OpenGL guy
Veteran
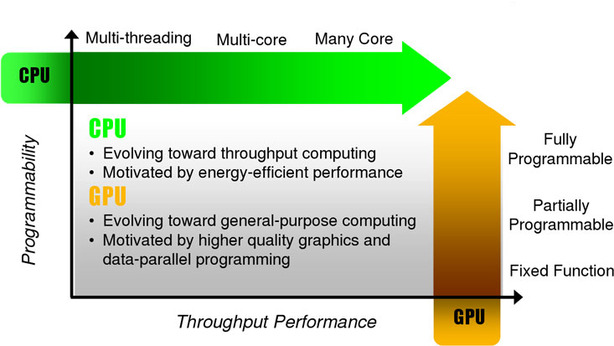
Have you given thought to what's required to do a single texture lookup? Also, what about the states that affect texturing such as filter mode, addressing mode, texture format, etc.? Apps already create a large number of shaders (sometimes many aren't even used), but now you'd add a bunch more permutations if you need to recompile shaders based on what texture sampler states and/or textures are enabled.ALU:TEX ratios continue to rise. At the same time, we're starting to see a clear need to access memory in a more generic way, not just reading textures. The post you're linking to suggests that GT200 dedicates only 13 % of die space to texture samplers. So it's not inconceivable that in the future they'll be replaced with generic gather units and the fraction of filtering is done in the shader cores.
Today's GPUs perform all calculations in 32-bit floating-point. Yet most of the time with graphics we're still working with colors that have 8-bit integer components. Is that optimized? So why would it be a big deal to generalize the texture samplers as well? They pretty much have to be capable of filtering floating-point textures at full precision anyway.
Of course it's not impossible, but it's not trivial either.