
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Blazing Fast NVMEs and Direct Storage API for PCs *spawn*
- Thread starter DavidGraham
- Start date
https://devblogs.microsoft.com/directx/directstorage-is-coming-to-pc/a
also MS confirmed that a new update of Windows 10 is going to add those features soon
- Today, Microsoft announced they're bringing a part of this revolutionary Architecture to Windows gaming PC's.
- DirectStorage will massively reduce load times for games, allowing PC games to more effectively use high-speed storage solutions.
- If you have a speedy SSD and a game supports DirectStorage, load and wait times will be much shorter.
It does this in several ways: by reducing per-request NVMe overhead, enabling batched many-at-a-time parallel IO requests which can be efficiently fed to the GPU, and giving games finer grain control over when they get notified of IO request completion instead of having to react to every tiny IO completion.
Why NVMe?
NVMe devices are not only extremely high bandwidth SSD based devices, but they also have hardware data access pipes called NVMe queues which are particularly suited to gaming workloads. To get data off the drive, an OS submits a request to the drive and data is delivered to the app via these queues. An NVMe device can have multiple queues and each queue can contain many requests at a time. This is a perfect match to the parallel and batched nature of modern gaming workloads. The DirectStorage programming model essentially gives developers direct control over that highly optimized hardware.
In addition, existing storage APIs also incur a lot of ‘extra steps’ between an application making an IO request and the request being fulfilled by the storage device, resulting in unnecessary request overhead. These extra steps can be things like data transformations needed during certain parts of normal IO operation. However, these steps aren’t required for every IO request on every NVMe drive on every gaming machine. With a supported NVMe drive and properly configured gaming machine, DirectStorage will be able to detect up front that these extra steps are not required and skip all the necessary checks/operations making every IO request cheaper to fulfill.
For these reasons, NVMe is the storage technology of choice for DirectStorage and high-performance next generation gaming IO.
really interesting
Well not everything is about tflops.
Well, the SSD tech for pc's seems darn impressive, however we put it.
It seems like you need an nvme drive. Not sure if it has to be pci-e 4 and higher or if the older ones will do it.Well, the SSD tech for pc's seems darn impressive, however we put it.
Other than DirectStorage support, isn't this something AMD's HBCC offered years ago, GPU direct access to storage medium(s)?Well, the SSD tech for pc's seems darn impressive, however we put it.
It seems like you need an nvme drive. Not sure if it has to be pci-e 4 and higher or if the older ones will do it.
Well, i don't think anyone would expect anything different
") I think you need a rather modern pc ofcourse.
I think you need a rather modern pc ofcourse.Other than DirectStorage support, isn't this something AMD's HBCC offered years ago, GPU direct access to storage medium(s)?
Perhaps, refined and designed for the gamer/consumer market.
D
Deleted member 13524
Guest
I think you only focused on the second part of my post.Why do you say this?
If the Turing support for RTX IO is the same as Ampere's, then there's no dedicated hardware for data decompression on Ampere and both architectures are using just the shader ALUs.
If there is no dedicated hardware for data decompression then we shouldn't expect performance similar to the new consoles. If GPU compute shaders were great for data decompression then microsoft or sony wouldn't bother themselves with dedicated units, as compute shaders serve additional functionality over fixed function hardware.
The alternative to this is Ampere has dedicated decompression hardware that Turing doesn't have, in which case we should expect very different IO performance between these two architectures (first half of my previous post).
Another alternative to this is Turing having secret sauce data decompression hardware hidden from us all this time, which I think it's very unlikely.
This is not related to you, but I'm not sure why my post made some people so defensive though. I thought it was "common sense" that the PC wouldn't have anything similar to the consoles on IO performance for a long time, short of the new GPUs getting fixed function hardware in the GPU SoC and a M.2 slot in the graphics card.
I think you only focused on the second part of my post.
If the Turing support for RTX IO is the same as Ampere's, then there's no dedicated hardware for data decompression on Ampere and both architectures are using just the shader ALUs.
If there is no dedicated hardware for data decompression then we shouldn't expect performance similar to the new consoles. If GPU compute shaders were great for data decompression then microsoft or sony wouldn't bother themselves with dedicated units, as compute shaders serve additional functionality over fixed function hardware.
The alternative to this is Ampere has dedicated decompression hardware that Turing doesn't have, in which case we should expect very different IO performance between these two architectures (first half of my previous post).
Another alternative to this is Turing having secret sauce data decompression hardware hidden from us all this time, which I think it's very unlikely.
This is not related to you, but I'm not sure why my post made some people so defensive though. I thought it was "common sense" that the PC wouldn't have anything similar to the consoles on IO performance for a long time, short of the new GPUs getting fixed function hardware in the GPU SoC and a M.2 slot in the graphics card.
https://on-demand.gputechconf.com/gtc/2016/posters/GTC_2016_Algorithms_AL_11_P6128_WEB.pdf
GPU are good and better than CPU for decompression but the cost is not negligible.
D
Deleted member 13524
Guest
That article mentions LZW only.https://on-demand.gputechconf.com/gtc/2016/posters/GTC_2016_Algorithms_AL_11_P6128_WEB.pdf
GPU are good and better than CPU for decompression but the cost is not negligible.
Is LZW commonly used in PC games?
If it's anything similar to LZMA, then its performance is always pretty bad when compared to zlib.
http://www.radgametools.com/oodlekraken.htm
Nvidia's RTX IO has integration with Microsoft DirectStorage to accelerate loading into the GPU.
Here's the Nvidia RTX IO slide:
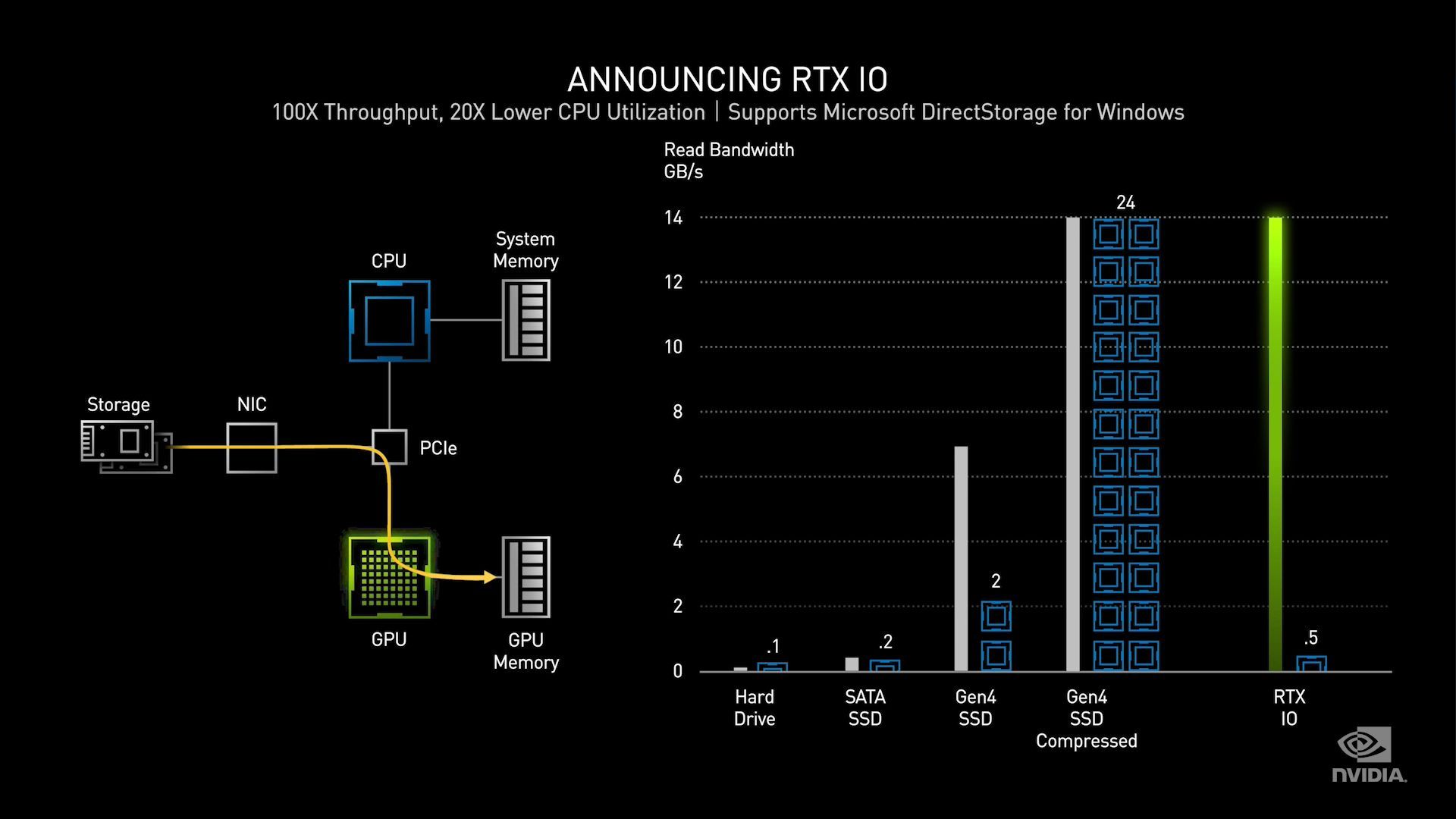
For PS5 it was said their decompression requires 9 of the PS5 Zen 2 cores: 5 GB/S
Xbox Series X said it was 5: 2.4 GB/S
What kind of beefy CPUs are in that chart where it only needs 2 cores to handle 7 GB/S?
For PS5 it was said their decompression requires 9 of the PS5 Zen 2 cores: 5 GB/S
Xbox Series X said it was 5: 2.4 GB/S
What kind of beefy CPUs are in that chart where it only needs 2 cores to handle 7 GB/S?
It is not compressed data. It is raw data.
I do not understand why you write that it not being dedicated hardware somehow makes it "worse". A different Design achieving the same goal of acceleration decompression is not inherenrly worse due to its differentness. If I were to take a guess MS and Sony went the Route of hardware decompression blocks for the conglomerative cost (thermal, monetary, yield, etc.) of utilising more generalised Transistors on the GPU for the same purpose. If MS or Sony did it on the GPU like NV, it would mean less resources for graphics or conversely more