You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Will GPUs with 4GB VRAM age poorly?
- Thread starter DavidGraham
- Start date
gamervivek
Regular
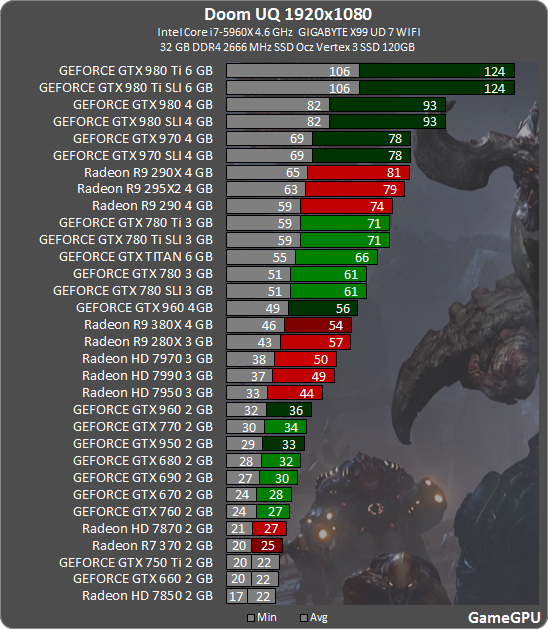
3GB cards are aging poorly, not all of them though.

DavidGraham
Veteran
Strangely, with OpenGL, 3GB Kepler cards deliver 70+% more performance, so it's probably the same situation with Mantle, meaning the close to the metal nature of these APIs necitates the use of bigger amounts of VRAM.3GB cards are aging poorly, not all of them though.
However, it seems HD 7000 cards are not affected by this, so the question now becomes, how is it that a low level APIs which is supposed to give more performance and more control over the hardware cause such massive negative scaling, compared to the old automated API?
Last edited:
Or Nvidia has put a lot of effort into optimizing for specific games on their hardware at the driver level.
Devs make choices that has to work on all platforms and some of these choices will be suboptimal for Nvidia hardware, some for AMD and Intel. DX12 doesn't allow the same level of intercepting stuff; Substituting buffer layouts/formats and shader code on the fly.
Drivers have always been Nvidia's strong suit.
Cheers
Devs make choices that has to work on all platforms and some of these choices will be suboptimal for Nvidia hardware, some for AMD and Intel. DX12 doesn't allow the same level of intercepting stuff; Substituting buffer layouts/formats and shader code on the fly.
Drivers have always been Nvidia's strong suit.
Cheers
I like how my 4 years old HD 7970 OC (which is bascially a R9 280X) inches ahead of the much more modern and with 33% more memory equipped R9 380X and is within striking distance to the lesser Hawaii-based models as well as almost reaching the GTX 970. And of course, how my shiny new, 220-EUR-RX480 is faster than a GTX 980. ")
DavidGraham
Veteran
Could be. Or the developer didn't care putting low level optimization for Kepler in DOOM.Maybe NVidia's driver for those old cards isn't working correctly?
Other Vulkan games work just fine on Kepler.
Highly unlikely, they would have to do it for a lot of games and for a lot of architectures.Or Nvidia has put a lot of effort into optimizing for specific games on their hardware at the driver level
Cheers
Anarchist4000
Veteran
If he were doing that he would have linked the computerbase benchmarks with the 4GB fury beating even a 1070 by a fair margin.Dude what're you doing? You're destroying the narrative!
Please stahp!
https://www.computerbase.de/2016-07/doom-vulkan-benchmarks-amd-nvidia/
Regardless the standardized use of ASTC and even procedural texturing will help a lot. NVLink or whatever AMD is using to the CPU/system memory and it's even less of an issue.
DavidGraham
Veteran
FuryX beating a 1070 have nothing to do with memory, and infact according to the charts from gamegpu, it just reached 980Ti levels of performance, even with the help of the massive boost from vulkan. Meaning it had abysmal performance to begin with.
But as was pointed out in the other thread gamegpu used a setting that precludes Async Compute from workingFuryX beating a 1070 have nothing to do with memory, and infact according to the charts from gamegpu, it just reached 980Ti levels of performance, even with the help of the massive boost from vulkan. Meaning it had abysmal performance to begin with.
