D
Deleted member 13524
Guest
No, I'm saying Sony showed specifics on the hardware architecture (zlib+kraken hardware decompressor, dual co-processors, ESRAM, coherency engines, etc.) and how that led to very specific performance figures using specific compression formats, and then they showed videogames taking advantage of the final hardware -> it's working right now.Okay, so you are saying that Nvidia is lying. Or at least being quite deceitful in it's claims about RTX IO performance. And you're basing this conclusion on.... pure speculation. So not a technical discussion anymore then.
nVidia showed two slides saying "lulz we'll just do it on GPGPU and use direct storage" and slapping a bar graph showing 2x maximum NVMe 4.0 throughput. Without even mentioning which compression formats they support -> it's not working right now.
So one of them was technical enough to allow a technical discussion over it, the other was not. And the problem is you're taking way too many conclusions from the lack of information nVidia is giving about RTX IO.
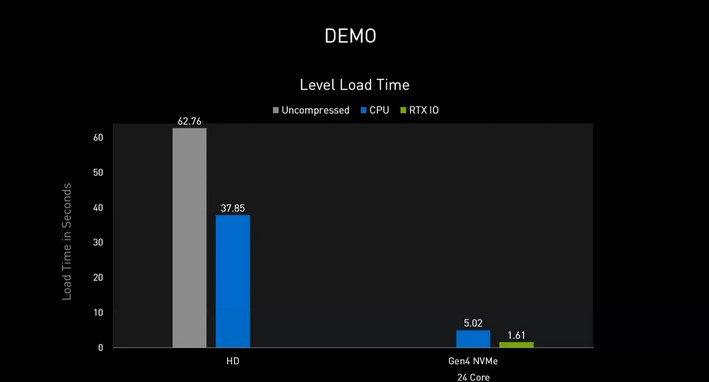
No, but one of them you have seen working and will be shipping in hardware+software within a month and a half. The other you may or may not see working by the end of 2022, depending on Microsoft launching a windows update that enables Direct Storage, and then on PC game developers having the time and resources to implement it.The comparison that is being made rightly compares the claimed compressed throughput from each vendor. Neither has actually demonstrated real world throughput measurements / benchmarks (showing short or zero load times in games where we have no idea how much data is being transferred doesn't tell us anything about transfer rates), yet you seem to be taking Sony's claims at face value while assuming Nvidia is being deceitful.
Your apparent claim that both implementations are somehow on par in what relates to TRL is just wrong. Sony has very little room to be deceitful whereas nvidia is at a point where they can be as deceitful as they want.
In fact, them not disclosing what compression format(s) they'll support to achieve 14GB/s can already be interpreted as a deceitful move.