die space or more heat and powe usage directly on the SoC. Using a dedicated GPU with in a System with swappable parts for such a purpose does not seem inferior, just a smart way to enforce a standard via a swappable Part. Basically, it makes a lot of sense on the PC to do it differently and not with a hw Block on a motherboard. Think of the difference of using an ASIC, an FPGA or a generalised CPU for the same task - one may make a lot more sense under a certain Budget, manufakturing limitation, or based upon the actual computation necessary and the overhead.I think you only focused on the second part of my post.
If the Turing support for RTX IO is the same as Ampere's, then there's no dedicated hardware for data decompression on Ampere and both architectures are using just the shader ALUs.
If there is no dedicated hardware for data decompression then we shouldn't expect performance similar to the new consoles. If GPU compute shaders were great for data decompression then microsoft or sony wouldn't bother themselves with dedicated units, as compute shaders serve additional functionality over fixed function hardware.
The alternative to this is Ampere has dedicated decompression hardware that Turing doesn't have, in which case we should expect very different IO performance between these two architectures (first half of my previous post).
Another alternative to this is Turing having secret sauce data decompression hardware hidden from us all this time, which I think it's very unlikely.
This is not related to you, but I'm not sure why my post made some people so defensive though. I thought it was "common sense" that the PC wouldn't have anything similar to the consoles on IO performance for a long time, short of the new GPUs getting fixed function hardware in the GPU SoC and a M.2 slot in the graphics card.
I see no reason why it needs to be deemed inferior for achieving the same goal in a different manner.
So it looks like they've brought GPUDirect Storage to the desktop. Awesome.
I found this quote particularly interesting from Microsoft on Nvidia's web page:
The emphasis is mine and it implies that it'll be a standard feature of Direct Storage games to use advanced compression. It would make sense if that compression scheme were the same as used in the XSX, i.e. BC-PACK. A possible further hint towards that is the compression ratio advertised for the XSX and that used by Nvidia in their slide are the same at 2:1.
