Great discussion so far guys!
I would definitely want to have some kind of extension to write warp/wave wide scalar code in my shaders (just to be sure that everything goes as planned).
Not to get too far off track here, but while I agree that expressing different frequencies of execution is important going forward, I don't think bandaging on "warp-wide" commands, "dynamically uniform" concepts and other breaks of the conceptual independent execution mode is the right solution. Something like what ISPC does makes a hell of a lot more sense... allow the shader code to be parameterized on the SIMD width and have the "loops" and synchronization expressed in the user code itself.
Storing vertex data in general purpose buffers and fetching it from there in vertex shader isn't slow either.
I agree it's not "slow", but be careful generalizing current GCN design to other architectures. There are trade-offs made in latency hiding and such whenever you switch from "push" to "pull", and in vertex cases where you have a fair amount of gathers/reorganizing and AoS/SoA conversations going on. In the long run I think pulling vertex data is the way to go, but it's not true to categorically state that it's no worse today.
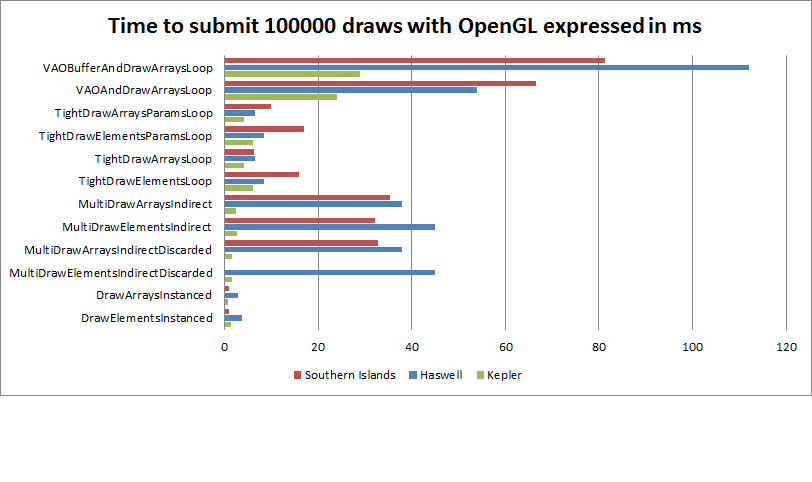
Of course you can still zero out the DrawArraysIndirectCommand struct's triangle counts (by GPU) for the excess draw calls (just assume a million draws every time). This however doesn't save GPU time much (confirmed by Riccio's measurements).
I saw some curious behavior with this on NVIDIA recently where it seemed like it might actually be reading the buffer back to the CPU anyways and doing the setup/loop there. Zeroing everything was way faster than a GPU frontend would be able to do it, and the runtime debugging stuff noted a read-back of the relevant buffer from GPU -> host on the MultiDrawIndirect call... Not sure it would always do this even if it involved generating a stall (in this case the data was dumped from the CPU anyways), but it was still a little worrying in terms of the whether the mechanism is actually doing what is intended to.
Alas you always have this sort of problem with 3D APIs... driver writers tend to have license to reinterpret whatever API calls they want in the name of "optimization". Hard to fight the market forces behind that one though.
Overall, I think that making each and every API call as cheap as possible and setting things up so that you can run on multiple CPU cores and such is fundamentally not a forward looking approach to high performance graphics.
Welcome to B3D Graham! Glad to have you in the discussion here.
As to your note, I spoke to this a bit in the Mantle thread. While I think it's fine and a worthwhile exercise to lower the overhead of submission as much as possible (remember, every bit helps on power-constrained devices and SoCs), when people start talking about millions of draw calls you do have to start asking some questions about the entire submission model. i.e. why are we creating these systems where you go wide parallel to construct a command buffer that then gets consumed serially by the GPU frontend before it goes wide parallel again? I wonder where the bottleneck is going to be eventually guys...
")
We need to get graphics state out of physical registers (which are a limited and expensive hardware resource) and into memory (which is effectively free).
Yes I think this will be forced by a number of trends, including better pre-emption, shared virtual memory, user space submission, etc. Most GPUs are arguably already more like this than the APIs would have you think right now, but it's worth noting that there's still a bit of a mine-field on which architectures read which things from memory, pipeline which state, etc. Creating a portable API will by necessity involve some compromises in the short term.
Once the state vector is in memory, filling it in is just writing data into a GPU-visible buffer, and no API is required at all. The fastest code is the code that never executes.
It is worth noting that pulling state from memory comes with some additional overhead in terms of latency hiding. You typically need somewhat more hardware threads and registers when you have to launch a shader, *then* go off and look up its inputs, then come back to it. It's not usually a huge deal, but it's more pressure on those aspects than being able to push data into registers before even launching the kernels. We've already done this transition to some extent with constant registers -> constant buffers though and it didn't kill us, so it's certainly doable
Just want to note it's not completely free.
For example, it's probably fine to leave blending on (GL_ADD, GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA) so long as you can guarantee that opaque fragments have an alpha value of one.
Getting architecture specific there, but yeah
That said, I don't think blending is a big deal TBH... you almost always want to render all your opaque stuff first, then blended stuff. Two draw indirect calls vs. one = meh
Same with render targets... these are low frequency changes that should not be a problem even on current APIs.
While it's possible to image some uses for high frequency render target changes (rendering multiple shadow cascades, cube faces, voxels, kniss-green-style volume half-angle rendering), many of them involve cache thrashing or complex synchronization that wouldn't be that efficient anyways. People have played with GS-driven viewport index stuff to do this today and it usually doesn't end up being great. And no, it's not simply because "GS is slow"
The beauty of the data-driven GPU paradigm is that the GPU can produce its own data. The low hanging fruit is simply to walk the scene graph on the CPU, stuff parameters in a buffer and throw it at the GPU. However, the exciting part is moving that scene traversal (or even generation) onto the GPU. Culling in a VS is fun. Generate vertex data in a compute shader, stuff references to to it into an indirect draw buffer and then dispatch the list - procedurally generated forest, anyone?
Eliminating state brings us nearer to GPU-driven rendering and I think that's definitely a part of the future. On the other hand though, there's still stuff that a CPU does better (more power-efficiently) and I want to be able to bounce around to where things are the most appropriate. Thus another part of the ideal future IMO is a move away from huge buffering of graphics commands. I don't see a fundamental reason that we can't get graphics submission entirely into user space with a granularity down to the range of <1ms "command buffers" and remain efficient on the GPU side, which opens a lot of doors in terms of heterogeneous computing. This sort of thing is going to be necessary to do a good job of VR anyways, so I think it's generally a reasonable direction to go as well.
I really do want both tools though - GPU fork/join/self-dispatch (for graphics, not just compute) and lower-overhead and latency dispatch from the CPU. All this multi-frame buffering of ~50ms+ needs to go away.
I'll stay out of the deferred shading conversation... sebbbi already covered everything I would have said
Suffice it to say there are still plenty of reasons to do it and I don't see that changing in the near future.