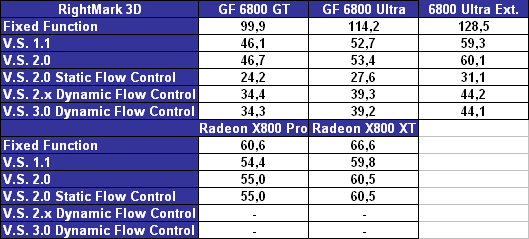
Digit-Life's review, like all their reviews is posted annoyingly on a single, massive page. However, they tend to do some synthetic benchmarks that other sites don't, making for some interesting browsing. The following benchmark intrigues me the most:
http://www.ixbt.com/video2/images/r420xt/gps-3diffuse+specular.png
What I'd like to point out is ATI's and NVidia's branching implementations. Obviously there's some fundamental difference between the two that leads to NVidia receiving quite a significant performance penalty. I'm wondering just what that is. . .
The thought had occured to me that ATI is expanding loops. Since they're static, this makes sense and would be relatively easy to do when compiling the shader. However, if that were the case, there is no way they could achieve the maximum 65k instruction limit they advertise. AFAIK, that number is really the number of instructions that can be executed including loops -- the maximum number instruction count of a vertex shader being far less. As such, if that isn't the solution, then what is?
http://www.ixbt.com/video2/images/r420xt/gps-3diffuse+specular.png
What I'd like to point out is ATI's and NVidia's branching implementations. Obviously there's some fundamental difference between the two that leads to NVidia receiving quite a significant performance penalty. I'm wondering just what that is. . .
The thought had occured to me that ATI is expanding loops. Since they're static, this makes sense and would be relatively easy to do when compiling the shader. However, if that were the case, there is no way they could achieve the maximum 65k instruction limit they advertise. AFAIK, that number is really the number of instructions that can be executed including loops -- the maximum number instruction count of a vertex shader being far less. As such, if that isn't the solution, then what is?
")