
Nebuchadnezzar
Legend
Yea the degradation graph is always in the battery page.

http://www.anandtech.com/show/9146/the-samsung-galaxy-s6-and-s6-edge-review
No real degradation testing though. That's literally the most important benchmark! I don't care about a SoC's burst performance! I want to know what performance I can expect after playing a game for 30+ minutes. WTB: looping off-screen benchmarks...
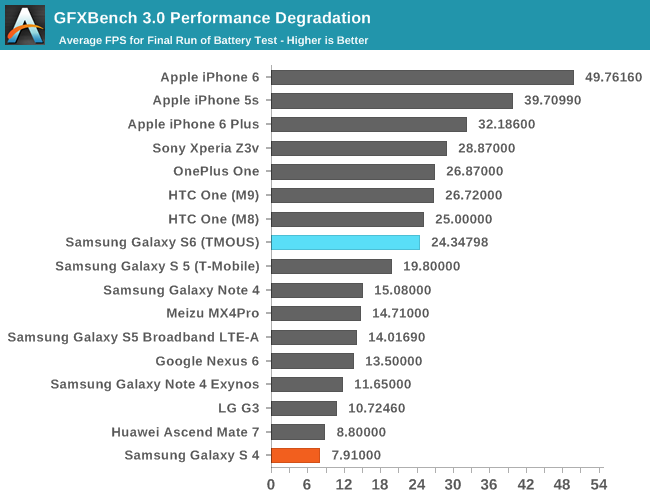

Both aren't quite true, this is onscreen test hence the sustained performance is actually a lot higher (twice as fast or so) than that of the S5 (which also dropped roughly 30% compared to single run).Typical KISS approach: it has under 3D a higher sustained 3D performance of just 20% compared to the Galaxy S5. The 6 Plus is still faster in that regard despite being one generation behind; one step forward and two steps back
Both aren't quite true, this is onscreen test hence the sustained performance is actually a lot higher (twice as fast or so) than that of the S5 (which also dropped roughly 30% compared to single run).
Likewise performance is actually quite a bit higher than that of the IP6+ for the same reason (the IP6+ dropped 25% compared to single run), though given the generation advantage this is indeed not all that amazing but still I wouldn't call that bad.
To expand on mczak's point with a few numbers:
Granted, comparing performance numbers across resolutions like this isn't going to be terribly accurate (doubling the number of pixels doesn't double the geometry etc), but I don't see much of a valid basis for calling this "one step forward and two steps back".
- The Galaxy S6 has a screen resolution of 2560x1440 (~3.7 million pixels), so its sustained performance on that T-rex test (which, as the anandtech article pointed out just below that graph, is an on-screen test), measured in pixels per second, is about 2560*1440*24.34 = 89.7 MPix/s.
- The Galaxy S5, HTC One M9 and IPhone 6 Plus all have a screen resolution of 1920x1080 (~2 million pixels), so their sustained performance are 41.0 MPix/s, 55.4 MPis/x and 66.7 MPix/s respectively.
- The IPhone 6 has a screen resolution of 1334x750 (1 million pixels), giving a sustained performance of 49.8 MPix/s.
Yes, apple is less aggressive in pushing higher gpu clocks mostly just for benchmarks, no doubts about that. Still, the point was that the Galaxy S6 was still quite a bit faster in sustained performance.Either way the throttling in one case is at >38% for one side and <22% in the other and if it's about a neck to neck quick cold synthetic comparison the difference is at 31% at 1080p TRex. Alas if the difference from 20SOC TSMC would be smaller than the latter compared to 14 FinFET Samsung.
It could very well be that while asking for a comparison the Kishonti system cuts an average of all results for a certain device, which can be misleading to the observer in some cases.Yes, apple is less aggressive in pushing higher gpu clocks mostly just for benchmarks, no doubts about that. Still, the point was that the Galaxy S6 was still quite a bit faster in sustained performance.
I don't know though why the kishonti database results differ so much (for the S6), I guess SoC quality could influence this but probably they were using pre-release drivers (the results are pretty incomplete there).
Frequency is pretty irrelevant alone as you should know,...
I'd be however interested in knowing how the respective gpus differ in terms of complexity (transistor count). Some more benchmarks would also be nice (I'd not be surprised if generally Mali would do somewhat worse in lesser known apps since the shader compiler probably has a really difficult time to spit out well optimized code).
