CoolAsAMoose
Newcomer
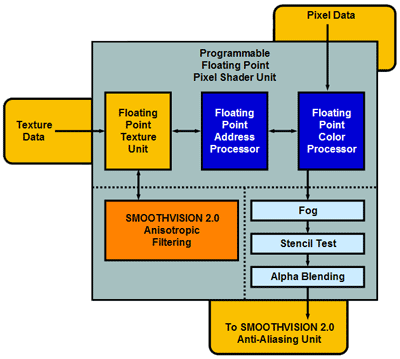
I have seen some concern over the omission of a second TMU/pipeline in the R300. Maybe I am mistaken, but isn't the whole idea of the pixel shader that you should "program" effects that in earlier HW required multiple textures. This means it makes no sense at all talking about dual TMUs/pipeline in a DX9-chip (if performance on old software is not of big concern, that is). Am I mistaken?
So what is the next step in pixel-parallelism? Besides moving to 16 pipelines, I would say a super-scalar pixel shader capable of executing multiple pixel shader instructions in parallel. Or is pixel shader instructions always ackumulative, making parellel execution of them impossible?
Please help enlighten me!
So what is the next step in pixel-parallelism? Besides moving to 16 pipelines, I would say a super-scalar pixel shader capable of executing multiple pixel shader instructions in parallel. Or is pixel shader instructions always ackumulative, making parellel execution of them impossible?
Please help enlighten me!
")