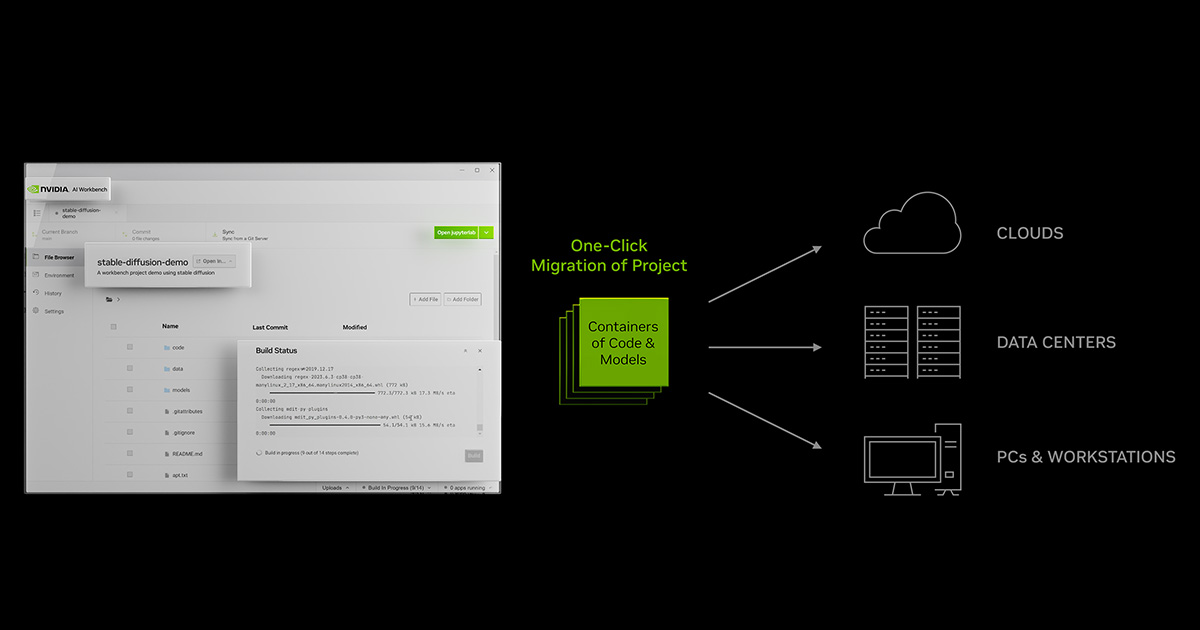
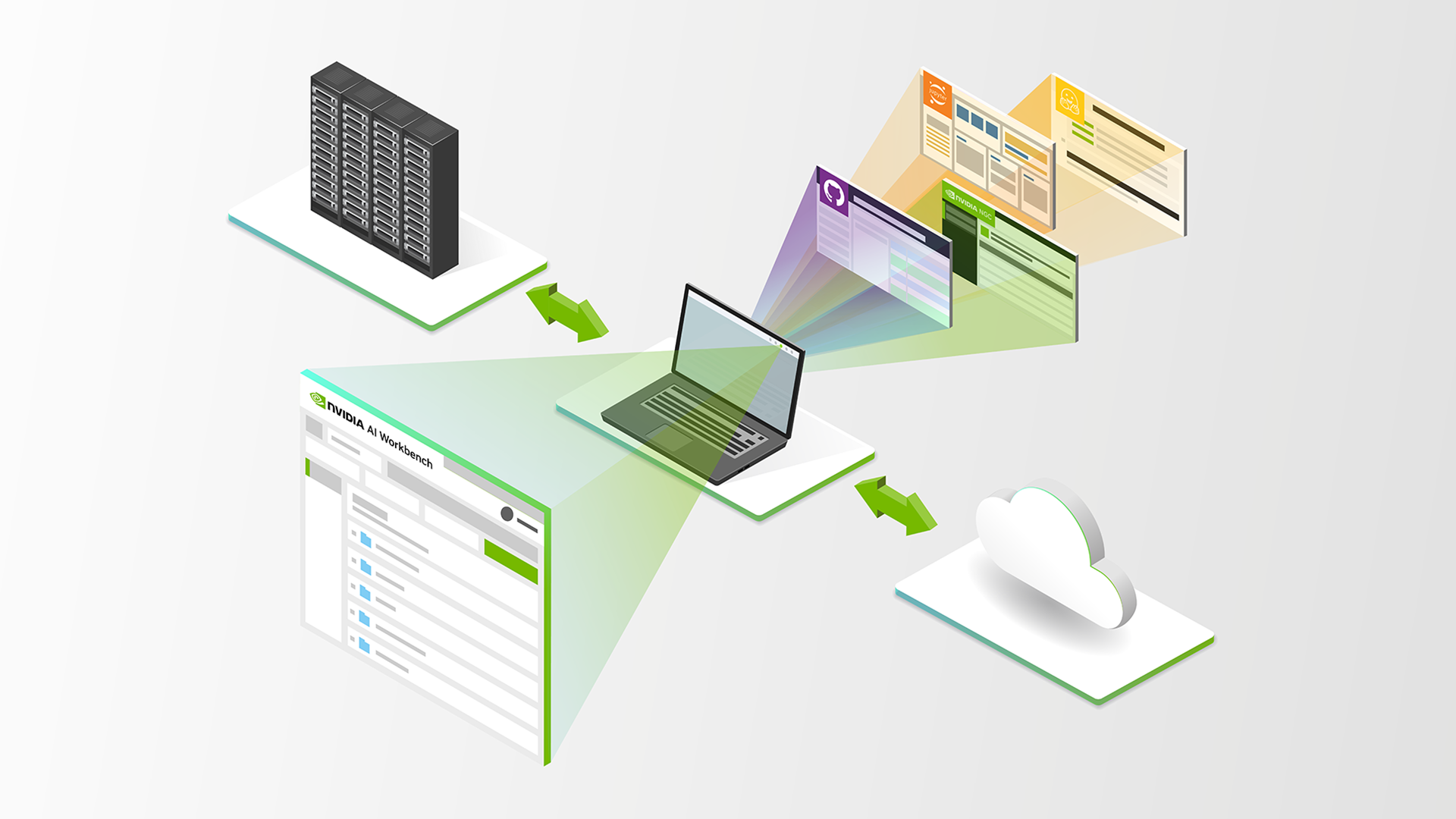
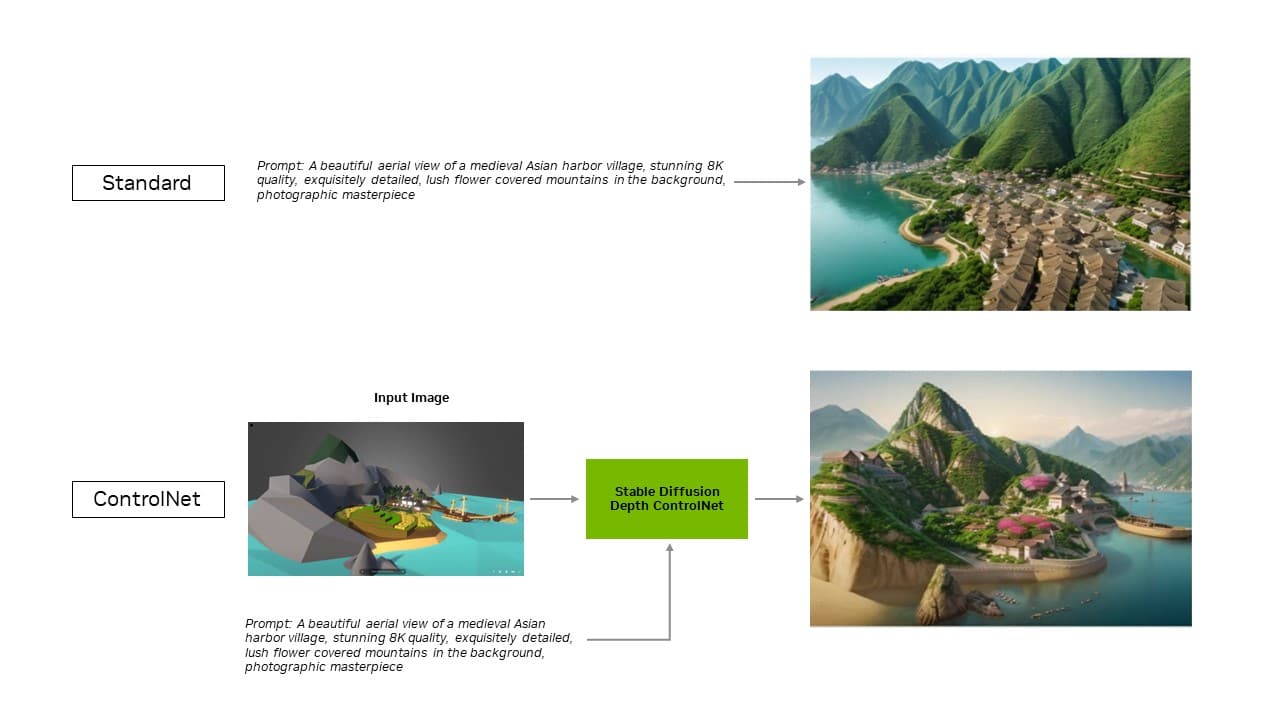
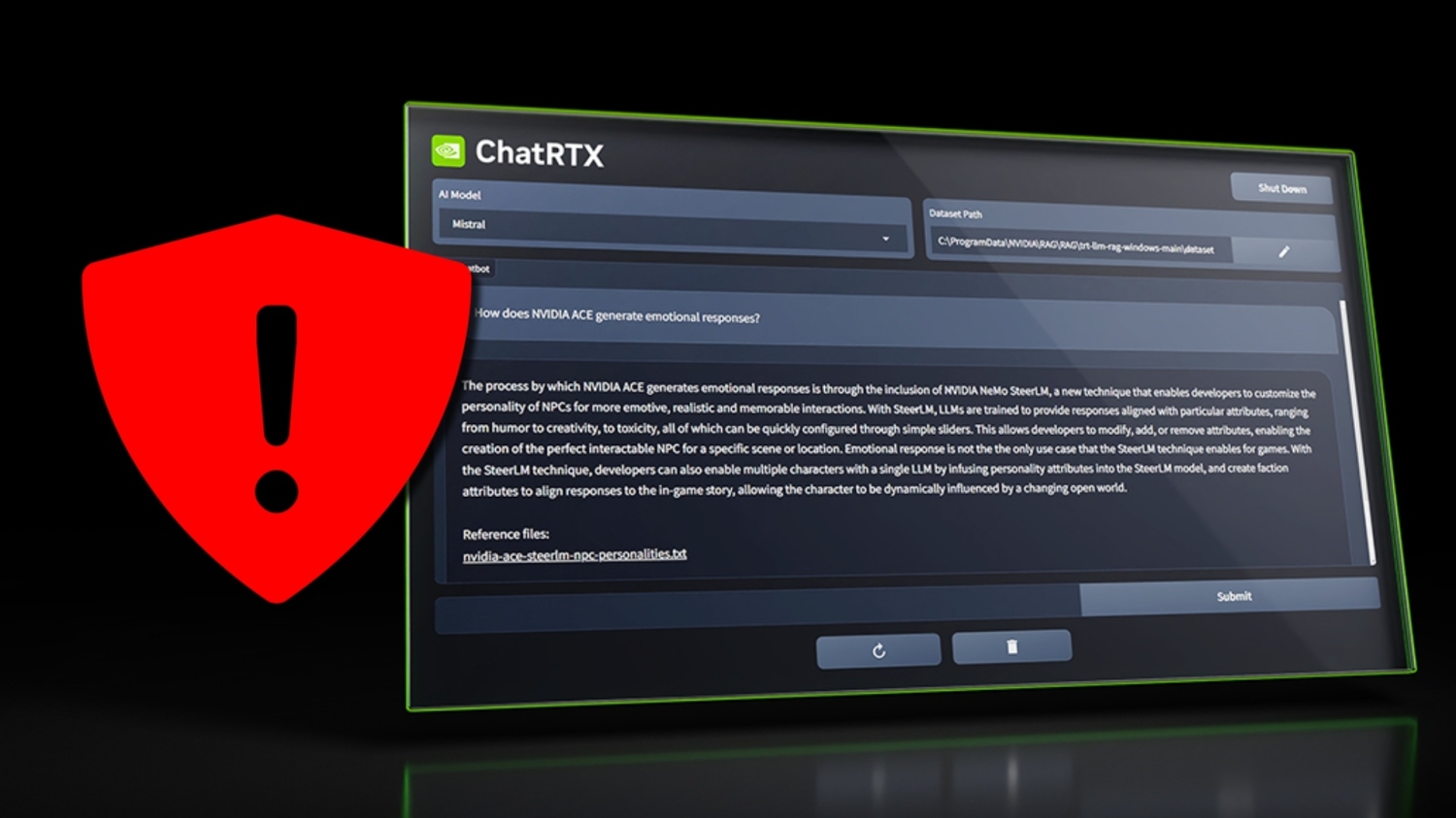
Google has also put a price on using its Gemini API and cut off most of its free access to its APIs. The message is clear: the party is over for developers looking for AI freebies, and Google wants to make money off AI tools such as Gemini.
Google provided developers free access to its older and newer APIs to its LLMs. Free access was an attempt to woo developers to adopt its AI products.
...
Google is attracting developers via its cloud service and AI Studio service. For now, developers can get free API keys on Google’s website, which provides access to Google’s LLMs through a chatbot interface. Developers and users have until now enjoyed free access to Google’s LLMs, but that is also ending.
This week, Google threw a double whammy that effectively shuts down free access to its APIs via AI studio.
...
Google also announced this week that it is restricting API access to its Google Gemini model in a bid to turn free users into paid customers. Free access to Gemini allowed many companies to offer chatbots based on the LLM for free, but Google’s changes will likely mean many of those chatbots will shut down.
“Pay-as-you-go pricing for the Gemini API will be introduced,” Google said in an email on Monday to developers.
The
free plan includes two requests per minute, 32,000 tokens per minute, and a maximum of 50 requests per day. However,
one drawback is that Google will use chatbot responses to improve its products, which purportedly include its LLMs.
...
The hundreds of billions spent in data centers to run AI is a gamble, as the companies do not have proven AI revenue models. As the use of the LLMs grows, small revenue streams through offerings like APIs could contribute to the cost of building the hardware and data centers.
Bloomberg
recently reported that Amazon was spending $150 billion over 15 years to establish new data centers.
OpenAI and Microsoft plan to spend $100 billion on a supercomputer called Stargate, according to
The Information.
For customers unwilling to pay, Google has released the Gemma large language models, around which customers can build their own AI applications. Other open-source models, such as Mistral, are also gaining in popularity.
Customers are leaning toward open-source LLMs as the cost of AI grows.
These models can be downloaded and run on custom hardware that is tuned to run the applications, but most can’t afford the hardware, which in most cases is Nvidia’s GPUs. AI hardware is also not easily available off the shelf.