itsmydamnation
Veteran
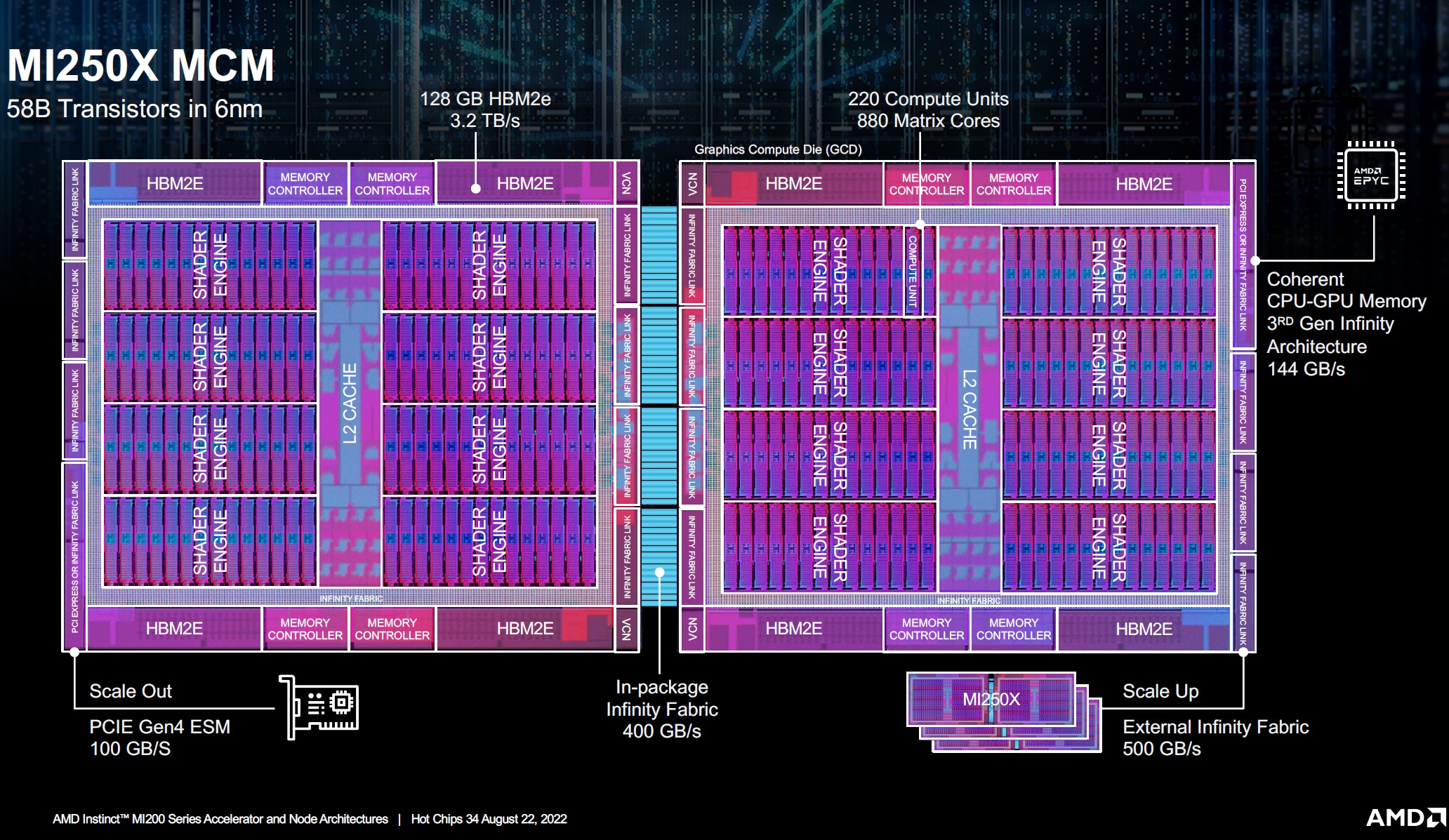
Then why do so many clusters have CPU only nodes?Intel is putting HBM on a CPU, AMD is putting a CPU on HBM. 18 months from now isolated use cases in data centers will be only small part of the business. Accelerators exists because x86 CPUs are not fast enough. Combining a slow x86 CPU with an accelerator is a paradox.
Your view is stupidly simplistic ,
remember executing data is easy moving data is hard. CPU's are orders of magnitude better at moving data that you don't know you need yet or you don't know which data you need (OOE machinery) .
GPU's are orders of magnitude wider then CPU's and have far more concurrency.
CPU's SIMD's are stupidly fast(latency, 4-5 cycle FMA at 2.5-5ghz
HBM limits how large your working set is but has high throughput ( but not really "fast" per say)
DIMM's have low throughput but can have TB of working space
DIMM's can have persistent memory
By putting all these on package , by having coherency end to end , you can:
reduce unnecessary coping of data between "engines" ( remember move hard , execute easy)
remove slow power hungry off package I/O interfaces
increase working set size
accelerate the workload in either direction easier
Team Nv of this forums beloved matrix engines are nothing more then exactly above at play but for a very specific workload , very large number of reads to very low number of writes.

") :
: