Roy Kim, a senior Nvidia product manager, told us the way forward is a "hybrid" approach, with a less-accurate model on the device so that decisions can be made immediately while a more powerful backend processes the situation and returns a more nuanced decision. State-of-the-art image-recognition systems have more than 150 layers of neurons, said Kim, hence the need for some more oomph on the inference side.
To maximize inference throughput, so your IoT personal-assistant-in-the-cloud doesn't leave you hanging for too long when you ask it a question, Nvidia has added two instructions to its Pascal architecture: IDP2A and IDP4A. These perform two and four-element 8-bit vector dot product calculations with a 32-bit accumulation.
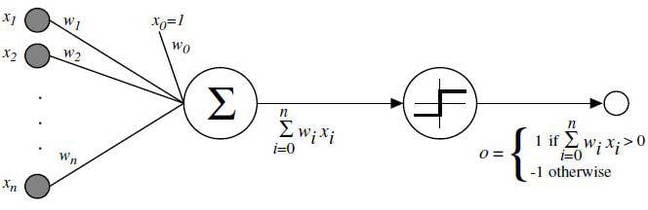
The diagram of a single neuron below looks horrific but it's not as scary as you think. You've got values
x1 to
xn coming in on the left along
n paths. Each
xi input value is multiplied by its path's weight
wi, and then the results of these multiplications are all added up. That's the dot product part.
Then that sum is fed into a threshold or activation function, and that output is fed into the next perceptron in the network.
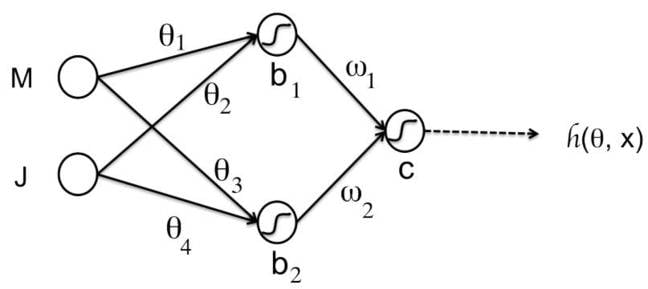
When you link these together you get something looking like this basic network, which has two inputs, three neurons, and an output.
So, ignoring the activation function, that top neuron's dot-product output is: (
M x
θ1) + (
J x
θ2). Now imagine those variables are each 8-bit integers ranging from -127 to 127, or 0 to 255. Now imagine doing up to 47 trillion of those dot-product operations a second, all combining inputs to feed into the next stages of a network. That's what Nvidia's P40 is claiming to do. That's what Nv means by accelerated 8-bit dot product calculations.
Nvidia also claims its P4 can do, at its very best, 21.8 trillion operations a second using 8-bit integers, and that the P4 is "40 times more efficient" than an Intel Xeon E5 CPU in terms of the number of images classified per second per watt using an AlexaNet-trained model.
The P4 and P40 will go on sale in October and November, we're told. If you really want to get your hands on similar kit now, Nv's Pascal-based
Titan X graphics card, which emerged in July, can also do 44 TOPS of 8-bit integer operations. The P40 is basically a slightly beefier Titan X.
Meanwhile, Nvidia has released
TensorRT, an inference engine to run on its hardware, and a software development kit called
Deepstream, which can identify people and objects in high-resolution (HEVC, VP9) video.