You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia GT300 core: Speculation
- Thread starter Shtal
- Start date
- Status
- Not open for further replies.
Jawed
Legend
GT200 has 16KB shared but 64KB of register file per multiprocessor. GT300 needs 32KB shared for D3D11-CS.Well LRB is gonna have 32KB L1 and 256KB L2 right? GT200 has 16KB. It's really unlikely that GT300 is gonna expand on that in a big way if it sticks to the current CUDA model.
Jawed
IMHLO, AMD is going to have a tough time competing with nv's hardware even if they have gpu's which are twice as fast as their competition. I am speaking for the case when somebody writes some opencl code and runs it on three different chips, AMD's, nv's and lrb.
The last two cases get a free pass because of their naturally scalar nature and let's face it. Reasoning about scalar code is simpler and helps with data layout. AMD's matrix multiplication codes leave me convinced that while the hardware can do a lot, but it will be a nightmare keeping the simpler to write/maintain/debug scalar version of the codes for nv and lrb and special float4 version of the code for AMD.
Float4 is nice for graphics, but even then it struggles to saturate full 5 way madd units. The utilization is mostly 3.5 or thereabouts.
The forward as my limited foresight lets me see is that either ATI too goes scalar or does some compiler level shenanigans to pack 5 scalar threads into one vector thread. Else, despite the very attractive hardware capabilities, it is going to remain a step or two behind.
The last two cases get a free pass because of their naturally scalar nature and let's face it. Reasoning about scalar code is simpler and helps with data layout. AMD's matrix multiplication codes leave me convinced that while the hardware can do a lot, but it will be a nightmare keeping the simpler to write/maintain/debug scalar version of the codes for nv and lrb and special float4 version of the code for AMD.
Float4 is nice for graphics, but even then it struggles to saturate full 5 way madd units. The utilization is mostly 3.5 or thereabouts.
The forward as my limited foresight lets me see is that either ATI too goes scalar or does some compiler level shenanigans to pack 5 scalar threads into one vector thread. Else, despite the very attractive hardware capabilities, it is going to remain a step or two behind.
Why would ATI switch to pure SIMD?
There is nothing inherently stopping an array of VLIW cores running scalar SIMD code ... a VLIW instruction can encode multiple non communicating scalar instructions (calling this shenanigans is tendentious, it's trivial) or it can encode a 4+1 program. There are some decisions you have to make if you want to be efficient at the former, mostly reducing the number of VLIW cores per array to get decent granularity.
Intuitively given the high density of their architecture I think they have some room to drop down the number of VLIW cores per array if they wanted to.
There is nothing inherently stopping an array of VLIW cores running scalar SIMD code ... a VLIW instruction can encode multiple non communicating scalar instructions (calling this shenanigans is tendentious, it's trivial) or it can encode a 4+1 program. There are some decisions you have to make if you want to be efficient at the former, mostly reducing the number of VLIW cores per array to get decent granularity.
Intuitively given the high density of their architecture I think they have some room to drop down the number of VLIW cores per array if they wanted to.
There is nothing inherently stopping an array of VLIW cores running scalar SIMD code
Well nothing stops you from doing that.
Why would ATI switch to pure SIMD?
The point is for the _same_ opencl code, you'd likely reach lower fraction of peak perf levels with ati than with nv or lrb as chances are that most opencl code (ie not specifically tuned to any one particular architecture) is going to to be scalar, and not vec5 like, which is what AMD hw likes.
Any body who thinks dp is not needed for GPGPU has obviously never written _any_ scientific codes.
Just my 2c.
Nobody said dp is not needed. Also, are you now trying to claim that GPGPU and scientific processing are equal?
How should I put that?
"Anybody who thinks that all GPGPU code is for scientific computing only has obviously never done anything with GPGPU".
How is that?
Do you count things like Badaboom, PhysX, realtime audio processing and such as scientific? Because those are some of the most popular uses of CUDA currently.
The forward as my limited foresight lets me see is that either ATI too goes scalar or does some compiler level shenanigans to pack 5 scalar threads into one vector thread. Else, despite the very attractive hardware capabilities, it is going to remain a step or two behind.
Or in a twist of irony, ATi has to increase the size of its GPUs to compensate for its inefficiency and remain competitive
")
Nobody said dp is not needed. Also, are you now trying to claim that GPGPU and scientific processing are equal?
How should I put that?
"Anybody who thinks that all GPGPU code is for scientific computing only has obviously never done anything with GPGPU".
How is that?
Do you count things like Badaboom, PhysX, realtime audio processing and such as scientific? Because those are some of the most popular uses of CUDA currently.
Scientific codes are a subset of GPGPU apps. And for them dpfp is a sine qua non.
