
Why can't we ? (True question, I don't get why on the diagram)

Not a diagram
")
I also missed the 2nd last bullet point.
Why can't we ? (True question, I don't get why on the diagram)
Yep, either texturing or RT, but not both at the same time.I also missed the 2nd last bullet point.
You would be surprised.I don't think tex units are busy during egregiously long RTRT pass.
What else did you expect from high level block diagram?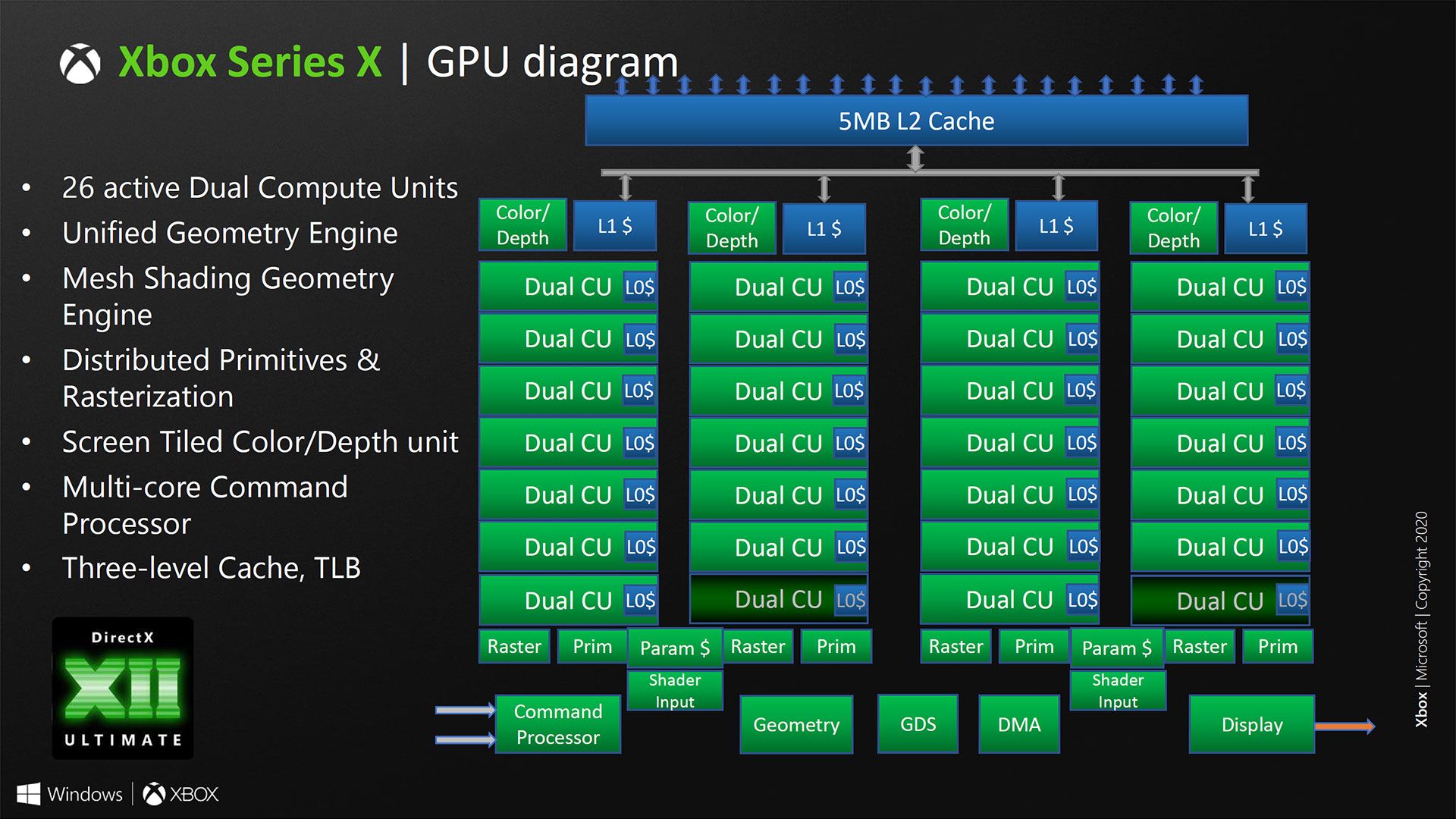
Looking at this, it looks pretty much the same as NAVI10 except there is more cache and more CUs. The shader engines are still the same structure. We can maybe assume RDNA2 cards to be very similar.
Maybe more shader engines or more workgroups per SE. Or they change something big like move some of the functions into or out of the WG. There were rumors that RDNA2 was a big departure from previous architectures but this pretty much confirms that theres nothing big that changed at the high level.What else did you expect from high level block diagram?
What else did you expect from high level block diagram?
The RDNA front-end can issue four instructions every cycle to every SIMD, which include a combination of vector, scalar, and memory pipeline. The scalar pipelines are typically used for control flow and some address calculation, while the vector pipelines provide the computational throughput for the shaders and are fed by the memory pipelines.
The scalar ALU accesses the scalar register file and performs basic 64-bit arithmetic operations.
And I think MS took the option to do this. This is slightly different than just packing in Int8 and Int4 into vector registers listed here:Some variants of the dual compute unit expose additional mixed-precision dot-product modes in the ALUs, primarily for accelerating machine learning inference. A mixed-precision FMA dot2 will compute two half-precision multiplications and then add the results to a single-precision accumulator. For even greater throughput, some ALUs will support 8-bit integer dot4 operations and 4-bit dot8 operations, all of which use 32-bit accumulators to avoid any overflows.
