Hello,
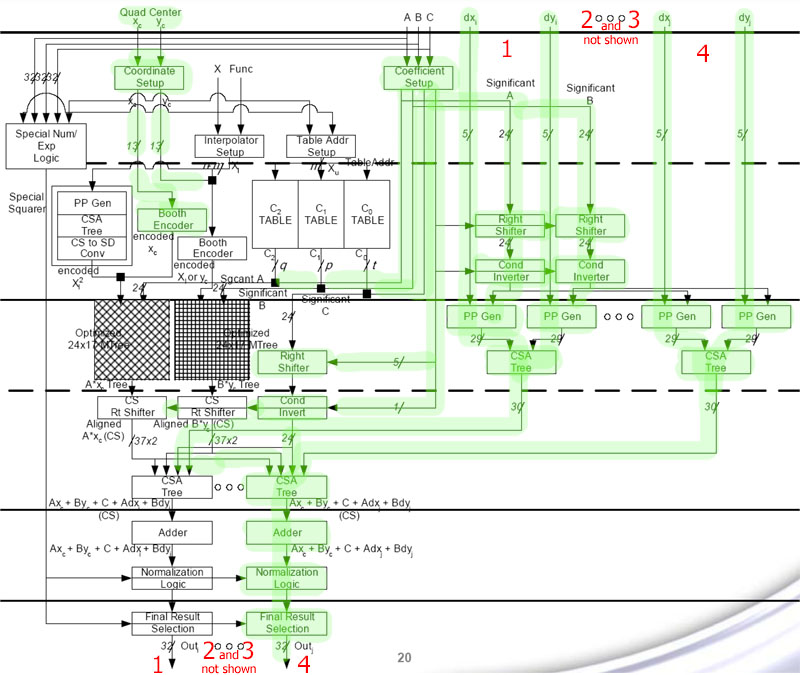
While I was going through the B3d G80 tech article I came across this
from the nv FUD
I'm confuses, the B3D article says the SF operations are done on the shader cores, while he nv FUD doc says it has 128 SFU for SF operations. I'm sure that both are correct, and that I have missed something out, can you point it out and eplain?
Thanx a lot
While I was going through the B3d G80 tech article I came across this
Attribute interpolation for thread data and special function instructions are performed using combined logic in the shader core. Our testing using an issue shader tailored towards measuring performance of dependant special function ops -- and also varying counts of interpolated attributes and attribute widths -- shows what we believe to be 128 FP32 scalar interpolators, assigned 16 to a cluster (just as SPs are).
from the nv FUD
Geforce 8800 has 128 standard ALUs and 128 SFUs
I'm confuses, the B3D article says the SF operations are done on the shader cores, while he nv FUD doc says it has 128 SFU for SF operations. I'm sure that both are correct, and that I have missed something out, can you point it out and eplain?
Thanx a lot