Non scientific codes (like you mentioned, video transcoding, physics etc. ) can mostly do with spfp. But dp is a must have, even if it is useful for just a subset of gpgpu apps.
So? ATI reaches a higher peak performance per mm2 compared to NVIDIA at the moment and there will always be cases where the 4+1 model is a natural fit. For those times pure scalar implementations are actually inefficient, because they require far more register space.The point is for the _same_ opencl code, you'd likely reach lower fraction of peak perf levels with ati than with nv or lrb as chances are that most opencl code (ie not specifically tuned to any one particular architecture) is going to to be scalar, and not vec5 like, which is what AMD hw likes.
How it all averages out in the end is pure guess work, your likely for relatively performance is my unlikely for absolute performance per mm2 (assuming the relative density advantage stays approximately intact) at least where NVIDIA is concerned ... what Larrabee brings is anyone's guess.
Maybe NVIDIA really will go pure scalar like the rumours say (ie. branch granularity of 1) in which case neither ATI nor Intel will ever get close on highly divergent scalar code
Last edited by a moderator:
Or in a twist of irony, ATi has to increase the size of its GPUs to compensate for its inefficiency and remain competitive
graphics matters more than non graphics apps for now. so that may not happen any time soon.
So? ATI reaches a higher peak performance per mm2 compared to NVIDIA at the moment and there will always be cases where the 4+1 model is a natural fit. For those times pure scalar implementations are actually inefficient, because they require far more register space.
Exactly. Right now, graphics workloads matter more so the 4+1 model isnt such a bad fit. (even though it is leaving 30% perf on the table which won't go waste in nv like implementation)
For general opencl code, I find it difficult to believe that the 64*4 wide compute model will be a reasonable fit for a lot of apps. (64 for threads and 4 for float4) nv's 32*1 seems much better as it is much less wide. the no cost swizzling on the AMD hw should help somewhat, but call me sceptic.
How it all averages out in the end is pure guess work, your likely is my unlikely (assuming the relative density advantage stays approximately intact) at least where NVIDIA is concerned ... what Larrabee brings is anyone's guess.
"density advantage" you are referring to the perf/mm2 density advantage, right?
Maybe NVIDIA really will go pure scalar like the rumours say (ie. branch granularity of 1) in which case neither ATI nor Intel will ever get close on highly divergent scalar code
I don't think that they will go all the way to sisd (which is what a branch granularity of 1 means) That is not perf/mm2 friendly. And for pure gpgpu (ie non graphics) apps, I find present day CUDA to be pretty similiar to lrb from a programmability perspective.
What do you think? Is there a case where LRB scores over cuda in your opinion?
Scientific codes are a subset of GPGPU apps. And for them dpfp is a sine qua non.
Non scientific codes (like you mentioned, video transcoding, physics etc. ) can mostly do with spfp. But dp is a must have, even if it is useful for just a subset of gpgpu apps.
Well, perhaps I'm missing something here... but don't NV, ATi and LRB all support DP?
So the 'must-have' argument doesn't go.
They all have it. The discussion is about performance of the different DP solutions and how this may or may not be relevant. I already gave the arguments for that.
So I think a more relevant question in this discussion might be:
Will GT300 improve DP performance compared to earlier NV chips?
Because if they 'fix' the performance, then we won't have to have the other discussion in the first place.
Jawed
Legend
Yeah, I think the comparison with SPE LS is apt. I have to admit I, naively, side with the view that if you had to choose which processor you wanted to do this style of programming on you'd choose the one with cache, because it'll do other things through cache when you need it, things that are a complete pain in the arse to do with LS. As it happens NVidia still has texturing hardware with its caches for fetching - though I suppose you can argue that Larrabee's TUs have cache that may be useful too. Hard to know...Or reverse this in the context of OpenCL, and label NVidia's shared memory as software managed L1 cache. Both serialize bank conflicts on scatter/gather to this "cache". The difference to me is that LRB has an L2 backing, perhaps less non-cached memory bandwidth (guessing here on that), and less latency hiding, and NV with perhaps more memory bandwidth and better latency hiding and thus better at non-cache bandwidth limited cases (IMO the more important case). This situation is like SPU programming on the PS3. Good SPU (software managed cache) practices map well to non-SPU code (ie processors with a cache). Often writing code as if you had a software managed cache is ideal for a cached CPU (hint why LRB has cache line management).
Why would latency hiding with Larrabee be worse than with NVidia?
Assume a work group of 1024 work-items, I think that's the largest work group in OpenCL.
Assume Larrabee runs at ~same clock as NVidia, somewhere around 1.5GHz, which seems to be a typical worst case fetch latency of ~512 cycles.
