I'm not sure why the blog post claims ExecuteIndirect will be soft-deprecated.
Why would you use the ExecuteIndirect (or standardized Vulkan device generated commands) API when Work Graphs with mesh nodes can provide so MUCH MORE with the PSO swapping capability ? You can change shaders and pipeline states (which are included in the PSO swapping functionality) from the GPU timeline
in addition to being able to change the indirect draw/dispatch arguments, root signature/constants, or the index/vertex buffer bindings ...
Work Graphs aren't compatible with RT pipelines but who really cares about doing GPU-driven RT pipelines when CPU overhead is hardly the concern over there ? Wouldn't end users prefer to exploit the potential of the GPU being able to perform
faster graphics state changes as opposed to having the CPU compile EVERY unique combinatorial variants of PSOs ?
AFAIC, Work Graphs w/ mesh nodes is just Microsoft porting over Xbox specific extensions to it's ExecuteIndirect API implementation on PC ...
On a related note, what are the advantages and disadvantages of work graphs versus callable shaders as mechanisms for one shader to request the execution of another? Is there a particular technical reason why callable shaders are for the RT pipeline only and work graphs only support compute and mesh nodes? My understanding is that callable shaders are more flexible than work graphs, but does that flexibility come at a performance cost?
Callable shaders and Work Graphs don't necessarily compete with each other ...
Callable shaders are mutually exclusive to RT pipelines because a Microsoft
representative is near absolutely
insistent that GPUs will never have true (general purpose & not exclusive to a specific PSO model) function calls that are performant. Having callable shader restricted to RT PSOs allows GPU compilers to apply inling optimizations more easily ...
RT nodes can't exist within Work Graphs because DXR pipeline's stack-based model clashes with the feed-forward model of Work Graphs. With Work Graphs, recursion is limited to a single node by design since you can't revisit any prior nodes/shaders during execution. With DXR, you can't do arbitrary work amplification as seen with either amplficiation shaders or Work Graphs so the number of threads declared at the start of execution must match at the end of execution ...
Work Graphs execution model can be sort of described as an unhinged in between combination amplification shaders and DXR/RT pipelines ...


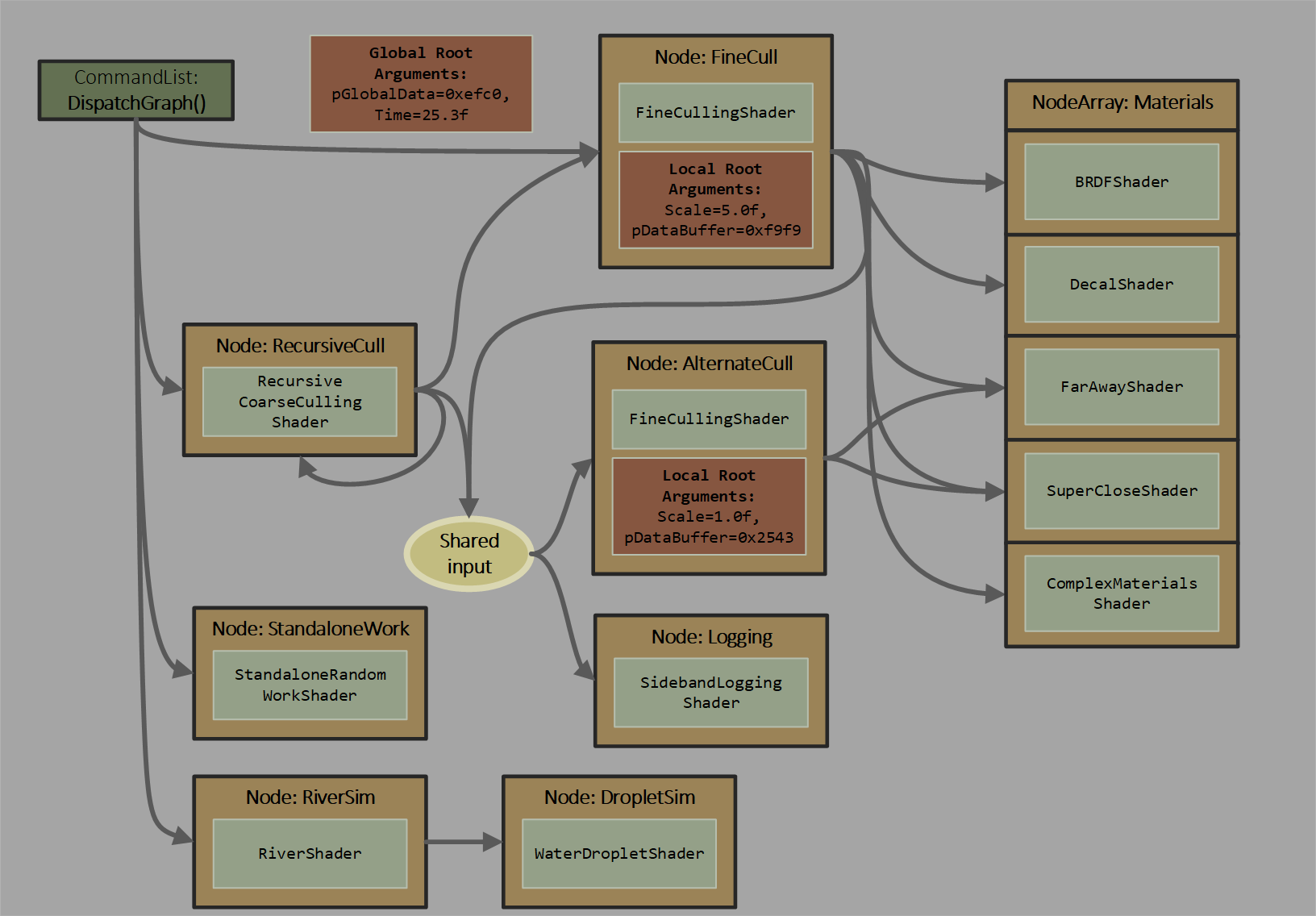




")
 but I don't think that's the reason.
but I don't think that's the reason.