You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Cell's PPE and Xenon compared.
- Thread starter ADEX
- Start date

Jawed
Legend
I've been trying to think why bother with a DP pipeline, if, as everyone says, you can do enough MADDs in the same time.darkblu said:jawed,
dp is strictly horizontal. if you had a vertical dp (i.e. multi-vector dp) that would have been a madd/macc, not a dp.
Now I'm thinking that you can't do the MADDs in the same time. It's occurred to me that these floating point pipelines (Cell/Xenon VMX or SPE) can only issue one MADD per clock. Although all these architectures can dual-issue floating point instructions, the other instruction has to be a load/store/permute.
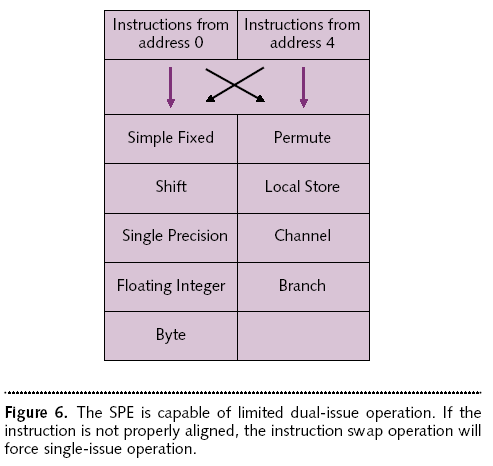
From the MPR article on Cell.
On that basis, a dedicated DP pipeline makes sense, doesn't it
Jawed
Do misaligned instructions occur often enough in the instruction stream to warrant the extra expenditure in resources to build a dedicated DP unit into the processor?Jawed said:From the MPR article on Cell.
On that basis, a dedicated DP pipeline makes sense, doesn't it
Seems not, from looking at what was actually built, rather than compared to peoples' preferred ideal wet dream architecture...
")
overclocked
Veteran
Jawed has the integer/FP pipelines of PPE and/or XeCpu been publict known or are your numbers from any other sources or just a guess?
Jawed
Legend
Look at the second photograph:
http://www.beyond3d.com/forum/showthread.php?t=23361
That's the entire pipeline for Xenon.
The entire pipeline for SPE is also known (MPR article from Feb):
http://www-306.ibm.com/chips/techlib/techlib.nsf/techdocs/D9439D04EA9B080B87256FC00075CC2D/$file/MPR-Cell-details-article-021405.pdf
SPE pipeline is also here:
http://www.research.ibm.com/people/a/ashwini/E3%202005%20Cell%20Blade%20reports/All_About_Cell_Cool_Chips_Final.pdf
page 18. I expect there are other documents too.
Pages 19 and 20 describe PPE. But the floating point portion of the pipeline is missing in action, sadly. I don't know of any document that describes the entire PPE pipeline.
Jawed
http://www.beyond3d.com/forum/showthread.php?t=23361
That's the entire pipeline for Xenon.
The entire pipeline for SPE is also known (MPR article from Feb):
http://www-306.ibm.com/chips/techlib/techlib.nsf/techdocs/D9439D04EA9B080B87256FC00075CC2D/$file/MPR-Cell-details-article-021405.pdf
SPE pipeline is also here:
http://www.research.ibm.com/people/a/ashwini/E3%202005%20Cell%20Blade%20reports/All_About_Cell_Cool_Chips_Final.pdf
page 18. I expect there are other documents too.
Pages 19 and 20 describe PPE. But the floating point portion of the pipeline is missing in action, sadly. I don't know of any document that describes the entire PPE pipeline.
Jawed
Jawed said:Pages 19 and 20 describe PPE. But the floating point portion of the pipeline is missing in action, sadly. I don't know of any document that describes the entire PPE pipeline.
Jawed
Because DD2 is under NDA.
How's DD2 NDA'd if IBM have 'open-sourced' Cell's tech specs?
