If you use the MUL for putting values in range before computing special functions, then your MUL hardware is at the wrong end of the pipeline for interpolating attributes (which wants it at the end). You now have a layout nightmare.Uttar said:P.S.: I'm now 99% sure that the MUL is doing Special Function setup (to put the values in range).
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The Official NVIDIA G80 Architecture Thread
- Thread starter Arun
- Start date
Jawed
Legend
I'm familiar with Paper-164...
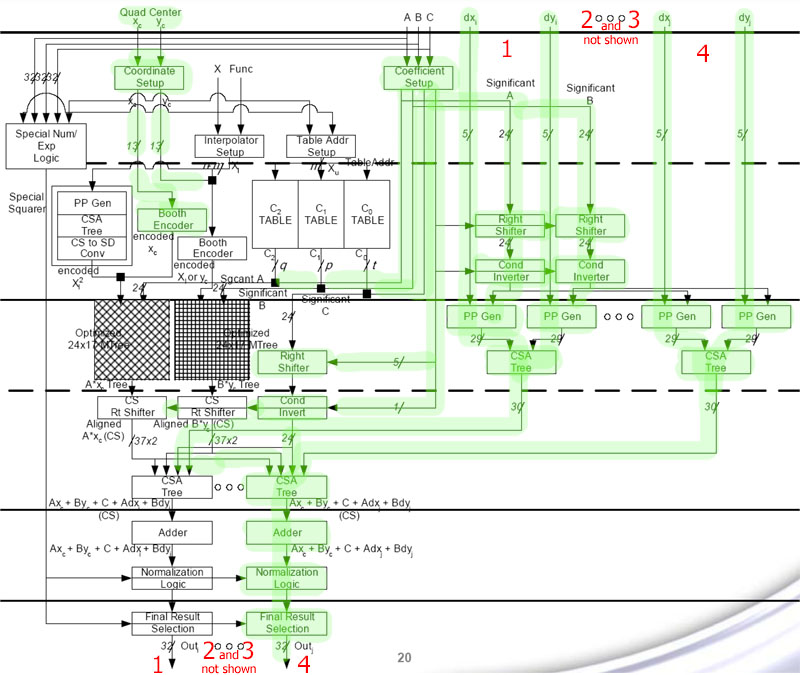
I've marked in green the pipeline stages and data flows that are dedicated to attribute interpolation. Apart from the end of "interpolation pipeline 1" where the shifters, CSA Tree, Adder, Normalization and Result Selection are used by both SF and interpolation. So, 3 interpolation pipelines are "auxilliary", while pipeline 1 is part-used for SF.
Jawed
No, they're not.What you don't seem to be realizing is that what you call the "auxiliary" paths are actually (partially) used for SF.
I've marked in green the pipeline stages and data flows that are dedicated to attribute interpolation. Apart from the end of "interpolation pipeline 1" where the shifters, CSA Tree, Adder, Normalization and Result Selection are used by both SF and interpolation. So, 3 interpolation pipelines are "auxilliary", while pipeline 1 is part-used for SF.
NO! Those equations are calculated using the trees (ROM) and the pipeline stages - non-iteratively. There's no looping here.But SF needs to do 3 iterations (it's not strictly three iterations; the second iteration is very specific, as well as some other things, which is why the paper calls it "three hybrid passes" - the details are available on page 3 of the paper if you feel like wasting some time...)
Jawed
Bob: Very interesting point, I hadn't thought of it that way. I guess I was still partially hoping for it to be a bit more complicated than just serial before or after the interpolator. Initially, I was assuming serial or parallel to the MADD, but clearly that doesn't seem to be the case at this point - ah well.
Jawed: This is quite embarassing, but I just realized I confused part of the process used to create the lookup tables in software with the actual methods used to get the results thanks to these lookup tables in hardware - oops! Not only that, but I managed to think dx+dy there was two auxiliary paths, and not one (see my 3 out of 5 comments in the other post) - I think I was assuming that since it was a quad, they had the same X on 2 pixels and the same Y on 2 others. I can see a couple of reasons why that wouldn't work though, including centroid sampling... And maybe I'm missing other reasons why that optimization couldn't work.
It'd have helped a bit if the arith17 presentation was still available when I decided to finally read these papers fully though, as it was a bit more precise on what's shared and what isn't if I remember correctly. Anyhow, I'm too tired to completely check your proposed sharing of units since it's nearly 3AM here, and I know I'd just accumulate the errors...") It does seem to make sense to me though, so thanks definitely for that correction! You wouldn't have a copy of the slide-based presentation that I can't seem to find a copy of anywhere nowadays, would you, btw?
It does seem to make sense to me though, so thanks definitely for that correction! You wouldn't have a copy of the slide-based presentation that I can't seem to find a copy of anywhere nowadays, would you, btw?
Uttar
Jawed: This is quite embarassing, but I just realized I confused part of the process used to create the lookup tables in software with the actual methods used to get the results thanks to these lookup tables in hardware - oops! Not only that, but I managed to think dx+dy there was two auxiliary paths, and not one (see my 3 out of 5 comments in the other post) - I think I was assuming that since it was a quad, they had the same X on 2 pixels and the same Y on 2 others. I can see a couple of reasons why that wouldn't work though, including centroid sampling... And maybe I'm missing other reasons why that optimization couldn't work.
