if you don't wish to be part of this exciting new conversation, nobody's forcing you to stay.
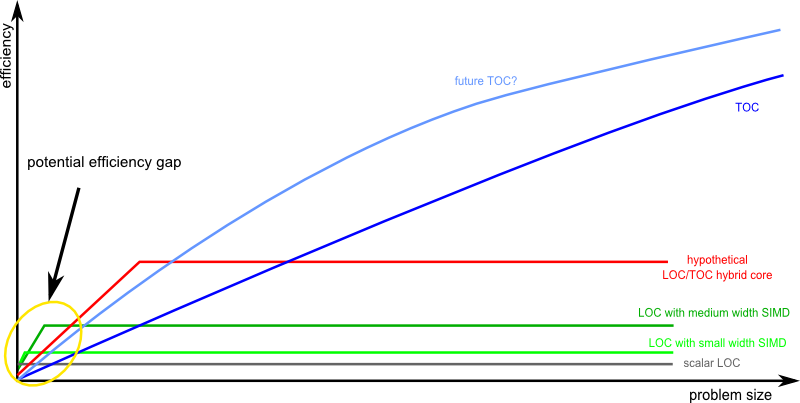
So-called latency-sensitive tasks still consist of a lot of loops and independent sections. If you vectorize and thread this code, it becomes throughput-oriented. Maybe that's only for parts of it, and it may switch characteristics fast, but you have to do a good job at it because extracting more DLP and TLP is cheaper than more ILP so it's critical in today's power constrained designs. This is why we're getting AVX2 and TSX.So what you are basically saying is that the evolution of games/GPU or 3D tech in general made the vertex load to become a throughput oriented task. So what does this change on my claim that there will be always latency sensitive tasks and throughput tasks?
Likewise your throughput-oriented tasks likely contain a lot of code with naturally short latency arithmetic instructions. During those sections you shouldn't be switching from one thread to another, because that causes poor locality of reference which, again, isn't ideal in a power constrained design. Storing large amount of temporary data in distant locations takes a lot of power. So there's a lot of latency sensitivity in what you're calling throughput-oriented tasks. It is why NVIDIA is experimenting with an architecture that has an ORF that is similar in function to the CPU's bypass network, to lower the average instruction latency and keep the last few results in close proximity of the ALUs for reuse in the next few cycles.
And just look at what both of the movements away from pure latency-oriented and throughput-oriented have already accomplished. A lot of today's applications would be unthinkable without SIMD units in the CPU, or unbearable without multi-core. Likewise the dramatic reduction in average instruction latency on the GPU has made it highly programmable and unified. Developers have welcomed each convergence step and have created applications that use the new abilities. But the developers themselves have also pushed for more convergence. John Carmack was a big proponent of floating-point pixel shaders, and GPU manufacturers also had a hard time keeping up with the increase in ALU:TEX ratio of the shaders that developers wrote, which lead to the decoupling of the texture and arithmetic pipelines to achieve lower latencies. Both things were key parts in the unification of vertex and pixel processing. Which then sparked the whole GPGPU idea, which required extending the capabilities even more.
The important thing to observe here is that latency-sensitivity and throughput-orientedness is in fact orthogonal. So it doesn't make a lot of sense to have a latency-sensitive core and a throughput-oriented core. You wouldn't get good results for workloads that are both throughput-oriented and latency-sensitive. What's more, you also wouldn't get good results for workloads that frequently switch from being more latency-sensitive and less throughput-oriented, to less latency-sensitive and more throughput-oriented, because there's considerable overhead in the switching. A unified architecture would no doubt spark the development of a lot of new applications that make it unthinkable to go back.
But which came first, the chicken or the egg?That's not the point. But the parts of an application posessing a vast amount of DLP (that's the easiest one) and potentially TLP can be characterized as very parallel parts or throughput oriented parts. The parts exhibiting relatively small amounts of DLP and TLP can be characterized as serial or latency sensitive tasks. That's not a distinction I just came up with, you find it in one or the other form already for decades. And I think there is a good reason for that and also that different hardware approaches were developed for tackling these two different classes of tasks.
Do we have software that has tasks targeted at the CPU and tasks targeted at the GPU, because we lack a unified architecture to do it any other way, or do we have a separate CPU and GPU because all the software you can come up with has large sections of code which are purely latency-sensitive or throughput-oriented. Based solely on a snapshot of the situation as it stands today, with no further context, either explanation is as good as the other.
We have to look at history and future trends to see the answer. Or better yet: answers. The GPU was originally created to process one and only one task much faster: old school rasterization graphics. It started off ridiculously simple with one texture unit and one raster unit. But that use case was important enough for gamers to want to buy a graphics card. So at that moment we had a separate CPU and GPU because all of the valued applications at that time had workloads that could be clearly divided into graphics, and everything else. But there was en enormous desire to go back to the flexibility offered by the CPU, and over the years the GPU became highly programmable and latency sensitive. And at the same time, the CPU became a lot more parallel for various other workloads. So now the division isn't so clear-cut any more. You can run OpenCL kernels on either the CPU or the GPU, and for various reasons one or the other could be faster.
So once again I come to no other conclusion than a strong convergence. We are stuck for now with these heterogeneous systems for historic reasons that are fleeting. I'm not saying graphics isn't important any more. I'm saying graphics evolved from single-texturing into something that is both throughput-oriented and latency-sensitive.
By instruction latency I meant the latency between the start of one instruction in a thread, and the ability to execute the next dependent one. So aside from execution latency this includes any latency added by scheduling, operand collection, and writeback.That is not exactly limited by the instruction latency. It is usually limited by the task scheduling latencies which are orders of magnitudes larger than instruction latencies and often heavily influenced by driver overhead. That overhead is what AMD and nV want to get rid of (and can do so already in some cases in the latest GPUs).
Anyway, if AMD and NVIDIA want to get rid of some of that latency, then that clearly converges the GPU closer to the CPU architecture again.
Before the shader cores were decoupled from the texture units (and unified), texturing and arithmetic operations were part of one long pipeline with over 200 stages. This covers the entire RAM latency. The texture cache is only there to lower bandwidth in case of a hit. It would only stall when running out of bandwidth.What hundred cycles latencies are you talking about regarding old GPUs? I have something at the back of my head telling me that older GPUs tended to stall if something wasn't in the L1 texture cache (was still the case with the GF7/PS3 GPU)?
No, they didn't become more latency tolerant. The GeForce 8800 was optimized for two or three registers per thread. If you needed more than that, a high number of texture fetches would cause it to stall due to not having sufficient threads to cover the latency (assuming a sufficient texture cache hit rate to not stall due to bandwidth).Today, they can easily tolerate a few cache misses and hundreds of cycles latency to load it from DRAM without stalling. So something appears to be wrong here. GPUs definitely got more throughput oriented and more latency tolerant to increase their performance.