NVidia has 1024 / SIMD-width 8 * 4:1 ALU:fetch ratio (that's for scalars, not even vec4s in graphics which would be 16:1) = 512 cycles of ALU to hide this latency.
Using the same ALU:fetch, Larrabee also needs to find 512 cycles of ALU work. / 4:1 ALU:fetch = 128 fibres (i.e. 1 fibre every 4 cycles) / 4 hardware threads = 32 fibres per thread. 32 fibres is 512 strands, so 2 threads are needed to accommodate 1024 work-items. So to run at full latency-hiding each Larrabee core needs to support 2 full work groups, i.e. 2048 strands.
Now how much on-die memory does each strand get?
Let's say GT300 has GT200's register file of 64KB but with 32KB of shared memory: that's 96KB / 1024 work-items that's 96 bytes.
Let's say that Larrabee can only use L2 (256KB) to hold work-item registers + local memory, i.e. treating Larrabee's L1 and registers as scratchpad. 256KB / 2048 work-items = 128 bytes each. Obviously it's impossible to get data in and out of a core without it going through L2, so there'll be less than 128 bytes actually available.
Of course NVidia could put more register file in, e.g. 128KB. It still presents the issue of trying to get 100% utilisation of shared memory with the algorithm, within the bounds of register-allocation/work-group size. Since Larrabee doesn't dedicate any on-die resources to shared memory per se, there's no issue with utilisation.
---
But I do agree there's a strong chance that Intel will choose bandwidth suitable for ~$300 graphics, which could be half of ATI/NVidia bandwidth for the same price.
Jawed
Any body who thinks dp is not needed for GPGPU has obviously never written _any_ scientific codes.
Just my 2c.
I think dp will be done completely different for the GT300 core. The current solution with a singe FP64 ALU that are only used for GPGPU are not good enough for the next generation. Wasted resources and nvidia will not win the dp benchmarks.
I think next generation ALUs will be similar to the existing FP64 in GT200, but they will probably also have a double FP32 mode. This way each SM can be organized as 4*fp64 or 8*fp32.
Proof? Not much. Cuda dokumentation states that next generation HW will have full 32bit integer mul and that this will be used default. (24bit will be slower).
Jawed
Legend
Apart from the technical merit of the malleability of shared memory and investment in toolset (which was pretty ropey at the start), I'd say CUDA's success is 80% marketing. There's a lot of universities with free hardware from NVidia etc. It works for games, why not in GPGPU?Is CUDA's success solely a function of Nvidia's dollar investment and marketing push or is there something to the technology too?
A huge amount of CUDA buzz is centred on the low-hanging fruit - e.g. the N-body problem that we've been discussing, which is embarrassingly parallel. With half or a quarter of the FLOPs NVidia would still have success in these cases.
The configuration of the scheduler and ALUs has squat to do with NVidia's success.
Indeed, it's reasonable to argue that NVidia's absolute performance is irrelevant, just as long as it's more than the fastest quad-core CPU (which isn't difficult when you only count single-precision FLOPs). Sadly there are quite a few "scientists" out there, as well as NVidia staff, who claim speed-ups for CUDA implementations based on entirely un-optimised CPU code (the N-body stuff we've been discussing is a case in point). Some of these people are so corrupt they make their comparison based on a single CPU core.
Still, there are plenty of people getting real speed-ups, things like option pricing, MRI post-processing and seismic computation - the list goes on
Perhaps you'd like to explain how NVidia's style of instruction issue has provided any notable benefit solely in its own right.Based on what metric? As far as GPGPU goes it's been a remarkable success compared to the non-existent competition.
Of course you can argue that the bloated size of GT200 is irrelevant if you sell them at $5000 a go.
You mean how could NVidia have made a smaller chip with the same performance? Well, it's staring you in the face, it's called RV770. Larrabee will, I expect, show an advantage too - and blow ATI and NVidia's doors off when it comes to double-precision.I'm not really sure why you think it's just bloat. What alternative architecture do you propose would have put them in a similar or better position than they are in today?
http://forum.beyond3d.com/showpost.php?p=1220350&postcount=27I'm baffled as to how can you draw these conclusions with nothing to compare against? Where is AMD's scheduler light architecture excelling exactly?
