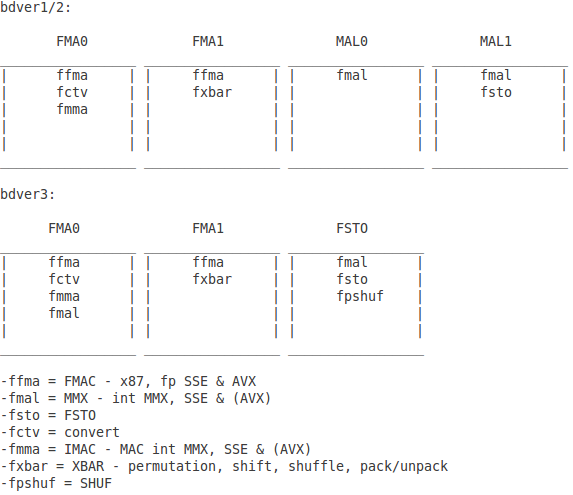
Gotcha. SIMD/FPU takes a small step back this gen but that's understandable since steamroller is designed to go into a consumer APU.
I think some of the best case for integer SIMD is software media codecs, which is still in the consumer fold. The hardware/GPU media paths tend to have tradeoffs in quality.
I'm also wondering how quick and easy it would be to use the GPU for floating point work, whether a compiler could be written which would know how to automatically utilize the GPU for certain types of floating point work or whether they'll have a math kernel library for GPU work now. I haven't heard of any new instructions for Kaveri yet which must be necessary for issuing commands to the GPU and memory handling by the GPU.
In theory, HSA and specialized APIs can help with this, however it is not transparent and it's not clear how much can be done on the fly.
I'm not feeling confident that Steamroller or GCN are where they need to be for the GPU to make up for the FPU.
Barring some unforseen dynamic routing, Kaveri is going to look like a weaker Richland.
Barring some advance in the wide gulf in latency, SIMD granularity, and cache behavior of the CPU and GPU, there's going to be a swath of workloads that do not do well on the GPU.
For heterogenous loads, there will be those with latency requirements or mediocre speedups that cannot tolerate the overhead of hopping between the sides.
Then there's all the software that was and will not be coded specially for a minority holder of the x86 market.
Those just get the non-improvement of Kaveri.
I suppose we'll have to see how much will fall in each bucket.
I guess what I'm asking what exactly makes Kaveri easier to program than Trinity from the perspective of a higher level language? Is it just faster, are debugging tools better?
There is hardware support for queueing and memory sharing.
The GPU architecture is potentially no longer in the "downright unacceptable" category.
") The GPU side sounds like it's in the right ballpark for performance, I'm mainly surprised by the CPU part (but admittedly am kind of a BD/PD noob). There the raw Gflops difference is much more significant IMO.
The GPU side sounds like it's in the right ballpark for performance, I'm mainly surprised by the CPU part (but admittedly am kind of a BD/PD noob). There the raw Gflops difference is much more significant IMO.