You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia GT300 core: Speculation
- Thread starter Shtal
- Start date
- Status
- Not open for further replies.
The decoder scheme seems to be simplest when looking at the SIMD position in a different warp, not just any thread on any warp in the work group.
Well if there is any chance of this working it seems locking threads into a SIMD lane would be much easier so that's probably the way it would go.
A simple decoder running on the 1/0 barrier table would be inadequate, since the decoders, if they did actually issue a work unit out of warp order, would not have the state to know not to do it again the next cycle.
Not sure what you mean by this. The decoders don't know anything about warp ordering. Don't they just blindly calculate register addresses based on thread iD?
It would follow that the incoming threads are inserted into a warp with the same PC. I'm not sure what it would mean to assign a thread to a SIMD that was executing a different instruction entirely.
Yeah, but the point of the indexing is to limit the breadth of the search for an insertion location in the warp pool. Why do you think it has to scan the entire 1K set of work units each cycle?
I assumed that the collection process would be multi-cycle. The mention of bank conflicts and other items would indicate that throwing work units around effectively at random would make it much worse.I don't want to be a bore before heading off to bed, but the patents I linked need a closer read. e.g. you'll find the operand collector has latency (i.e. it takes more than one clock for an operand to cross from collector to ALUs) and a crossbar for feeding the ALUs. Any operand can go to any one or more ALU lanes (well, we knew this from CUDA documentation).
The compiler would most likely give up trying anything complex as far as allocation goes if it finds a barrier-inducing condition. Nothing statically compiled to avoid bank conflicts or other issues is going to be respected anyway and we're leaning on the random operand collector to make up for it.Also, as it turns out, register allocation within the register file is a whole kettle of fish. There's potential here for interaction with registers/blocks of registers that the compiler/driver sees as being the target of incoherent accesses (e.g. registers used within a loop).
Additionally there is not a single scoreboard per multiprocessor, but the instruction dependency (per-warp and per-instruction) and operand collection (per-warp, per-instruction and per-operand) scoreboards run independently.
From that description, the two scoreboards don't need the same data, and there is economy of signalling and data generation work if they are kept separate.
The instruction dependency scoreboard might not care too much about the coalesced warps.
The operand collection scoreboard's job is measurably more complex the more arbitrary work unit assignment to a lane is.
Is there a reason why the operand collector would care what operation it's feeding?Available instructions from the instruction-dependency scoreboard are submitted to the operand collector (i.e. op-code + operand addresses + resultant address to handle the resultant's return).
In the barrier scheme, it might get by with operand and result addresses coupled with a work-unit identifier or at least the bits indicating which lane and which warp.
How many of those rules are unaffected by a switch to arbitrary lane allocation?So scoreboarding is, effectively, an hierarchical process and it seems the operand collector can reject requests for instruction execution based on a pile of rules.
The 1024 entry barrier scoreboard that tracks over the duration of a gather would be allocated for how long?Also of note is the lifetime of rows in the scoreboards - in the operand collector, lifetime is very short generally. Warps are effectively permanently allocated only in the instruction dependency scoreboard, as far as I can tell.
So something like a barrier scoreboard would be orthogonal, again. Warps that get picked by the barrier scorer will then be tested against the instruction-dependency scoreboard, and then the operand collector will perform final arbitration for the "random" fetching required to populate ALU lanes, where by taking a stream of warps' bit-masks of valid work items - instead of just a single warp-instruction as would be the case when barrier handling is not required.
The barrier scoreboard does work at the level of tracking gather operands, and it does so at a scale greater than the instruction-dependency scoreboard, and it persists as long as the work group exists.
It's a functional idea.
It's words like random, arbitration, and stream that look fine on paper or in software that worry me.
As far as a physical implementation goes, I have concerns.
It's not so much blind as aware of a wider problem space than what static linkage would need to scan.The operand collector already does most of this - just the final piece of the jigsaw, being "blind" to warp when assembling operands for ALU lanes is needed, I believe.