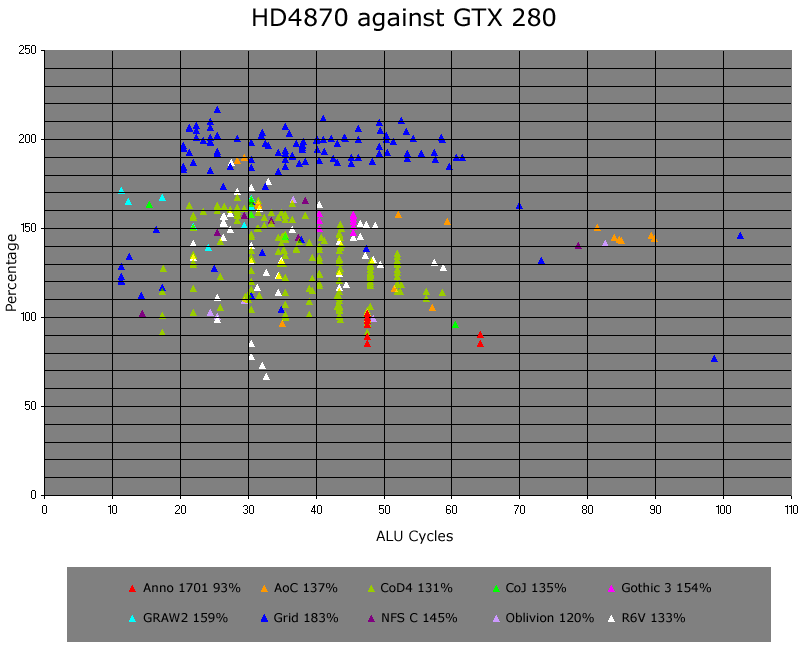
http://forum.beyond3d.com/showthread.php?p=1263635#post1263635 - and the following posts:
http://forum.beyond3d.com/showpost.php?p=1263635&postcount=494So a purely ALU-based comparison of performance per mm2 for HD4870 against GTX280:
Worst case, AMD's ALUs are 76% bigger than NVidia's when running serial scalar code. Most of the time they're effectively 50% of the size in terms of performance per mm2.
- float MAD serial - 57%
- float4 MAD parallel - 273%
- float SQRT serial - 221%
- Float 5-inst. Issue - 239%
- int MAD serial - 137%
- int4 MAD parallel - 279%
Feel free to provide a list of GPGPU applications that are fundamentally scalar with practically zero instruction-level parallelism in the optimum algorithm on NVidia. I'm still looking.
AMD's SGEMM is faster than NVidia's, 300 GFLOPs on HD3870 versus 375 on GTX280.Yeah that's unfortunate because that point renders these discussions moot. The fact that not even AMD has been able to produce something that highlights their architectures strengths is pretty telling to me.
Yes, that's right.I was referring to clause demarcation. That's done at compile time as well no?
NVidia implemented this style of scheduling as part of its non-VLIW approach. The 3 different ALUs in GT200's cores need to be fed - AMD chose VLIW to feed the 5 different ALUs in its cores.Well I didn't mention VLIW. I thought we were talking about scheduling.
A benefit of their configuration is being able to implement a small warp size, 32 - though my theory is that this may really be 64 due to the effect of pairing of warps - I can't find any tests, though I'm wondering now if Volkov's mysterious "minimum of 64" that we were discussing recently is in fact confirmation. I'm strongly convinced ATI has an effective size of 128 because of paired wavefront issue in its ALUs.
Larrabee's an interesting comparison point because it has a scalar pipeline (not sure how many ALUs) + a vector pipeline (VPU, SIMD-16). It's unclear whether it does superscalar issue or VLIW when looking at the scalar+VPU pipes and the flow of instructions. I suspect superscalar.
But within the VPU there appears to be static code scheduling, i.e. there is no dynamic operand scoreboarding. But that's a guess based on code snippets and the conceptualisation of fibres, no more. Obviously there's dynamic fetching of data from cache lines. Register fetches appear to be extremely simple, with 3 operands for one ALU (+ mask as another operand), for a set of 128 registers (4 contexts * 32 registers). It's very cheap, an 8KB register file, compared with 32KB in NVidia.
They're out there too, I've even posted links to them (and scolded some of the crap). Obviously I'm wasting time doing so because apparently people round here believe that AMD has zero GPGPU penetration.And that doesn't answer the question. Where are the apps that prove out the viability of AMD's approach as a general compute solution?
Jawed
what does integer mul have to do with dp alu????
Well, it's not uncommon for an architecture to not actually have separate integer ALUs, and instead use FPU functionality to perform integer operations (eg the original Pentium used the FPU for integer mul, and since R300, fixedpoint shaders are done with FP shader units).
A single-precision FPU would only give you 24 bit integer precision at best. So for 32-bit you'd need an FPU with more than single-precision.
I think that's what ThorHa was referring to.
Jawed
Legend
Eh? They're the same speed. One operand per ALU instruction can come from L1 in Larrabee and shared memory in NVidia. The L1 fetch of a single line of 16 operands is "bank aligned", i.e. full speed.I just don't see how a general cache can easily match the speed of bank aligned shared memory reads.
Jawed
- Status
- Not open for further replies.