
Normally I avoid posting any of my own articles here, but in this case I don't think anyone else got briefed in advance about this (since the embargo came and went), and this is very interesting news.
http://www.anandtech.com/show/9792/...e-announced-c-and-cuda-compilers-for-amd-gpus

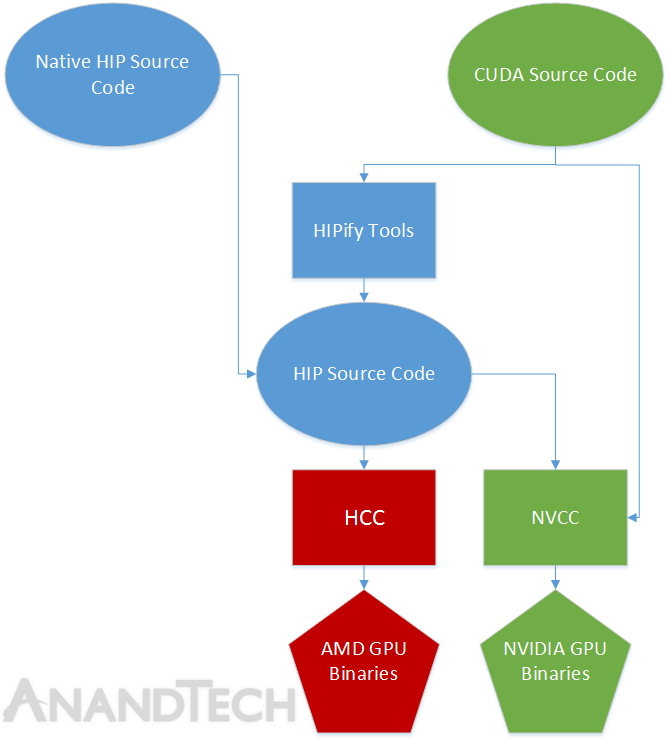
Boltzmann is a new Linux 64-bit driver with HSA+ compatibility, with a C++ compiler built on top of that (including single source programming for GPU kernels), and then a CUDA source-to-source translation layer built on top of that. Mark Papermaster says that they can automatically convert 90% of CUDA code right now.
http://www.anandtech.com/show/9792/...e-announced-c-and-cuda-compilers-for-amd-gpus
Boltzmann is a new Linux 64-bit driver with HSA+ compatibility, with a C++ compiler built on top of that (including single source programming for GPU kernels), and then a CUDA source-to-source translation layer built on top of that. Mark Papermaster says that they can automatically convert 90% of CUDA code right now.