I just started skimming.Tomorrow, I'll go through Fung's stuff...
They didn't like breaking lane association either.
The bank conflicts from trying to move things around led to some pretty significant performance drops in simulation.
The problem for branch divergence is in many ways more tidy than the one for coalescing work units based on barrier resolution.
Branches are encountered and divergence are determined within a fixed and determinate period of time.
The update to the needed structures needs to only happen a few times, and the accesses for that data generation are of a fixed number.
The barrier table persists for the lifetime of a work group waiting on an event such as a gather operation, and it needs to be updated repeatedly.
The scheme actually could be significantly simplified, I think, if we enforced some kind of lane restriction instead of trying to cover every part of the problem space.
It can be made to work. My concern is that it can be made to do so in a reasonable physical envelope.Well if there is any chance of this working it seems locking threads into a SIMD lane would be much easier so that's probably the way it would go.
The barrier table proposal is a bit more complex. The decoders on that table would try to detect ready units that can procede to process through the instructions in a given window of instructions.Not sure what you mean by this. The decoders don't know anything about warp ordering. Don't they just blindly calculate register addresses based on thread iD?
What happens when one set of units makes it to the end of the window?
We don't want the issue logic to try to increment the PC and then coalesce those work units with other units still stuck on a different instruction. A single bit is not sufficient to catch that state. We can have a side pointer that tells the rest of the scheduler to stop trying to issue these units, but that's additional state.
We can spawn new tables and stack them, at the cost of more actively updated state.
The description of this table's function indicates we're sending a stream of masks, which hints that it is being very thorough.
EDIT: And it was described as such:
"32-wide, 4 phases of 8"
The work units are sitting on barriers, and the example given was a gather which by the vagaries of memory access might be able to randomly supply some units far in advance of others.Yeah, but the point of the indexing is to limit the breadth of the search for an insertion location in the warp pool. Why do you think it has to scan the entire 1K set of work units each cycle?
There's no timetable for when other gather operands will become available, and to which work units.
Last edited by a moderator:
Jawed
Legend
Even without dynamic warp formation there'll still be bank conflicts.I assumed that the collection process would be multi-cycle. The mention of bank conflicts and other items would indicate that throwing work units around effectively at random would make it much worse.
Register allocation is very complex in NVidia's design. The reason for the complexity is because of single-porting of the register file and the opportunities to reduce bank conflicts that the operand collector provides. In other words, for given patterns of register usage there are good and bad allocations. I'm merely inferring that there's an opportunity to implement rules based specifically upon a warp-forming operand collector, if such a thing were built, simply to maximise performance in this situation... e.g. use of contiguous register slots versus use of discontiguous slots versus fat-allocation versus thin allocation versus warp-phased allocation, etc.The compiler would most likely give up trying anything complex as far as allocation goes if it finds a barrier-inducing condition. Nothing statically compiled to avoid bank conflicts or other issues is going to be respected anyway and we're leaning on the random operand collector to make up for it.
Plus, by running them in a pipelined fashion, evaluation throughput (even with more complex rules) can be maintained at the cost of latency.From that description, the two scoreboards don't need the same data, and there is economy of signalling and data generation work if they are kept separate.
Yes, definitely. Whatever scheme one comes up with for determining the scope and depth of divergence tracking, actual assembly of temp warps is costly.The instruction dependency scoreboard might not care too much about the coalesced warps.
The operand collection scoreboard's job is measurably more complex the more arbitrary work unit assignment to a lane is.
A key point in linking the patent documents is that a lot of this complexity already exists.
For example, one thing Fung doesn't realise is that any operand can go to any lane - there's a crossbar after the operands have been retrieved. This makes some of his modelling flawed - I'm at section 4.2 by the way, reading carefully...
As far as I can tell the operand collector is effectively performing instruction issue, so it is assembling instructions with entirely literal data for the ALU lanes to consume.Is there a reason why the operand collector would care what operation it's feeding?
