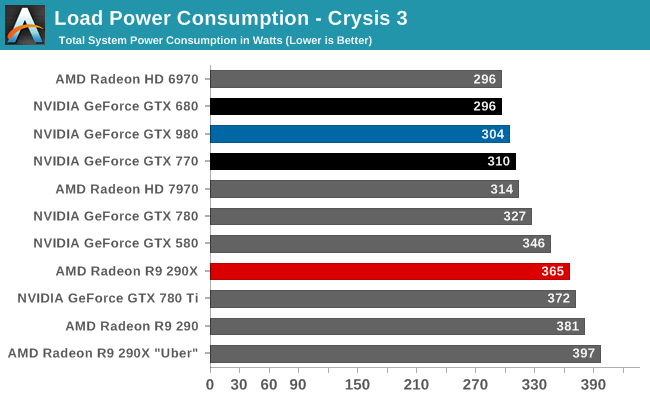
The problem is that the TDP is designed around current gaming load. DX12 should be able to push the GPU much harder, thus I don't think 165W TDP for 980 will be valid in the future unless you want your card to throttle a lot or the cooling is designed for much bigger TDP. The reference card on tomshardware link is keeping the TDP low by throttling.
Intel's DX12 demo showed a small consumption drop at the same performance level. This was a low-power device, but DX12 has features that allow for the GPU to reduce some of the work in its side as well. With more in-depth use of the algorithmic changes it offers, additional redundant work can be removed. If the performance is uncapped, utilization will probably go up since the GPU isn't stalling as much, but if throttling kicks in more often it shouldn't happen outside of periods of higher performance than the card would hit otherwise--barring some kind of weirdness with overly twitchy turbo/throttling thresholds.
As far as TDP becoming invalid, it is a physical design parameter for the cooler. It remains as valid as the day it was set down for a specific product. It serves as a general proxy for some other device parameters when people discuss it, but its real purpose is to specify the behavior of the chip and the necessary behavior of a cooling solution for it.
As far as throttling goes, virtually all these chips are throttling. They all have the ability to ramp higher if they wished, we only call it throttling based on where the baseline is set.
As far as Nvidia goes, it's made some architectural changes that reduce the complexity of the hardware at various stages that can become a critical path, as was noted earlier.
That might inject some fragility and software-level complexity, whereas GCN has purposefully traded some efficiency for greater flexibility and a more simple software model. It seems like it has a broader pick stage, more replicated scheduling hardware, and a cache subsystem that is active more often.
I am also starting to think Nvidia's done more to optimize its hardware. AMD has been touted as being better at this in the past, but it seems like their attention has been split up amongst too many targets to really make that case, because a lot of their products have been taking two revisions to nail down physical characterization and power management.