It'd have helped a bit if the arith17 presentation was still available when I decided to finally read these papers fully though, as it was a bit more precise on what's shared and what isn't if I remember correctly. Anyhow, I'm too tired to completely check your proposed sharing of units since it's nearly 3AM here, and I know I'd just accumulate the errors...
It does seem to make sense to me though, so thanks definitely for that correction! You wouldn't have a copy of the slide-based presentation that I can't seem to find a copy of anywhere nowadays, would you, btw?Uttar
Jawed
Legend
Glad we got that sorted!
Once you've reviewed it, I'm still intrigued by this whole question of the "missing MUL", so I hope that sparks some ideas.
I had thought that the dedicated interpolation pipelines might provide the MUL (since there's 16 of them), but I haven't actually thought that one through.
Jawed
Once you've reviewed it, I'm still intrigued by this whole question of the "missing MUL", so I hope that sparks some ideas.
I had thought that the dedicated interpolation pipelines might provide the MUL (since there's 16 of them), but I haven't actually thought that one through.
Jawed
Jawed
Legend
Mostly stuff like incorrect references to images - just a throwaway comment meant to indicate that we should see more-polished versions eventually - NVidia does re-issue docs...What errors have you spotted?
Jawed
Bob: ... I guess I was still partially hoping for it to be a bit more complicated than just serial before or after the interpolator. Initially, I was assuming serial or parallel to the MADD, but clearly that doesn't seem to be the case at this point - ah well.
It doesn't? How in heaven's name can they claim "dual-issue MADD + MUL" if the MUL is merely a slave to the interpolator? That seems a bit of a stretch to me. Also, if the MUL winds up sitting in the interpolator, how does that affect its use for perspective correction?? Or, more properly, would there be contention between the two? And if that's the hypothesis, surely one could test that.... :nudge:
One of the patents that has been bandied about on these forums is a dual-function math unit that could be used either as a MUL or as an interpolator. I would tend to suspect that either the unit is broken or it's a driver issue. This may or may not be the case, of course, but I think it would be an interesting thing to re-test for the next G8x release, as well as for later driver releases that increase performance.It doesn't? How in heaven's name can they claim "dual-issue MADD + MUL" if the MUL is merely a slave to the interpolator? That seems a bit of a stretch to me. Also, if the MUL winds up sitting in the interpolator, how does that affect its use for perspective correction?? Or, more properly, would there be contention between the two? And if that's the hypothesis, surely one could test that.... :nudge:
I guess I have this simple notion in my head that lerps are more like MADs than MULs (start + stride * unit_delta), I guess I should read more about the interpolators. I admit to a certain degree of eye-glazedness there.
If you can find the patent, I'd appreciate it. I found nAo's list, but, I didn't see it there (and his three links are tiny-url'd, which, for historical purposes, ought to be banned :> ). I remember seeing a number of combinations, but not that particular one.
-Dave
If you can find the patent, I'd appreciate it. I found nAo's list, but, I didn't see it there (and his three links are tiny-url'd, which, for historical purposes, ought to be banned :> ). I remember seeing a number of combinations, but not that particular one.
-Dave
Refering back to a discussion about double precision floating point support in future GPU's, this quote in today's NY Times is interesting:
Andy Keane, GM of Nvidia's professional products division:
Andy Keane, GM of Nvidia's professional products division:
And the next generation of the 8800, scheduled to arrive in about a year, will have “double precision” mathematical capabilities that will make it a more direct competitor to today’s supercomputers for many applications.
Dunno if it was linked before but I saw this Siggraph a few months ago:

Extended-Precision Floating-Point Numbers for GPU Computation (pdf)
Extended-Precision Floating-Point Numbers for GPU Computation (pdf)
Uttar,
In the 'original of all knowledge' diagram of your first post, you mention a yield of 70%. Where does this number come from? I find it hard to believe someone would volunteer this info...
Great article, BTW!
In the 'original of all knowledge' diagram of your first post, you mention a yield of 70%. Where does this number come from? I find it hard to believe someone would volunteer this info...
Great article, BTW!
Eheh, that's what I previously wrote, I hope each 4x4 quad can be filled with 2x2 quads coming from different primitives, not necessarily close onesI don't think 4x4 blocks necessarily means bad performance on small triangles. It depends on how you do things. For example, Xenos allows the pixels in a vector to come from different triangles.