GFXBench long term perf uses average over the whole battery run, our degradation metric is the last run fps.
Because we don't really know how the frequency/voltage (or power) graph looks like for these different architectures. Plus in the sustained run the clock of the mali might not have been really higher anyway.Why is it irrelevant? The A8X GPU should clock below 500MHz, while the Tegra X1 GPU at 1GHz. Is is still irrelevant in that case?
Yes I guess that should be possible though I don't know if that would be efficient - see above. Might be more efficient to use more clusters instead.To avoid mistunderstandings: if Apple can clock N SoC block at 533MHz under 20nm, why shouldn't it be able to clock the very same block at the same frequency as in the 7420 under 14 FinFET without negatively influencing power consumption?
Ok I guess series 6gx still has some advantage in terms of perf/area there then.You can guess the rough transistor count of the GX6450 in A8 (~2b transistors for the entire SoC, ~19 out of 89mm2 are for the GPU), yet not for the 7420 GPU unless we get more details. Under 20nm Samsung however if memory serves well the MaliT760MP6 was over 30mm2; now you have 14FF but 2 clusters more in the 7420.
It's true that we don't know the how the frequency/voltage graph looks. But I think it's a safe to assume that we have left the area where we can increase frequencies without increasing voltage at all, i.e. the frequency/power graph will increase faster than linearly, which brings us to...Because we don't really know how the frequency/voltage (or power) graph looks like for these different architectures. Plus in the sustained run the clock of the mali might not have been really higher anyway.
For graphics, it would seem that the larger gain would be had by increasing width, rather than frequency for a given power draw. As far as I can understand, this is mostly a question of cost - increasing width increases die area, which increases cost per chip. Increasing frequencies is essentially "free". For the CPUs the issue is not so clear cut - increasing width may not pay off very well as typical code is not perfectly load balanced over many cores, and bottlenecks and contention in other parts of the system limits scaling in those cases when the code should theoretically scale reasonably well with more cores. I suspect that once you have a couple of cores, increasing frequencies generally pays off better overall than adding more cores for typical software.Yes I guess that should be possible though I don't know if that would be efficient - see above. Might be more efficient to use more clusters instead.
I don't think it's all that clear cut - I suspect mobile gpus (at least those from the performance segment) are operating quite near their optimal (in terms of efficiency) point wrt frequency nowadays (at least for the sustained loads, the peaks might be above that). Though switching the process probably changes the equation. (Switching the process probably also might allow you to switch to an architecture which does better in terms of efficiency but might have been considered too expensive in terms of die area before.)For graphics, it would seem that the larger gain would be had by increasing width, rather than frequency for a given power draw.
Because we don't really know how the frequency/voltage (or power) graph looks like for these different architectures. Plus in the sustained run the clock of the mali might not have been really higher anyway.
Yes I guess that should be possible though I don't know if that would be efficient - see above. Might be more efficient to use more clusters instead.
Ok I guess series 6gx still has some advantage in terms of perf/area there then.
The A8X GPU is over 38mm2 at 20SoC and is now at almost 38fps in Manhattan offscreen.I don't think it's all that clear cut - I suspect mobile gpus (at least those from the performance segment) are operating quite near their optimal (in terms of efficiency) point wrt frequency nowadays (at least for the sustained loads, the peaks might be above that). Though switching the process probably changes the equation. (Switching the process probably also might allow you to switch to an architecture which does better in terms of efficiency but might have been considered too expensive in terms of die area before.)
If you look for instance at Broadwell (ok different power envelope but should follow similar logic), at 15W intel of course doesn't even try GT3. At 28W GT3 is generally a win but still not by all that much - for twice the number of units that's quite an investment for little gain (http://www.anandtech.com/show/9166/intel-nuc5i7ryh-broadwellu-iris-nuc-review/4).
I think Broadwell would scale as well, but due the power limitation it effectively means you get either 24 EUs at clock X or 48 EUs at little more than (clock X /2). I just see no reason why it would be different for these SoCs. IIRC for the few instances where someone did some clock/voltage measurements it really doesn't go down all that much below some point.It's far more than "just" a different power envelope. You cannot under any circumstance compare those with any smartphone SoC. GPU IP like Mali & Rogue scale as expected according to the increase in GPU clusters.