I'm not sure why. 22GB/s is the theoretical limit of the PS5 decompressor, not what you're going to achieve with normal game code and Kraken. Sony advertised 8-9GB/s from a 5.5GB/s raw throughput for a reason - because it's in line with typical Kraken compression ratio's.
Microsoft are advertising more than that for BC-Pack at 2:1 and that's the same compression ratio used by Nvidia in their example too. So starting with a higher raw throughput (7GB/s vs 5.5GB/s) and adding a higher compression ratio results in the 14GB/s being advertised by Nvidia being reasonably comparable to the 8-9GB/s advertised by Sony. Note in their presentation Nvidia also mentioned the GPU decompression could run faster than the limits of a 7GB/s SSD. That's analogous to Sony's mention of the hardware decompression block being capable of 22GB/s peak.
Nvidia clearly showed in their slide a 14GB/s decompression rate (2:1 compression ratio on the fastest PCIe 4.0 NVMe drives), and they go on to state that the GPU's are capable of more. It seems pretty open and shut to me and I'm not seeing the basis for assuming a hardware decompression block is going to be more performant than a GPU packing tens of TFLOPs. The console manufacturers could easily have included them simply because they were relatively cheap compared to including a slightly bigger more powerful GPU capable of doing the same job in shaders.
EDIT: damn... @Dictator beat me by 60 seconds and said it better too.
I found this quote particularly interesting from Microsoft on Nvidia's web page:
Microsoft said:“Microsoft is delighted to partner with NVIDIA to bring the benefits of next generation I/O to Windows gamers. DirectStorage for Windows will let games leverage NVIDIA’s cutting-edge RTX IO and provide game developers with a highly efficient and standard way to get the best possible performance from the GPU and I/O system. With DirectStorage, game sizes are minimized, load times reduced, and virtual worlds are free to become more expansive and detailed, with smooth & seamless streaming.” - Bryan Langley - Group Program Manager for Windows Graphics and Gaming
The emphasis is mine and it implies that it'll be a standard feature of Direct Storage games to use advanced compression. It would make sense if that compression scheme were the same as used in the XSX, i.e. BC-PACK. A possible further hint towards that is the compression ratio advertised for the XSX and that used by Nvidia in their slide are the same at 2:1.
It might still be below PS5, given its 22GB/s best case scenario.
I'm not sure why. 22GB/s is the theoretical limit of the PS5 decompressor, not what you're going to achieve with normal game code and Kraken. Sony advertised 8-9GB/s from a 5.5GB/s raw throughput for a reason - because it's in line with typical Kraken compression ratio's.
Microsoft are advertising more than that for BC-Pack at 2:1 and that's the same compression ratio used by Nvidia in their example too. So starting with a higher raw throughput (7GB/s vs 5.5GB/s) and adding a higher compression ratio results in the 14GB/s being advertised by Nvidia being reasonably comparable to the 8-9GB/s advertised by Sony. Note in their presentation Nvidia also mentioned the GPU decompression could run faster than the limits of a 7GB/s SSD. That's analogous to Sony's mention of the hardware decompression block being capable of 22GB/s peak.
If the Turing support for RTX IO is the same as Ampere's, then there's no dedicated hardware for data decompression on Ampere and both architectures are using just the shader ALUs.
If there is no dedicated hardware for data decompression then we shouldn't expect performance similar to the new consoles. If GPU compute shaders were great for data decompression then microsoft or sony wouldn't bother themselves with dedicated units, as compute shaders serve additional functionality over fixed function hardware.
Nvidia clearly showed in their slide a 14GB/s decompression rate (2:1 compression ratio on the fastest PCIe 4.0 NVMe drives), and they go on to state that the GPU's are capable of more. It seems pretty open and shut to me and I'm not seeing the basis for assuming a hardware decompression block is going to be more performant than a GPU packing tens of TFLOPs. The console manufacturers could easily have included them simply because they were relatively cheap compared to including a slightly bigger more powerful GPU capable of doing the same job in shaders.
EDIT: damn... @Dictator beat me by 60 seconds and said it better too.
