In this case, you could also do HSR in the binning step, only emitting those triangles that cover pixels. This would allow you to run full vertex shader only for those triangles that have at least one visible pixel. It would also have similar effect as "z-prepass" for pixel shader culling (as the binning step would generate the partial depth buffer for the tile). I did some experiments with a compute shader based pipeline like this. Could be really efficient if done at hardware level.
The most recent description from some of AMD's patents has screen space subdivided into some number of rectangles.
When the rasterizer is deferring shading, a triangle's initial bin is determined and it then enters that bin's list of primitives. This then begins by querying how many tiles it intercepts along one axis. The max and min intercepts are recorded, and the bin will accumulate primitives until full or some other condition is hit.
Then, the list of additional intercepts is passed onto another query step that gets the max and min of bin IDs along the other axis in screen space.
After that reaches some closure condition, the hardware concludes its intercept determination and starts to evaluate coverage.
Within a bin, pixel coverage is determined and what primitives belong to each pixel in a tile are recorded with potentially some number of multiple IDs per pixel allowed in the presence of transparency. There's mention of a possible way of continuously updating a batch so that it can dynamically remove primitives while accumulating more, which may allow more coalescing by preventing culled IDs from hitting the maximum bin size, although it's unclear if that is implemented (would require some kind of indirection to the indices, perhaps?).
The context associated with interpolation and resources associated with export buffers and pixel data may count towards batch closure conditions.
Then there is the number of primitives per batch, which yields a size of the primitive ID for the buffer--needed for coverage and the order of shading.
Then, there's some additional context like whether a primitive is opaque, some flags for the stage of processing a batch/bin is in, some form of depth information per pixel, and an output of coverage either by the scan converter or at that level of precision.
AMD posits for the purpose of utilization at least double-buffering all of this, so multiples of some of the context are to be expected.
8192 primitives per batch is 13 bits per primitive, the number of rows and columns can attach 4 additional fields as form of pipeline context that would take up storage even if not used in the data passed to pixel shader launch.
The tile size is going to give ID bits, transparency, depth of the closest occluder, and some number of IDs per pixel.
There's in effect, an ID buffer of 128x128 pixels with at least 13 bits per pixel without transparency.
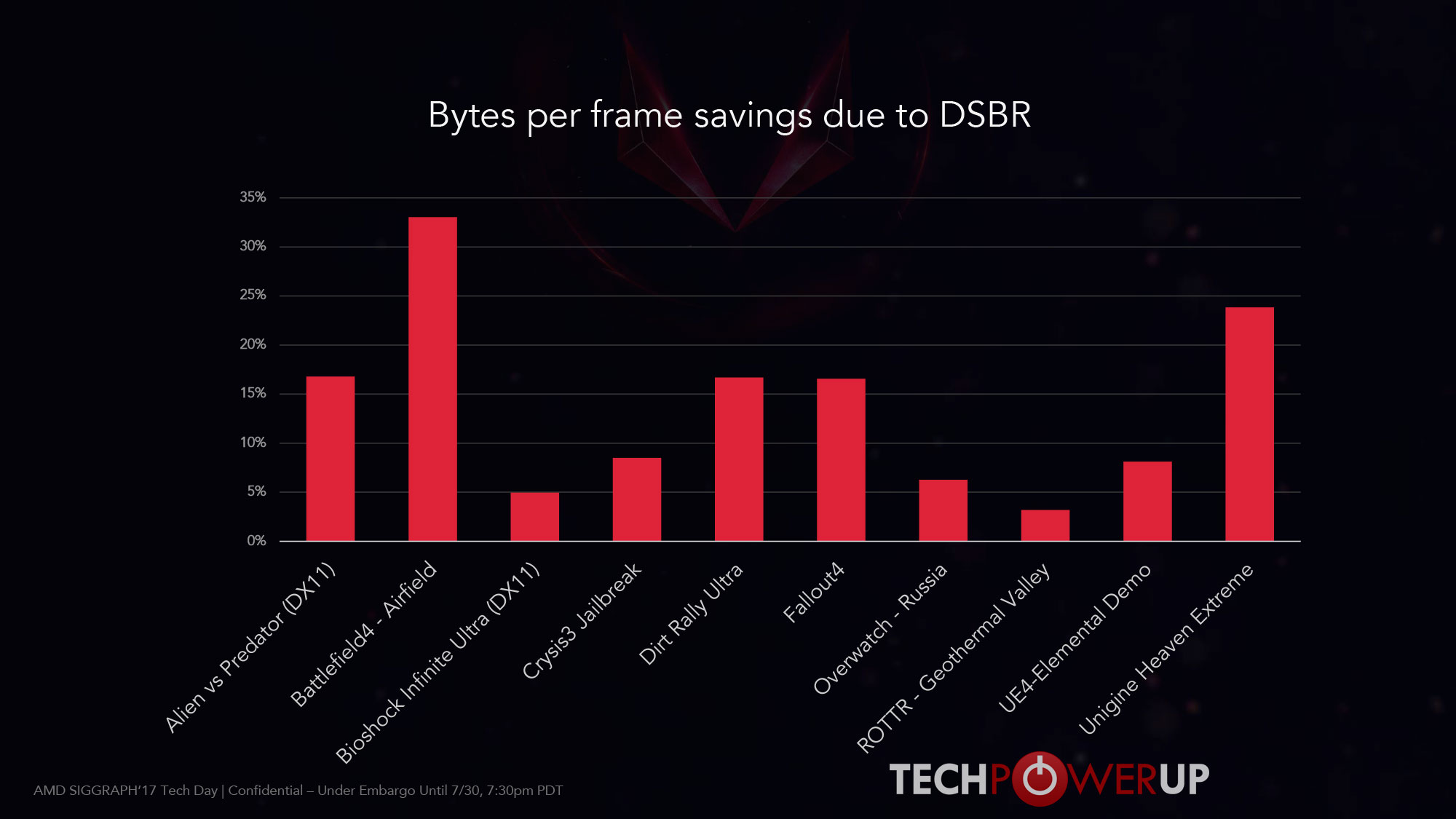
With the ID alone, it's 26KB to just express for one tile what primitive goes to a pixel without double-buffering, transparency, or higher sampling level. Perhaps the depth for the tile can be shared between batches in a double-buffered setup?
")