Jawed said:I've been trying to think why bother with a DP pipeline, if, as everyone says, you can do enough MADDs in the same time.
when you want to get your dp calculated in minimal time once you have your single vector of interest available, especially if you have little [ed: but equally important] other work to do simultaneously with that. OTH, if you don't have such requirement you may not have a reason for using dp and especially if you want multiple dp's you would decompose that into madds and intermingle them with the rest of the stuff. so basically a dp op is useful when you want to get the dp of a single vector ASAP. that happens rather often in game physics and other higher logic code. as you notice a dedicated dp pipeline makes perfect sense in this case.
ed: early morning posts.. ok, i just realised the above does not quite answer your original question, rather elaborates on the reasoning to an answer. the answer actually is: a dp op and multiple madd op's are (likely) not equal in one aspect: latency. a dedicated dp pipeline would allow for carrying out a single dp with minimal latency, whereas a madd implementation would provide higher throughput. now go to the first paragraph ; )
Last edited by a moderator:
Guden Oden said:Do misaligned instructions occur often enough in the instruction stream to warrant the extra expenditure in resources to build a dedicated DP unit into the processor?
Seems not, from looking at what was actually built, rather than compared to peoples' preferred ideal wet dream architecture...
DP is probably the single most common vector instruction in or outside graphics, providing it as a core instruction, reduces code size and like increases execution speed, on a lot of game code.
Last edited by a moderator:
Jawed
Legend
Sentence seems mangled - are you saying "reduces code size and likely increases execution time, on a lot of game code" or "decreases"?ERP said:DP is probably the single most common vector instruction in or outside graphics, providing it as a core instruction, reduces code size and like increases execution time, on a lot of game code.
Jawed
I get what you're saying, but didn't IBM state DP was difficult to implement in high-speed FPUs, at least without it getting very expensive hardware-wise?ERP said:DP is probably the single most common vector instruction in or outside graphics, providing it as a core instruction, reduces code size and like increases execution time, on a lot of game code.
It's one thing what's really convenient for programmers, and another what's realistic to implement unfortunately - much to the chagrin of all hardware geeks.
Guden Oden said:I get what you're saying, but didn't IBM state DP was difficult to implement in high-speed FPUs, at least without it getting very expensive hardware-wise?
It's one thing what's really convenient for programmers, and another what's realistic to implement unfortunately - much to the chagrin of all hardware geeks.
I edited the original response to make it clearer.
My guess is that it is expensive to implement from a hardware standpoint, as has been previously mentioned it's a horizontal op.
However the question is what that cost buys you in convenience and execution speed. MS obviously thought it was worth the cost, but then they are a software company, Sony didn't. On the platforms I've used with it, it's been a great addition, since I don't know the relative cost I can't comment usefully on any utility vs cost metric.
A lot of the differences I see between Sony and MS can be attributed to the software/hardware company mentality.
Jawed
Legend
Seems like M$ asked IBM to disregard the hardware expense and make a seriously long pipeline...Guden Oden said:I get what you're saying, but didn't IBM state DP was difficult to implement in high-speed FPUs, at least without it getting very expensive hardware-wise?
Sort of similar to the hardware expense of the 128 registers.
I suppose if you chuck OoOE then that frees up a lot of transistors - and M$ is presumably taking the gamble that they can create an extremely well-tuned compiler for Xenon.
Jawed
Jawed said:So, is this DP faster or slower than executing a DP as MADDs?
Jawed
Depends if you can group them into sets of 4 trivially, cost should be more or less the same in that case. In graphics it's usually not very hard to do the grouping, in other areas it can be difficult or impossible.
This is why in general peak numbers have no real bearing on real numbers.
Jawed
Legend
ERP said:Depends if you can group them into sets of 4 trivially, cost should be more or less the same in that case. In graphics it's usually not very hard to do the grouping, in other areas it can be difficult or impossible.
This is why in general peak numbers have no real bearing on real numbers.
Sorry for the quick edit - but you leapt in with good info anyway.
Jawed
blakjedi said:
I just mean can you rewrite the code such that you can do 4 dot products simultaneously, if you can and you can organise the data in the right way then doing MAD's instead of DotProducts is basically equivalent.
If you can't or you can't organise the data efficiently for the MAD instructions then the Dot Products will be more compact and faster.
In the case of most graphics code this is relatively easy to do in the case of more general code it isn't.
Programmers only have 2 type of problem they solve trivial and hard, or maybe that's just me
Similar threads
- Replies
- 21
- Views
- 9K
- Replies
- 52
- Views
- 24K
- Replies
- 28
- Views
- 11K
- Replies
- 10
- Views
- 3K