So there is support to hold them in the registers (RDNA 1), but it would appear you need to have a variant of CUs that can perform some of these other 8bit and 4bit operations listed above. I'm going to assume it can just do rapid packed math normally.More importantly, the compute unit vector registers natively support packed data including two half-precision (16-bit) FP values, four 8-bit integers, or eight 4-bit integers
The primitive units assemble triangles from vertices and are also responsible for fixed-function tessellation. Each primitive unit has been enhanced and supports culling up to two primitives per clock, twice as fast as the prior generation. One primitive per clock is output to the rasterizer. The work distribution algorithm in the command processor has also been tuned to distribute vertices and tessellated polygons more evenly between the different shader arrays, boosting throughput for geometry.
Maybe Microsoft will add ML resolution scaling to DirectX. Would be good to have something for it that is hardware agnostic at the API level. Since they are likely just using the shaders to do the inference without the use of tensor cores, it could probably work on any GPU, just depends on the performance they can get out of the hardware for inference while still running the game on the GPU.
Is Microsoft even in the algorithm business?
AMD's explanation of ACE/HWS in the open for OSS Linux drivers partly answered this question.Multi-Core Command Processor > No indication on RDNA 1 about multi-core
Yea that wasn't clear to me either.AMD's explanation of ACE/HWS in the open for OSS Linux drivers partly answered this question.
Ever since the first eight "ACE" GPU, all GPUs come with two "MCE" microcontroller core each of which has four "pipes" (i.e., quad threaded, probably temporal). The initial iterations have all 8 pipes configured as "ACE"s, while later GPUs reappropriated some pipes for GPU multi-process scheduling with support of user mode queue oversubscription (aka "HWS").
Not much information on the graphics CP that I know of though, which has its own core(s?).
It is an optional cog in the graphics pipeline machine after all like the tessellation DLC, so it can hardly escape Graphics CP.I'm not sure where the Mesh Shading Engine would fit in there, I suppose on the GCP side of things.
Doesn't seem like they are explicitly claiming "Graphics Command Processor" being multi-core, unless I have missed something.I also don't know if the multi-core GCP thing is a MS thing.
Is there a generic command processor that is separate from the GCP?It is an optional cog in the graphics pipeline machine after all like the tessellation DLC, so it can hardly escape Graphics CP.
Doesn't seem like they are explicitly claiming "Graphics Command Processor" being multi-core, unless I have missed something.
Given the subtle divergence in terminology, and the absence of ACE/HWS as freestanding colorful blocks, I wouldn't be surprised that "Multi-core Command Processor" is meant to refer to all blocks that eat PM4/AQL packets.Is there a generic command processor that is separate from the GCP?
I was just assuming they were the same thing.
@Rys can you provide any light on this aspect here? I read some of your article on context rolls here, but I don't get it all, and not sure if CP and GCP are being used interchangeably.Given the subtle divergence in terminology, and the absence of ACE/HWS as freestanding colorful blocks, I wouldn't be surprised that "Multi-core Command Processor" is meant to refer to all blocks that eat PM4/AQL packets.
DirectML is just an API for implementing certain classes of DNNs. It won't magically put a superres/supersampling solution in the hands of developers.Obviously most game engines will leverage DirectML because why not?
There is now two distinctions with RDNA 2 RT acceleration:I also missed the 2nd last bullet point.
There is now two distinctions with RDNA 2 RT acceleration:
1- It can't accelerate BVH Traversal, only ray intersections, traversal is performed by the shader cores.
2- Ray Intersections is shared with texture units.
In comparison, Turin RT cores:
1- Accelerate BVH traversal on their own
2- Ray Intersections is independent and is not shared with anything else
So in a sense RDNA 2 solution is hybrid, as it is shared between both textures and shaders compared to Turing's solution.
Not a diagram
I also missed the 2nd last bullet point.
Looking at this, it looks pretty much the same as NAVI10 except there is more cache and more CUs. The shader engines are still the same structure. We can maybe assume RDNA2 cards to be very similar.
A number of the RDNA instruction throughput claims are per-SIMD and there is a diagram with 4 instruction types being considered for issue. That would be 8, although one of the types is vector memory that contends for the same MEM/TEX block, so that's not necessarily out of line since there are two SIMDs per CU.
I've been comparing this slide against RDNA 1 whitepaper and I guess if you're loose with terminology I think everything is exactly the same.
But if you're wanting to be nit picky maybe the following could be different.
Launch 7 instructions/clk per CU vs 4 instructions/clk per CU
I think scalar in this case is the regular math op in the SIMD, rather than packed instructions or some kind of matrix/tensor operation.Second difference I might be seeing here is the:
32 Scalar FP32 FMAD per SIMD, 128 per Dual CU with Data sharing.
It's not really clear if the scalar units can perform a FMAD in the scalar units in the RDNA 1 whitepaper.
A Turing SM has 4 texture units in an SM. A CU has a texture block with 4 texture filtering units.And as result can I infer that RT performance might scale in a very differently on RDNA2 vs Turing.
RT perf on RDNA2 should be closely matched to the number of texture units and shader cores, Whereas on Turing RT perf is more closley determined by the number/amount of dedicated RT resources?
So if your not gonna use RT all that RT hardware on Turing is a waste, if you choose not to do RT on RDNA2, you get more texture units to use..
(assuming a RDNA2 core has more texture units than a Turing core, to compensate for loss due to RT usage. )
And as result can I infer that RT performance might scale in a very differently on RDNA2 vs Turing.
RT perf on RDNA2 should be closely matched to the number of texture units and shader cores, Whereas on Turing RT perf is more closley determined by the number/amount of dedicated RT resources?
So if your not gonna use RT all that RT hardware on Turing is a waste, if you choose not to do RT on RDNA2, you get more texture units to use..
(assuming a RDNA2 core has more texture units than a Turing core, to compensate for loss due to RT usage. )