Lane allocation is already arbitrary as far as operands are concerned. I have to admit my first reaction to these rules is "uh? why reject instructions?". It may be due to limited capacity in the scoreboard if it's seen as having to stick around for too long.How many of those rules are unaffected by a switch to arbitrary lane allocation?
Which of course raises the question of the actual cost of the operand collector as it now stands. Dunno...
Simplistically, as long as a gather persists - and, effectively de-activated when there's no incoherence causing empty ALU-lanes or ALU stalls.The 1024 entry barrier scoreboard that tracks over the duration of a gather would be allocated for how long?
If the code has a long-ish loop with a gather inside it, then things explode. One of my concerns with my idea is that barrier and predication masks overlap in meaning and intertwine in scope. So a barrier stack seems like an obvious solution, but then...
Predication must be retained because it's impossible to construct non-divergent warps and also it might be prudent to apply thresholding to DWF (varies by type?), e.g. only perform DWF if the multiprocessor is due to run out of available warps within X cycles, that kind of thing - since DWF has a start-up latency due to an increase in operand collection latency.
Need to build a simulator to really figure this stuff out.
It's interesting just how complicated NVidia's made its warp/instruction/operand windowing. The salient point, where I came in as it were, is that I suspect with relatively minor tweaks in the grand scheme, it could make a really robust scheduler that eats all the forms of incoherence that afflict SIMD machines.It's a functional idea.
It's words like random, arbitration, and stream that look fine on paper or in software that worry me.
As far as a physical implementation goes, I have concerns.
Though they can't be that minor or we'd have seen them by now. But well, better is the enemy of good enough.
I haven't got there - note my earlier caveat that lane association is partly a red herring (only partly because work items still need to be sieved to obtain non-colliding lanes in a temp warp).I just started skimming.
They didn't like breaking lane association either.
The bank conflicts from trying to move things around led to some pretty significant performance drops in simulation.
Yeah - branch-divergence, on its own, if it can be made to work, would be a significant step forward.The problem for branch divergence is in many ways more tidy than the one for coalescing work units based on barrier resolution.
Branches are encountered and divergence are determined within a fixed and determinate period of time.
For example, Keenan Crane's Julia set shader, which is rather rich in control flow:
http://graphics.cs.uiuc.edu/svn/kcrane/web/project_qjulia_source.html
has the following "average" execution statistics:
HD4870 - 18382 cycles
HD4670 - 14617 cycles
Now I admit that's just a headline-grabbing fairly meaningless statistic (those are numbers from GPUSA - benchtesting would be much better :smile: ), but the basic idea here is that this shader is roughly the same speed on HD4670 as on HD4870 due to the former having smaller work groups, and therefore less ALU lane wastage.
Barrier scoring is just an outline idea - my desire is to consider how to solve more than just control flow divergence, since DWF should be a solution to all these problems.The barrier table persists for the lifetime of a work group waiting on an event such as a gather operation, and it needs to be updated repeatedly.
The scheme actually could be significantly simplified, I think, if we enforced some kind of lane restriction instead of trying to cover every part of the problem space.
Put another way, if NVidia builds DWF for control-flow divergence, what's the incremental cost to implement comprehensive barrier-based DWF (bearing in mind that NVidia's scheduling is already very costly)? I haven't got a simulator lying around, so I don't even know if it would be worth doing...
Jawed
Jawed
Legend
Yep, which is why I was inspired by Timothy's initial questioning of the likelihood of something more like MIMD...In the intervening time, I think we've learned a lot more about dispatch, to the point where I thought we had decided that register fetching wasn't necessarily as straightforward as we had originally thought, which would make it easier to juggle threads around...?
Jawed
I'm not implying that there wouldn't be. Compiler or programmer efforts to help minimize such conflicts would be negated past a barrier, once the hardware starts to reorder units.Even without dynamic warp formation there'll still be bank conflicts.
