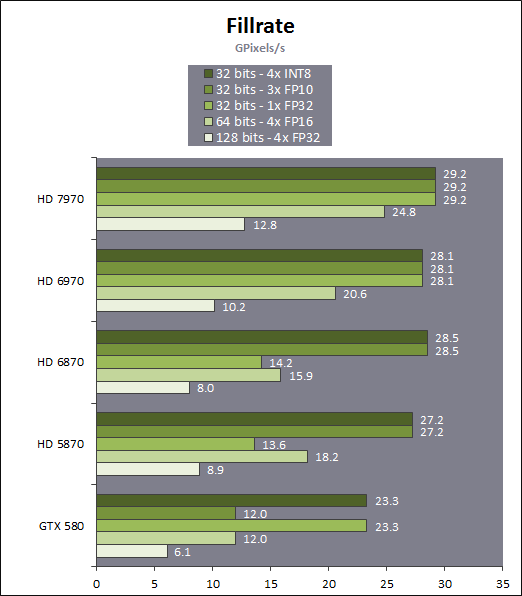
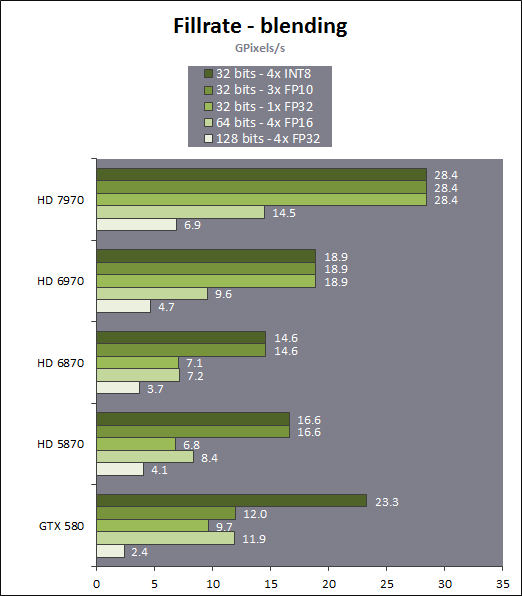
HiZ is an early Z optimization technique. It occurs before the pixel shader. If you wanted to do per pixel early Z culling, you would need to read the Z-buffer pixels from the memory before spawning the pixel shader threads. HiZ on the other hand is just a small optimization structure. It doesn't require memory accesses (can be kept on chip) as it has coarse resolution and coarse bit depth. I don't know if new PC hardware has other early Z functionality besides HiZ. It's entirely possible, if the chip can hide the latency of fetching depth values before executing the pixel shader. But if there's a mechanism for perfect 1:1 pixel based early depth culling, the same mechanisms could be likely adapted for programmable blending as well (fetch both pixel depth and color before spawning the pixel threads, and feed the color as pixel shader input = programmable blending).I thought both AMD and Nvidia have something like early Z rejection? If the pixel shader doesn't modify the Z (and some other boundary condition wrt alpha, I suppose) then it should be able to drop pixels completely if it can be declared up front that it won't be visible.
Pixel shader calculates pixel alpha value, so early alpha culling is not possible (you always need to run the shader). Stencil and depth are the only values that are known before the pixel shader (unless pixel shader writes to oDepth).
Last edited by a moderator: