DavidGraham
Veteran
The NVL4 is a special variant of GB200, the base model of GB200 has only 2 B200 GPUs. Now the base model of GB300 has 4 B300 GPUs.How is this any different to the GB200 NVL4?
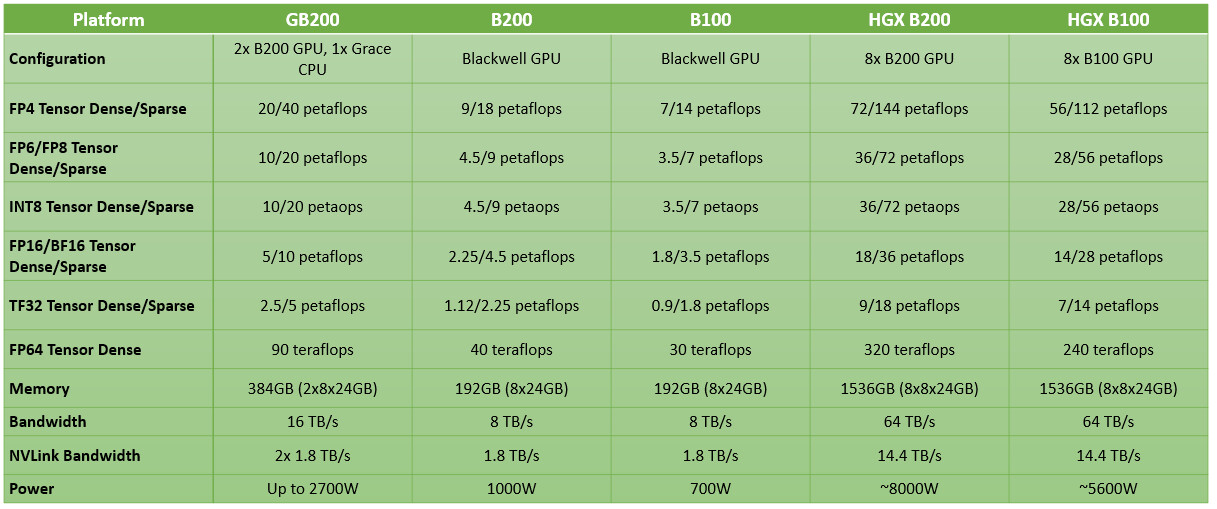
Unwrapping the NVIDIA B200 and GB200 AI GPU Announcements
NVIDIA on Monday, at the 2024 GTC conference, unveiled the "Blackwell" B200 and GB200 AI GPUs. These are designed to offer an incredible 5X the AI inferencing performance gain over the current-gen "Hopper" H100, and come with four times the on-package memory. The B200 "Blackwell" is the largest...
On other news, Mediatek will have access to NVIDIA IP (NVLink and routers/modems) for it's ASIC business.