A catch-all solution may be hard to optimize for all cases.I'm merely inferring that there's an opportunity to implement rules based specifically upon a warp-forming operand collector, if such a thing were built, simply to maximise performance in this situation... e.g. use of contiguous register slots versus use of discontiguous slots versus fat-allocation versus thin allocation versus warp-phased allocation, etc.
For gather operations, perhaps an optimization would be to keep operands fed by gathers as spread evenly as possible between banks, in order to minimize the number of times bank conflicts arise.
I haven't seen the part where he said it was impossible, just that having multiple threads with the same "home lane" was undesirable.For example, one thing Fung doesn't realise is that any operand can go to any lane - there's a crossbar after the operands have been retrieved. This makes some of his modelling flawed - I'm at section 4.2 by the way, reading carefully...
What is the throughput of the crossbar, and with what restrictions?
The diagrams I saw seemed to indicate each SIMD pipe had a direct connection with its local subset, and then there were connections between the sets of unspecified capacity.
It may be difficult or undesirable to turn the process off. The data paths and logic don't vanish if the GPU shifts down to DWF-off, and the DWF hardware could just as easily generate the standard case on its own, if put to it.Predication must be retained because it's impossible to construct non-divergent warps and also it might be prudent to apply thresholding to DWF (varies by type?), e.g. only perform DWF if the multiprocessor is due to run out of available warps within X cycles, that kind of thing - since DWF has a start-up latency due to an increase in operand collection latency.
Having both modes seems akin to having both a manual and automatic transmission stuck on a car.
Jawed
Legend
Yep, that's what I'm getting at, but not just for gather, but for the register file. Nice bank access patterns are clearly the reason NVidia has implemented a rule set for register allocation. They'll never be perfect, but bear in mind that the worst-case waterfall is 1/16th throughput, so any improvement to be gained there is a huge huge benefit.Compiler or programmer efforts to help minimize such conflicts would be negated past a barrier, once the hardware starts to reorder units. [...]
A catch-all solution may be hard to optimize for all cases.
For gather operations, perhaps an optimization would be to keep operands fed by gathers as spread evenly as possible between banks, in order to minimize the number of times bank conflicts arise.
One thing I've realised is that the CUDA documentation doesn't steer the developer around anything the compiler might do to re-structure register allocation (e.g. make r0-r3 fat, r4 and r5 thin, r6 warp-phased). This implies to me that register allocation rules that run when a shader (kernel) are loaded into a multiprocessor are prolly constrained when running CUDA apps. But for graphics the rules have free reign. Dunno.
Obviously register allocation completely breaks down in the face of truly random register fetches.
None of the operand collector architectures he describes in section 4.1 match what NVidia has implemented. He's simply missed what NVidia's done.I haven't seen the part where he said it was impossible, just that having multiple threads with the same "home lane" was undesirable.
It was vague. The CUDA documentation is quite thorough in describing the restrictions on bandwidth that result from various RF->ALU lane mappings.What is the throughput of the crossbar, and with what restrictions?
I presume you're referring to the MAD and MI pipes as having distinct subsets of register file? My interpretation is that that's unworkable...The diagrams I saw seemed to indicate each SIMD pipe had a direct connection with its local subset, and then there were connections between the sets of unspecified capacity.
Maybe you mean that MAD and MI have distinct operand collectors?
Agreed.It may be difficult or undesirable to turn the process off. The data paths and logic don't vanish if the GPU shifts down to DWF-off, and the DWF hardware could just as easily generate the standard case on its own, if put to it.
It might be a question of trading latency, e.g. 2 cycles of extra windowing latency means that for the same performance an extra 4 warps' capacity has to be added and/or the register file has to grow by 10-20%.
Having discovered the rats nest (bit harsh) that is NVidia's windowing, I'm not convinced there'd be much difference either way. Which is why I think DWF would actually be an easy-win for NVidia in the D3D11 generation. And why I'm kinda excited. Fingers-crossed!Having both modes seems akin to having both a manual and automatic transmission stuck on a car.
Jawed
Jawed
Legend
So, overall I'm happy with the outline concepts in Fung's thesis. In section 9.3.3 he mentions how DWF could be used to ameliorate general bank conflicts:
Jawed
So, I remain hopeful that NVidia will tackle the gamut of incoherency issues with one fell swoop in GT300 :smile:Bank conflicts in shared memory access, as noted by Hwu et al. [27], have been a major performance bottleneck in GPU's performance. While this thesis focuses on using dynamic warp formation for improving control flow efficiency in a SIMD pipeline, we have also observed that it is possible to regroup threads, in a fashion similar to how we propose to do this for lane aware shecudling, to eliminate bank conflict in cache or shared memory access. The exact implementaton and hardware cost of this idea should be explored in the future.
Jawed
Does it strike anyone else that these tricks should get even more effective with smaller batch sizes? And does it strike anyone else that smaller batch sizes become more cost-efficient when the register file becomes bigger (ala GT200 doubling it) or the units become more powerful (ala RV770: INT32 MULs & shifts for every ALU)?
I also think that what is at least as important to improve as branch coherency is the quad-related overhead of small triangles. While we're never going to be able escape those for texture operations unless we do quite expensive tricks in the rasterizer to combine triangles etc., it seems to me we can still reduce their ALU overhead.
Consider what a MIMD architecture like PowerVR's SGX can do: it only has to do ALU operations for anything that determines the texture coordinates of any future texture operation. It can completely bypass everything else, it seems to me. I would suspect that a 'loose MIMD' approach could do the same if implemented properly.
Another possible approach, of course, is strict MIMD ala SGX. While Jawed thinks that is very expensive, I am far from convinced that it is: it requires to be a lot smarter about your control logic, but it's not impossible. SGX's die size is proof enough of that, and the overhead would be even smaller if each ALU was 32x32 MUL/57x57 ADD instead of 24x24 MUL&ADD, it seems the overhead should be even smaller... Of course, going down that route prevents you from double pumping the ALUs and not the control logic! Unless your control logic can dual-issue, which it seems to me would only make sense if each issue was for a separate register file.
I also think that what is at least as important to improve as branch coherency is the quad-related overhead of small triangles. While we're never going to be able escape those for texture operations unless we do quite expensive tricks in the rasterizer to combine triangles etc., it seems to me we can still reduce their ALU overhead.
Consider what a MIMD architecture like PowerVR's SGX can do: it only has to do ALU operations for anything that determines the texture coordinates of any future texture operation. It can completely bypass everything else, it seems to me. I would suspect that a 'loose MIMD' approach could do the same if implemented properly.
Another possible approach, of course, is strict MIMD ala SGX. While Jawed thinks that is very expensive, I am far from convinced that it is: it requires to be a lot smarter about your control logic, but it's not impossible. SGX's die size is proof enough of that, and the overhead would be even smaller if each ALU was 32x32 MUL/57x57 ADD instead of 24x24 MUL&ADD, it seems the overhead should be even smaller... Of course, going down that route prevents you from double pumping the ALUs and not the control logic! Unless your control logic can dual-issue, which it seems to me would only make sense if each issue was for a separate register file.
Does it strike anyone else that these tricks should get even more effective with smaller batch sizes?
Batch sizes, you mean warp sizes (nv speak) or wavefront sizes (ati speak) don't you?
And does it strike anyone else that smaller batch sizes become more cost-efficient when the register file becomes bigger (ala GT200 doubling it) or the units become more powerful (ala RV770: INT32 MULs & shifts for every ALU)?
Could you explain that for me please?
Thanks
Batch sizes, you mean warp sizes (nv speak) or wavefront sizes (ati speak) don't you?
