Not necessarily. High performance in one benchmark often does not translate to many others.if the Crysis bench on HD5870 is correct, no, it wouldn't be faster than HD5870. in fact it would be a fair bit slower.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia GT300 core: Speculation
- Thread starter Shtal
- Start date
- Status
- Not open for further replies.
Crysis bench on HD5870
what where?
what where?
It was on some Chinese forum. Something like the 5870 getting 30+FPS in Crysis at 1080p 4xMSAA Very High. Almost sounds too good to be true but here's hoping.
Edit: It was Chiphell
http://bbs.chiphell.com/viewthread.php?tid=53938&extra=page=1
Did you link that article as support for rpg's statement or the opposite? According to the conclusion RV770 has a much higher theoretical increase in MADD flops while GT200 has a higher increase in actual performance indicating lower utilization on the former.
Edit: Ah re-reading that thread I see you disqualified a bunch of pcgh's data and came up with your own conclusion. Don't think there's anything concrete there. This comparison should get easier with OpenCL (unless people write different versions of their apps for Nvidia and AMD hardware)
Jawed
Legend
There are almost no games that show the GFLOPs advantage of ATI providing a benefit to the gamer. Hardly shocking, really.Edit: Ah re-reading that thread I see you disqualified a bunch of pcgh's data and came up with your own conclusion. Don't think there's anything concrete there.
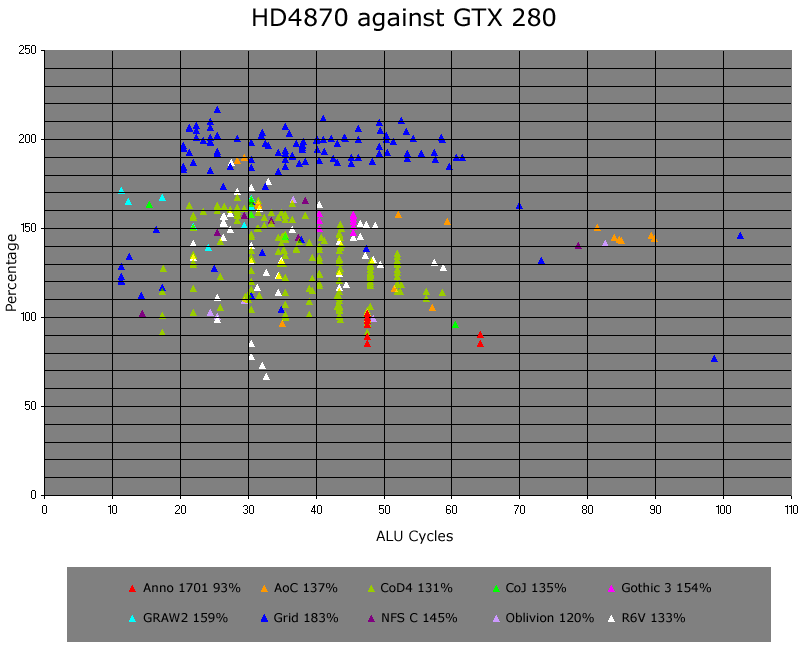
The graph is self-explantory really, and I whittled it down to some basic facts, such as HD4870 is 45% faster in ALU-limited shaders, on average. I imagine drivers have changed the picture by now, but who's going to invest the requisite time to find out?
You mean like when matrix multiplication on ATI runs at >2x NVidia when both are "fully optimised"?This comparison should get easier with OpenCL (unless people write different versions of their apps for Nvidia and AMD hardware)
Jawed
Ah ok. That would be a LOT of bandwidth.512 bit GDDR5.
Well still using shader clusters with a couple SP units, some DP units, TMU grouped together, with the ALUs running at higher clock, and unlike ATI still with scalar ALUs. Though if it's really using MIMD won't that actually decrease performance per die area further (at least for graphics)?What do you mean by "shader organization"?
You mean like when matrix multiplication on ATI runs at >2x NVidia when both are "fully optimised"?
Sure, pick the example that has no dynamic branching and was hand tuned in IL
 Btw, was Nvidia's "fully optimised" version done in PTX? I thought that was just high level stuff.
Btw, was Nvidia's "fully optimised" version done in PTX? I thought that was just high level stuff.Btw, was Nvidia's "fully optimised" version done in PTX?
It wouldn't matter as the 4870 surpasses the theoretical maximum nV FLOPS for MM.
It wouldn't matter as the 4870 surpasses the theoretical maximum nV FLOPS for MM.
Yep, and every time this topic comes up we get examples of very specific highly tuned algorithms with no dynamic branching doing well on AMD hardware. Still waiting on more complete applications to emerge that showcase all these flops. It could be that AMD's development environment just sucks but I don't know enough about it to say for sure.
That's why I mentioned OpenCL previously, hopefully we'll get more real apps that run on AMD's stuff so we can make easier comparisons.
Jawed
Legend
You're trying to tell me that code written for NVidia wasn't hand-tuned (and why are you using that term pejoratively - it's the norm for performance-critical applications)?Sure, pick the example that has no dynamic branching and was hand tuned in IL
And prundetree's work wasn't done with IL, but a custom front-end he's built for his own use. No different from people who build a Python front end for NVidia, I guess.
Jawed
Jawed
Legend
Do you have examples of dynamic branching at high performance on NVidia?Yep, and every time this topic comes up we get examples of very specific highly tuned algorithms with no dynamic branching doing well on AMD hardware.
Jawed
Do you have examples of dynamic branching at high performance on NVidia?
Jawed
Optix? /shrug
DegustatoR
Legend
That's an awful lot of things to stay unchanged, don't you think?Well still using shader clusters with a couple SP units, some DP units, TMU grouped together, with the ALUs running at higher clock, and unlike ATI still with scalar ALUs. Though if it's really using MIMD won't that actually decrease performance per die area further (at least for graphics)?
I believe that while NV will most surely stay with the same design basics (i.e. they won't switch to superscalars or go for the TU pool a la R5x0) we may see that the same design ideas can be implemented very differently in h/w.
Shrink GT200 on 40nm to sub 400mm2, fight 5850 with it? GT212 relives?Why worry talking about a card that's 9 months out when we should focus on the card that comes out in 3?
DegustatoR
Legend
This number is wrong.
So I guess its sooner than later. Still its not GT300 Deg.This number is wrong.
Why?I think NVIDIA needs about 20-30% faster GPU to be successful.
- Status
- Not open for further replies.