Alessio1989
Regular
Yes, advanced modern straming techniques help a lot. However, Virtual/Sparse textures or Tiled/Reserved resources (did I miss some extra nomenclature?) are still uncommon in a lot of modern games (we can tanks Terascale and pre-broadwell GPUs for that I guess... plus the lack of DirectX 11.2 support under Windows 7).Of course you could crank up shadow/texture resolution to exceed even 12 GB card limits. But this mostly benefits 1440p and 4K. Gains are minimal at 1080p. Remember that we are talking about 4 GB cards = mainstream (all high end cards nowadays are 8 GB+). Brute force scaling all settings (especially shadow map resolution) to maximum has a huge performance impact (for mainstream cards), but a very small image quality improvement (esp at 1080p).
Modern shadow mapping algorithms don't need limitless memory to look good. Virtual shadow mapping needs only roughly as many shadow map texels as there are pixels in the screen for pixel perfect 1:1 result. Single 4k * 4k shadow tile map is enough for pixel perfect 1080p (= 32 MB). Algorithms using conservative rasterization need even less texel resolution to reach pixel perfect quality (https://developer.nvidia.com/content/hybrid-ray-traced-shadows).
Similarly texture resolution increase doesn't grow GPU memory cost with no limit. Modern texture streaming technologies calculate required pixel density for each object (GPU mipmapping is guaranteed not to touch more detailed data). Only objects very close to the camera will require more memory. Each 2x2 increase in texture resolution halves the distance needed to load the highest mip level. At 1080p a properly working streaming system will not load highest mip textures most of the time (less screen pixels = high mips are needed much less frequently). Of course there's some overhead in larger textures, but it is not directly related to the texture assets data size. There are also systems that incur (practically) zero extra memory cost of added content or added texture resolution. Virtual texturing reaches close to 1:1 memory usage (loaded texels to output screen pixels). You could texture every single object in your game with a 32k * 32k texture, and still run the game on 2 GB graphics card. Loading times would not slow down either. But your game would be several terabytes in size, so it would be pretty hard to distribute it
If we talk about things like VR +MSSAA bandwidth waste due texture streaming could become a serious issue under multi-GPU.
PS: wasn't 64K the minimum granularity under Windows?
EDIT: there are also game using dynamic details scaling techniques to deal with "small" VRAM pools, like the last couple of Total War (which is the reason I never consider such games as pure benchmark if the related option is enabled).
Last edited:
Jawed
Legend
That's exactly what the Game Ready drivers are. Well, the games part. Architectures seems to be a much muddier facet.Highly unlikely, they would have to do it for a lot of games and for a lot of architectures.
Software indirection (in virtual texturing) is practically free nowadays. Redlynx Trials games and id software games ran already at locked 60 fps on last gen consoles. Software indirection is just a couple extra ALU. And the indirection texture read is super cache optimal (as 128x128 pixels read the same texel). It is close to 100% L1 hit.Yes, advanced modern straming techniques help a lot. However, Virtual/Sparse textures or Tiled/Reserved resources (did I miss some extra nomenclature?) are still uncommon in a lot of modern games (we can tanks Terascale and pre-broadwell GPUs for that I guess... plus the lack of DirectX 11.2 support under Windows 7).
If we talk about things like VR +MSSAA bandwidth waste due texture streaming could become a serious issue under multi-GPU.
PS: wasn't 64K the minimum granularity under Windows?
Software indirection also results in tightly packed "physical address space". This is great if you use deferred texturing and need to store the "physical UV" to your g-buffer.
As you said, hardware PRT has also too big page size. 16 KB would be much better. Software indirection doesn't have this problem.
Also regarding to virtual/sparse shadow mapping. You need to refresh the mapping every frame. GPU goes through the depth buffer and determines shadow map page visibility (and mip). Current APIs dont have UpdateTileMappingsIndirect. You can't change the hardware PRT mappings without a CPU roundtrip, and that would either stall the GPU or add one frame of latency -> shadow glitches. Thus software indirection is currently the only possibility.
Alessio1989
Regular
16K and indirect tile update.
This is a good reuqest for Santa Claus living in Redmond
This is a good reuqest for Santa Claus living in Redmond
I talked with Ola Olsson (his paper: http://www.cse.chalmers.se/~uffe/ClusteredWithShadows.pdf) at Siggraph last year and we discussed about this problem. He was talking about virtual shadow mapping local lights and I had one slide about our sunlight virtual shadow mapping stuff. They use hardware PRT and it stalls everything. Also the page mapping changes are horribly slow on OpenGL. These problems are acceptable for research papers/demos, but you can't afford the stall in real games. Everyone doing research on this topic agrees that indirect page table update is needed. Otherwise hardware PRT loses many use cases.16K and indirect tile update.
This is a good reuqest for Santa Claus living in Redmond
Last edited:
DavidGraham
Veteran
Comparisons before and after Game Ready drivers don't show much of a performance impact in most cases, driver notes don't state as such as well. These drivers are directed towards bug fixing and support of visual features .That's exactly what the Game Ready drivers are. Well, the games part. Architectures seems to be a much muddier facet.
DavidGraham
Veteran
Well, I can confirm Rise of Tomb Raider is extremely sensitive to texture quality settings, just by switching to Very high preset sees my frames cut in half despite not running out of memory, running the game on High texture settings can boost fps from anywhere between 33% to 70%. Normally, in most games, this doesn't happen. As texture settings affect VRAM more than anything, it doesn't interfere with fps unless you run out of VRAM, in which case hitching and stuttering will appear.
Also not every area in the game is taxing on the hardware. Only wide, open areas are (like the Soviet base level or the forest level). Those are the ones affected by the texture settings more. And these are ones that show the widest gap between NV and AMD hardware performance.
Edit: NV recommends the use of a 12GB GPU @Very High, they say VRAM utilization can reach 10GB over prolonged sessions:
http://www.geforce.com/whats-new/guides/rise-of-the-tomb-raider-graphics-and-performance-guide
Also not every area in the game is taxing on the hardware. Only wide, open areas are (like the Soviet base level or the forest level). Those are the ones affected by the texture settings more. And these are ones that show the widest gap between NV and AMD hardware performance.
Edit: NV recommends the use of a 12GB GPU @Very High, they say VRAM utilization can reach 10GB over prolonged sessions:
http://www.geforce.com/whats-new/guides/rise-of-the-tomb-raider-graphics-and-performance-guide
Last edited:
pMax
Regular
Why? A page fault will force you to load from disk anyway, so where's the heck? Do you talk about dGPU systems with some textures held in CPU RAM?As you said, hardware PRT has also too big page size. 16 KB would be much better. Software indirection doesn't have this problem.
I do not see exactly the point with HSA -except, of course, if the HDD doesnt have the 64k read sequentially at hand.
The CPU trap triggered by the GPU is causing so much latency to lose a frame? Again, are you talking about windows or consoles?You can't change the hardware PRT mappings without a CPU roundtrip, and that would either stall the GPU or add one frame of latency
No, I was talking about hardware PRT (tiled resources) API. On PC you don't have any other way to do sparse GPU virtual memory mappings. The page size is 64 KB in PC DirectX. Virtual memory is useful for data streaming, but it is also very useful for sparse resources, such as sparse shadow maps and volumetric data structures (sparse voxels). 64 KB page mapping granularity is too coarse for these purposes.Why? A page fault will force you to load from disk anyway, so where's the heck? Do you talk about dGPU systems with some textures held in CPU RAM?
I do not see exactly the point with HSA -except, of course, if the HDD doesnt have the 64k read sequentially at hand.
HDD sector size has no meaning for virtual texturing. All modern virtual texturing systems compress data separately in a different variable bitrate format for HDD (either lossless LZMA style or lossy wavelet/JPG style). Data is transcoded at page load. HDD data chunks do not have 1:1 mapping to GPU pages. Usually HDD pages are grouped in macro pages to reduce seeking.
There is no CPU trap in PC DirectX API. You need to manually put page misses to an append buffer, readback page miss buffer on CPU (next frame) and call UpdateTileMappings to update virtual memory page table. This is acceptable for texture streaming (virtual texturing), but it not acceptable for dynamic GPU generated data, such as sparse (virtual) shadow maps. We need UpdateTileMappingsIndirect API. GPU writes new tile mappings to a UAV and indirect mapping changes mappings accordingly.The CPU trap triggered by the GPU is causing so much latency to lose a frame? Again, are you talking about windows or consoles?
Last edited:
Similar threads
- Replies
- 10
- Views
- 4K