Batch size refers to ability to have size of branches, warp size refers to size and number of threads, and wavefront size is granularity which is affected by batch sizes
[/QUOTE]
Jawed
Legend
Yeah, they're interchangeable terms here.Batch sizes, you mean warp sizes (nv speak) or wavefront sizes (ati speak) don't you?
Separately, in OpenCL there's a work group and in D3D11-CS a thread group. These are the equivalent of a block in CUDA. While a block in CUDA can be any size, I think that D3D11-CS defines a fixed size for a block (1024 threads). This size will change (increase) with succeeding versions of D3D.
Clearly a GPU can break up a work group/thread group/block into as many batches/warps/wavefronts as it needs to. The latter is a hardware constraint.
Jawed
Jawed
Legend
Nope, the converse. The graphs Fung provides are evidence enough (since there's less to gain with smaller batches), and the GPUSA stats I provided earlier reinforce this - even if they're a rather basic first impression.Does it strike anyone else that these tricks should get even more effective with smaller batch sizes?
If you're going to invest in the control overhead for small warps (either narrower SIMDs or less phases per warp-instruction) then you have to weigh the cost of the extra control overhead versus dynamic warp formation.
DWF is effectively providing smaller warps, on average, during incoherent interludes ("taking several small warps and combining them into one"). So below a certain warp size DWF becomes pointless.
The granularity of DWF becomes an issue, too. e.g. do you want to be able to combine any 32 warps to make up a temp warp? Or is it better to limit this to any 16, or any 8? etc.
Jawed
I don't think I agree with that. You're looking at existing workloads. If you take generic workloads, random divergence is going to bit you in the backside no matter your warp size as long as it's more than one (aka MIMD).Nope, the converse. [...] (since there's less to gain with smaller batches)[...]then you have to weigh the cost of the extra control overhead versus dynamic warp formation.[...]
To take an extreme case, imagine an if-else case where each branch has a truly random 50% chance of being taken. In a case without DWF and a warp size of 2, you have four possible cases, each with a 25% probability: T0=True/T1=False - T0=False/T1=True - T0=True/T1=True - T0=False/T1=False. Clearly efficiency is 50% in cases 1/2, and 100% in cases 3/4, resulting in average efficiency of 75%. The greater the warp size, the nearer to 50% you get; but you can never get above 75 or below 50...
With DWF, your efficiency with an infinitely long number of warps being checked is 100%. However, even with a very small number of warps being checked, it should easily be very near 100%; but this is not the case with much larger warps, where you need to check many more warps to achieve near-100% efficiency.
So I should have made my comments more precise: DWF becomes more effective for smaller batches *in the case of realistic numbers of warps being checked*. It seems crazy to me to check 32 warps per clock cycle, so I didn't even consider that possibility; I guess that's where our misunderstanding comes from...
")
Jawed
Legend
In other words, the possible gain from DWF as warp size decreases gets less and less.
And with decreasing warp size the increase in control overhead associated with smaller warps utterly swamps the DWF control overhead.
So, yes, in some abstract sense the area overhead of DWF dimishes in comparison with control overhead - but so does the performance gained with DWF.
You're ignoring the total cost of the GPU with these smaller warp sizes.
I will agree that there has to be a sensible limit on the number of warps.
Don't forget that currently a warp only issues once every 4 clocks, so that makes the construction of a temp-warp less onerous than it first appears. This latency is also used to ease operand collection and with DWF a different latency versus SIMD-width trade-off may arise.
For a variety of reasons Fung's simulator is further away from G80 than ideal. It's very much qualitative rather than quantitive.
