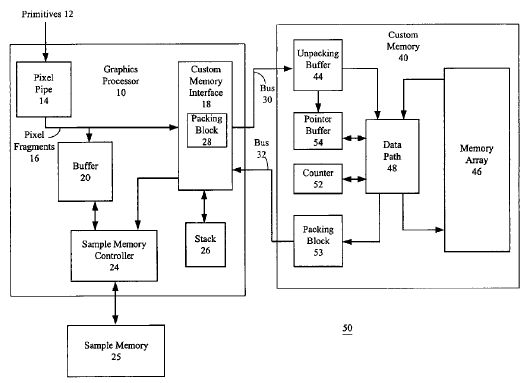
The way MS is calculating is simple: two quads with 32bit color read and write (blending) and Z-stencil test and write with 4xMSAA at 500MHz.
2 * 4 * (4 + 4 [read] + 4 + 4 [write]) * 4 * 500M = 256GB/s
This however is a bit misleading on several levels. First, do they mean bandwidth between the two chips, or bandwidth from ROPs to memory like in "traditional" architectures? Presumably the former, but that isn't comparable to external memory bandwidth figures.
Assuming they mean bandwidth between the two chips...
color and Z data is never read across that connection, because only the ROPs need this data. For the same reason, stencil data is neither read nor written, because a fragment has no associated "stencil data", that only exists in the framebuffer.
Furthermore, color data is identical for all samples in a pixel and Z data can be encoded as gradient per quad. The only thing that's needed additionally for AA is a coverage mask.
So disabling blending, Z-test, Z-writes, stencil test, stencil writes, or AA practically "saves" no bandwidth - the connection can be considered a multitude of dedicated channels.
Overall, what is required per quad are 4* 32bit color, compressed Z (3 * 24bit at most) and 4* 4bit of coverage mask, meaning less or equal to 216bit per quad. And since there may be two quads per clock with color, that's at most 432bit required for the connection between the two chips, which equals 27GB/s.
Assuming they mean bandwidth from ROPs to the memory array...
then 64bit (32bit color + 31bit Z/stencil + 1bit flag) need to be read and written per pixel. That means 512bit for reads and writes each are required, equalling 32GB/s for reads and 32GB/s for writes.
(That's the best case with no additional AA samples involved. If that happens, additional bandwidth to sample memory is required)
If you want to compare "effective bandwidth" figures, take a X850XTPE that has 6:1 color compression and 24:1 Z compression when 6xAA is enabled, which means 9.6:1 compression rate overall for the framebuffer. That's 362.5GB/s "effective" if you could use up all bandwidth for the framebuffer. And 256GB/s if 70% is used for framebuffer access.
P.S. don't take that last paragraph too seriously.
")
R480 can't even output that many compressible quads with 6xAA...