on sale at pc world

apparently these are the new ogl extensions
GL_ES
GL_EXTX_framebuffer_mixed_formats
GL_EXT_Cg_shader
GL_EXT_bindable_uniform
GL_EXT_depth_buffer_float
GL_EXT_draw_buffers2
GL_EXT_draw_instanced
GL_EXT_framebuffer_sRGB
GL_EXT_geometry_shader4
GL_EXT_gpu_program_parameters
GL_EXT_gpu_shader4
GL_EXT_packed_float
GL_EXT_shadow_funcs
GL_EXT_texture_array
GL_EXT_texture_buffer_object
GL_EXT_texture_compression_latc
GL_EXT_texture_compression_s3tc
GL_EXT_texture_integer
GL_EXT_texture_sRGB
GL_EXT_texture_shared_exponent
GL_EXT_transform_feedback
GL_EXT_ycbcr_422
GL_NVX_conditional_render
GL_NV_depth_buffer_float
GL_NV_framebuffer_multisample_ex
GL_NV_geometry_shader4
GL_NV_gpu_program4
GL_NV_gpu_shader4
GL_NV_parameter_buffer_object
GL_NV_texture_compression_latc
GL_NV_texture_compression_vtc
GL_NV_transform_feedback
GL_OES_conditional_query
WGL_EXT_framebuffer_sRGB
WGL_EXT_pixel_format_packed_float
WGL_NV_gpu_affinity
apparently these are the new ogl extensions
GL_ES
GL_EXTX_framebuffer_mixed_formats
GL_EXT_Cg_shader
GL_EXT_bindable_uniform
GL_EXT_depth_buffer_float
GL_EXT_draw_buffers2
GL_EXT_draw_instanced
GL_EXT_framebuffer_sRGB
GL_EXT_geometry_shader4
GL_EXT_gpu_program_parameters
GL_EXT_gpu_shader4
GL_EXT_packed_float
GL_EXT_shadow_funcs
GL_EXT_texture_array
GL_EXT_texture_buffer_object
GL_EXT_texture_compression_latc
GL_EXT_texture_compression_s3tc
GL_EXT_texture_integer
GL_EXT_texture_sRGB
GL_EXT_texture_shared_exponent
GL_EXT_transform_feedback
GL_EXT_ycbcr_422
GL_NVX_conditional_render
GL_NV_depth_buffer_float
GL_NV_framebuffer_multisample_ex
GL_NV_geometry_shader4
GL_NV_gpu_program4
GL_NV_gpu_shader4
GL_NV_parameter_buffer_object
GL_NV_texture_compression_latc
GL_NV_texture_compression_vtc
GL_NV_transform_feedback
GL_OES_conditional_query
WGL_EXT_framebuffer_sRGB
WGL_EXT_pixel_format_packed_float
WGL_NV_gpu_affinity
Last edited by a moderator:
Believe it or not, it comes directly from NVIDIA! They've claimed roughly 80 functional dies on average (GTX and GTS combined) per wafer, and it's easy to realize that the number of chips on a wafer is 118, based on the public wafer shots out there.Uttar,
In the 'original of all knowledge' diagram of your first post, you mention a yield of 70%. Where does this number come from? I find it hard to believe someone would volunteer this info...
Great article, BTW!
Uttar
Sorry for the interruption, but is this following information correct?
http://www.guru3d.com/article/Videocards/391/3/
I thought the data enters into the Vertex stage first everytime, and then gets moved into Triangle setup, Rasterization, then down to Pixel Shader making it's way from ROP to frame buffer.
Please bear with me, I am just an enthusiast.
http://www.guru3d.com/article/Videocards/391/3/
With the introduction of DirectX 8 & 9, in the traditional way when you executed a shader instruction you had to to send it to either the pixel or the vertex processor. And when you think about that it a little more that seems somewhat inefficient, as you could have the pixel shader units 100% utilized while the vertex units were only 60% utilized. And that's a waste of resources, efficiency and power, thus power consumption as you are not using a lot of transistors.
I thought the data enters into the Vertex stage first everytime, and then gets moved into Triangle setup, Rasterization, then down to Pixel Shader making it's way from ROP to frame buffer.
Please bear with me, I am just an enthusiast.
At best it is poorly worded.Sorry for the interruption, but is this following information correct?
Your summary is much better.
So, anyway, what are the chances of the 16 interpolator pipes being able to perform an fp16 MUL? The MAD+MUL co-issue might only be possible if the latter is done with fp16 precision.
I look at the 5-bit path and think "exponent", but I get stuck
Jawed
I got the same results in FP16 and FP32 : can't see the MUL being used.
Dunno if it was linked before but I saw this Siggraph a few months ago:
Extended-Precision Floating-Point Numbers for GPU Computation (pdf)
nAo - yes this is quite an old technique (I am using it with double precision components for some work I'm doing) and it actually generalizes to (almost) arbitrary precision by increasing the number of components in the unevaluated sum. However the technique has some pretty big drawbacks:
- exponent range remains fixed
- basic operations like add and multiply are expensive, multiply especially so without an IEEE compliant 'fmac' instruction.
- without a true 'fmac', the multiply procedure can fail for large inputs even though the result doesn't overflow available precision. If your inputs aren't guaranteed to be in range, you can test for this case and scale with powers of 2 to avoid overflow, making the routine even slower
- IIRC there are issues with denorms
So... the technique is very smart, and one of very few choices if your HW doesn't support higher precision, but IMO it's still a really poor substitute for double precision HW. The Cell SPU approach is far far far preferrable (and almost certainly many times faster too).
Similar threads
- Replies
- 6
- Views
- 508
- Replies
- 0
- Views
- 2K
- Replies
- 3
- Views
- 378
- Replies
- 50
- Views
- 9K