---
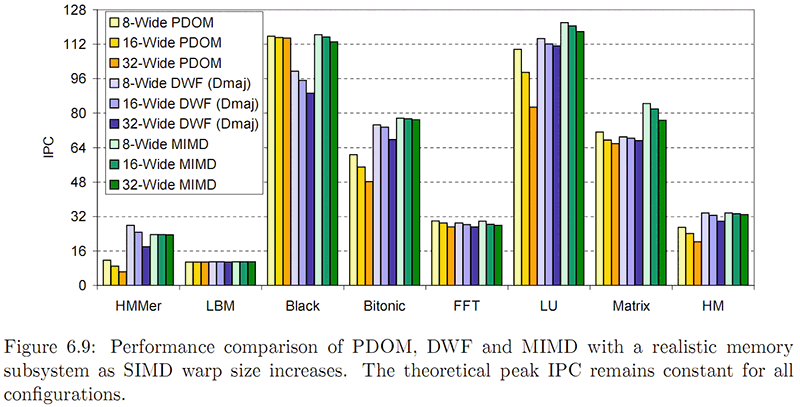
It's notable that the harmonic mean of IPC is, in the ideal MIMD case, about 33/34.
Some attributes of the simulator cause an unexpected variation in MIMD IPC
It's interesting to see how DWF actually makes HMMer faster in the 8 and 16 warp-sized cases than MIMD :smile:
Apart from that, averaging these apps this GPU is, according to the simulator, only able to achieve ~1/4 of theoretical ALU utilisation in the MIMD case. I could take this as a cue to indicate that more widespread use of DWF (i.e. to solve all incoherency) is really needed to make it truly compelling.
Jawed
TimothyFarrar
Regular
I don't think I agree with that. You're looking at existing workloads. If you take generic workloads, random divergence is going to bit you in the backside no matter your warp size as long as it's more than one (aka MIMD).
Seems to me that MIMD with DWF makes more sense than DWF with SIMD. SIMD adds a constraint that all work-items in the dynamic warp have the same instruction, which would complicate the scheduler? So why not have the ALU backend be independent scaler with a private scalar register file. Work-items would be locked to a given scalar ALU unit. Then use dynamic work-item groupings to handle bank conflicts through a loosely coherent cache (ie only enforce coherency on atomic instructions). Cache used for everything from shared "registers", constants, and access to global memory. Thus only one form of "divergence" to deal with (a cache) vs current state of branch/constant/shared_register/register_file/global_memory.
BTW, any speculation on cache for GT3xx?
A warp is a single instruction applied to a group of work items in lockstep.
In what fashion would a warp be applicable to a MIMD setup, where forming a warp would be forcing them into lockstep?
In what fashion would a warp be applicable to a MIMD setup, where forming a warp would be forcing them into lockstep?
Jawed
Legend
I think this is part of Arun's argument in favour of MIMD - it's possible with a MIMD machine to still operate on blocks of data, thus use bank-bursts to your advantage to gain maximum bandwidth efficiency, rather than taking a truly scatter-gun approach to each kind of memory operation (register file, constant cache, shared memory, memory), by fetching single operands.
So a burst fetch from a register file might produce 16 cycles worth of data in the normal case. This would allow the ALU to run at a much higher clock than the register file and also allow single-porting, etc.
It's analogous to cache lines providing data for more than one cycle in a regular CPU.
Well, that's my interpretation.
Jawed
So a burst fetch from a register file might produce 16 cycles worth of data in the normal case. This would allow the ALU to run at a much higher clock than the register file and also allow single-porting, etc.
It's analogous to cache lines providing data for more than one cycle in a regular CPU.
Well, that's my interpretation.
Jawed
Heh, it might be worth noting how incredibly wrong everybody was about G80. It's pretty entertaining reading those old speculation threads....
If we're anywhere near as wrong now as we were then, this upcoming generation could be very interesting. Anybody think we'll get better texture filtering this time around? Maybe a control panel option to force bicubic filtering in the shaders or something. It would be slow but probably more useful than the unnecessarily super high MSAA modes they offer now.
If we're anywhere near as wrong now as we were then, this upcoming generation could be very interesting. Anybody think we'll get better texture filtering this time around? Maybe a control panel option to force bicubic filtering in the shaders or something. It would be slow but probably more useful than the unnecessarily super high MSAA modes they offer now.
- Status
- Not open for further replies.