
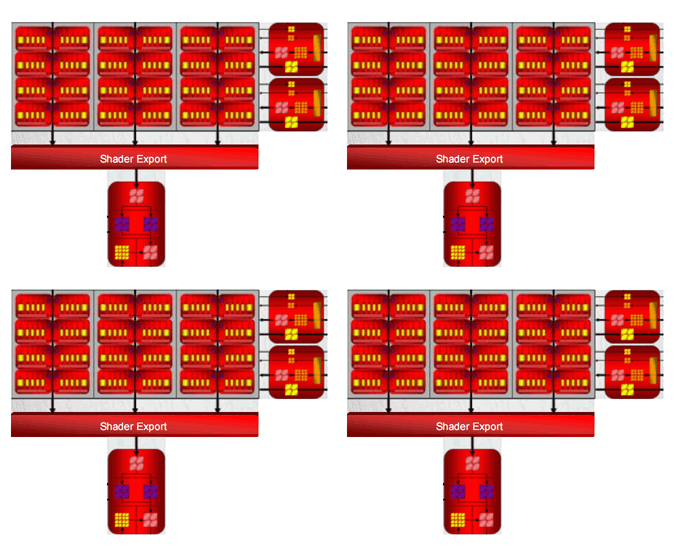
http://forum.beyond3d.com/showpost.php?p=1142518&postcount=936
Is there a possibility that RV770 is surpassing as much on of GX2
because the thread to be able to treat RV770 increases to three times
that of RV670 if this picture is true?
...The catch is, however, whether the chip really has 32 TMUs. Texturing units take up a lot of transistors and if the chip only has over 800 million, they could stay at 16.
=>AnarchX: You're right, they just need to do something to make AF run faster, so perhaps they can just add texture filtering units or improve the current design somehow.
 ). Remember Fusion doesn't have to be single die and it probably won't be. They'll just put PCIe controller on the CPU (how much transistors could 4 or 8 lanes cost?) and Fusion will be an MCM (multi-chip module - two dies under one heatspreader).
). Remember Fusion doesn't have to be single die and it probably won't be. They'll just put PCIe controller on the CPU (how much transistors could 4 or 8 lanes cost?) and Fusion will be an MCM (multi-chip module - two dies under one heatspreader).http://www.tomshardware.com/news/ati-radeon-4800,5223.htmltomshardware said:The RV770 GPU is equipped with a 256-bit memory controller (512-bit for the Radeon 4870 X2: The R700 represents just two RV770 GPUs slapped together).
tomshardware said:4870 X2 is an interesting version. AMD did not send out any specs to its partners and it is expected the board will be a bit more than just a 3870 X2 two RV770 GPUs. ATI is said to be making some changes,
TSMC doesn't do SOI, so no. Seems to me that we'll never see an ATi GPU manufactured in AMD fabs, since AMD does not have the needed capacity and there are even rumours about AMD wanting to sell one of their Dresden fabs (Hector's asset light strategy
No, it will be the same as with R680.
That's pretty much exactly I'm expecting to happen, i.e. that the two chips will have a unified memory space and it will take ages for performance to get there.If they implemented some kind of innovative memory access technology, it would again take them half a year to cough out good drivers for it.
That's pretty much exactly I'm expecting to happen, i.e. that the two chips will have a unified memory space and it will take ages for performance to get there.
Jawed
I agree however some benefits will be apparent from the word go, remeber indications look like a june or later release.
That's pretty much exactly I'm expecting to happen, i.e. that the two chips will have a unified memory space and it will take ages for performance to get there.
Jawed