I do not understand why you write that it not being dedicated hardware somehow makes it "worse". A different Design achieving the same goal of acceleration decompression is not inhwrwntly worse due to its differentness. If I were to take a guess MS and Sony went the Route of hardware decompression blocks for the conglomerative cost (thermal, monetary, yield, etc.) of utilising more generalised Transistors on the GPU for the same purpose. If MS or Sony did it on the GPU like NV, it would mean less respuecws for graphics or conversely more die space or more heat and powe usage directly on the SoC. Using a dedicated GPU with in a System with swappable parts for such a purpose does not seem inferior, just a smart way to enforce a standard via a swappable Part. Basically, it makes a lot of sense on the PC to do it differently and not with a hw Block on a motherboard.
I see no reason why it needs to be seemed inferior for achieving the same goal in a different manner.
Thanks Alex, also covers the XSX in some ways.
It is not compressed data. It is raw data.
Any ideas what those cores are in the nvidia slide?
2 cores handling 7 GB raw
PS5 9 of its Zen 2 cores for 5.5 GB raw
XSX 5 of its Zen 2 cores for 2.4 GB raw.
To follow up on this; GPUs are very good at decompression. Many opt to do this on the GPU for data science. The streaming data in was probably the part that needed to be addressed.https://on-demand.gputechconf.com/gtc/2016/posters/GTC_2016_Algorithms_AL_11_P6128_WEB.pdf
GPU are good and better than CPU for decompression but the cost is not negligible.
The console manufacturers could easily have included them simply because they were relatively cheap compared to including a slightly bigger more powerful GPU capable of doing the same job in shaders.
EDIT: damn... @Dictator beat me by 60 seconds and said it better too.
It's probably the more flexible and efficient path too. Edit: with that i mean the NV/GPU solution, ofcourse.
Last edited:
Any ideas what those cores are in the nvidia slide?
2 cores handling 7 GB raw
PS5 9 of its Zen 2 cores for 5.5 GB raw
XSX 5 of its Zen 2 cores for 2.4 GB raw.
@chris1515 already answered that above. They're talking about different workloads. The 2 cores requirement in NV's slide is purely to handle the IO, no decompression involved. The PS5/XSX numbers include decompression. For comparable numbers look to the 14 cores NV mentioned being required to handle both the IO and decompression at 7GB/s
@chris1515 already answered that above. They're talking about different workloads. The 2 cores requirement in NV's slide is purely to handle the IO, no decompression involved. The PS5/XSX numbers include decompression. For comparable numbers look to the 14 cores NV mentioned being required to handle both the IO and decompression at 7GB/s
Then also, what kind of CPU cores? Zen2, zen3, jaguar, Intel i9?
D
Deleted member 13524
Guest
I do not understand why you write that it not being dedicated hardware somehow makes it "worse". A different Design achieving the same goal of acceleration decompression is not inhwrwntly worse due to its differentness. If I were to take a guess MS and Sony went the Route of hardware decompression blocks for the conglomerative cost (thermal, monetary, yield, etc.) of utilising more generalised Transistors on the GPU for the same purpose. If MS or Sony did it on the GPU like NV, it would mean less respuecws for graphics or conversely more die space or more heat and powe usage directly on the SoC. Using a dedicated GPU with in a System with swappable parts for such a purpose does not seem inferior, just a smart way to enforce a standard via a swappable Part. Basically, it makes a lot of sense on the PC to do it differently and not with a hw Block on a motherboard.
I see no reason why it needs to be seemed inferior for achieving the same goal in a different manner.
GPUs excel at highly parallel tasks (many parallel ALUs with generally lower clock and lower IPC than CPUs).
From what we saw with the new consoles, data decompression can't very parallel. Zlib is apparently single threaded, and Kraken is 2 threads max.
You could think that simply splitting data in chunks could work, though if you look at how compression algorithms work then the more you split the lower the compression rate will be, which in the end hurts the effective IO thoughput.
In my opinion, in general I'd say any method that uses general purpose hardware instead of fixed function is the superior one, as general purpose can be used for other tasks.
I just don't see how data decompression can use highly parallel general purpose hardware. Not with the most commonly used compression algorithms, at least.