
Megadrive1988
Veteran
http://anandtech.com/video/showdoc.aspx?i=3507
This is DirectX 10.
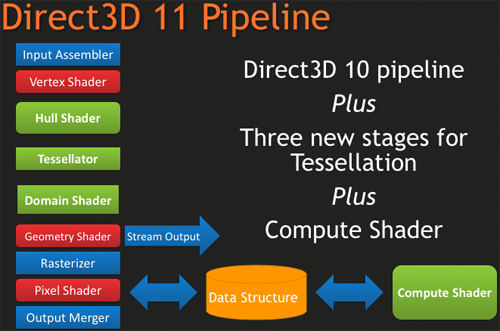
Meet DirectX 11.

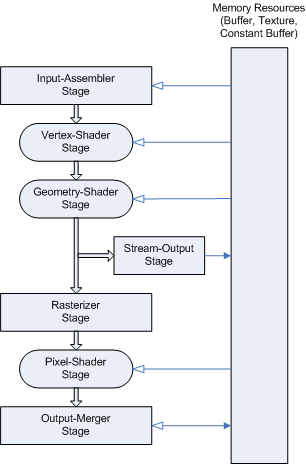
This is DirectX 10.
We all remember him from our G80 launch article back in the day when no one knew how much Vista would really suck. Some of the short falls of DirectX 10 have been in operating system support, driver support, time to market issues, and other unfortunate roadblocks that kept developers from making full use of all the cool new features and tools DirectX 10 brought.
Meet DirectX 11.
She's much cooler than her older brother, and way hotter too. Many under-the-hood enhancements mean higher performance for features available but less used under DX10. The major changes to the pipeline mark revolutionary steps in graphics hardware and software capabilities. Tessellation (made up of the hull shader, tessellator and domain shader) and the Compute Shader are major developments that could go far in assisting developers in closing the gap between reality and unreality. These features have gotten a lot of press already, but we feel the key to DirectX 11 adoption (and thus exploitation) is in some of the more subtle elements. But we'll get in to all that in due time.
Along with the pipeline changes, we see a whole host of new tweaks and adjustments. DirectX 11 is actually a strict superset of DirectX 10.1, meaning that all of those features are completely encapsulated in and unchanged by DirectX 11. This simple fact means that all DX11 hardware will include the changes required to be DX 10.1 compliant (which only AMD can claim at the moment). In addition to these tweaks, we also see these further extensions:
While changes in the pipeline allow developers to write programs to accomplish different types of tasks, these more subtle changes allow those programs to be more complex, higher quality, and/or more performant. Beyond all this, Microsoft has also gone out of its way to help make parallel programming a little bit easier for game developers.
")
