Yeah, so a desktop PC with eight cores at a minimum is going to be fine for level loading at the maximum rate of a commodity SSD. Remember, Zen2 is prior architecture -- and I've been panned for insinuating consoles are at a CPU deficit. Guess what? Consoles are at a CPU deficit compared to desktops.
And what of gamers without "commodity SSD's"? According to Microsofts own numbers an 8 core Zen 2 you would top out at around around 3.8GB/s which counts out the majority of PCIe4 SSD's. Granted most PC Zen 2 or higher performing CPU's have a per core performance advantage over the console CPU's but not enough to change the overall conclusion. And there are still plenty of PC gamers rocking 6 or even 4 core systems, or older 8 core systems. And again, this assumes perfect scaling across all CPU cores which you'll likely never get.
You're conflating terms here. CPU consumption isn't directly a function of I.O bandwidth, in fact you can achieve maximum disk bandwidth with relatively tiny amount of I/O and related CPU.
Not the game loading scenario's that Microsoft is talking about which utilise many small IO requests. To saturate higher bandwidth under that scenario it stands to reason you'd have to make many more IO requests and this would increase the CPU overhead accordingly.
Part of this goes back to file management of the game itself, which should be obvious now.
Yes there is no argument there. My original post on this matter stated that the two issues that needed to be overcome where the bottlenecks on the PC IO stack, and the way the game code itself handles IO. Fixing one without the other will have limited or no success. Hence why lots of new gen console back compat games don't have crazy fast load times.
Honestly? All of them. It's a level load! We aren't actively playing the game here, we're waiting to play the game. Want to make an argument about GPU decompression? Great, but you can't buy a "gaming" desktop today with less than eight CPU threads, that gives you six more threads for doing... something else.
I think your maths has gone wrong somewhere there. I (extrapolating Microsoft's own figures) said 15 cores, not threads. That's 30 threads so I'm not sure where the argument about 8 thread CPU's fits in, and even less so the point about having 6 threads left over. Even just the decompression alone would saturate 8.75 cores on a 7GB/s drive which puts it out of reach for the majority of gamers even if you ignore IO overhead completely.
Writes are far less painful than reads, especially asynchronous writes (which would be indicative of recording your streamed video game to a video file.) Reads are pathalogical because they're blocking operations; writes are not blocking unless you have a specific need for 100% data integrity, which isn't what any of the commodity streaming recording studio software is doing. Writes are cached and coalesced by the OS and then written to disk as a few, large contiguous blocks rather than scattered in zillions of individual I/Os (aka, random reads.)
I was talking about in game asset streaming. Not live streaming a video feed. i.e. loading data from the SSD at the same time as you need your CPU to actually run the game. Granted, streaming will be at a much lower rate than load times, but it's also far more important to keep the CPU load low when doing it. You also still have the potential for bursts of high bandwidth streaming which you don't want to tank your framerate because half your CPU is busy dealing with the IO and decompression.
Explanation is simple: they aren't waiting on disk.
Yes that's the point.
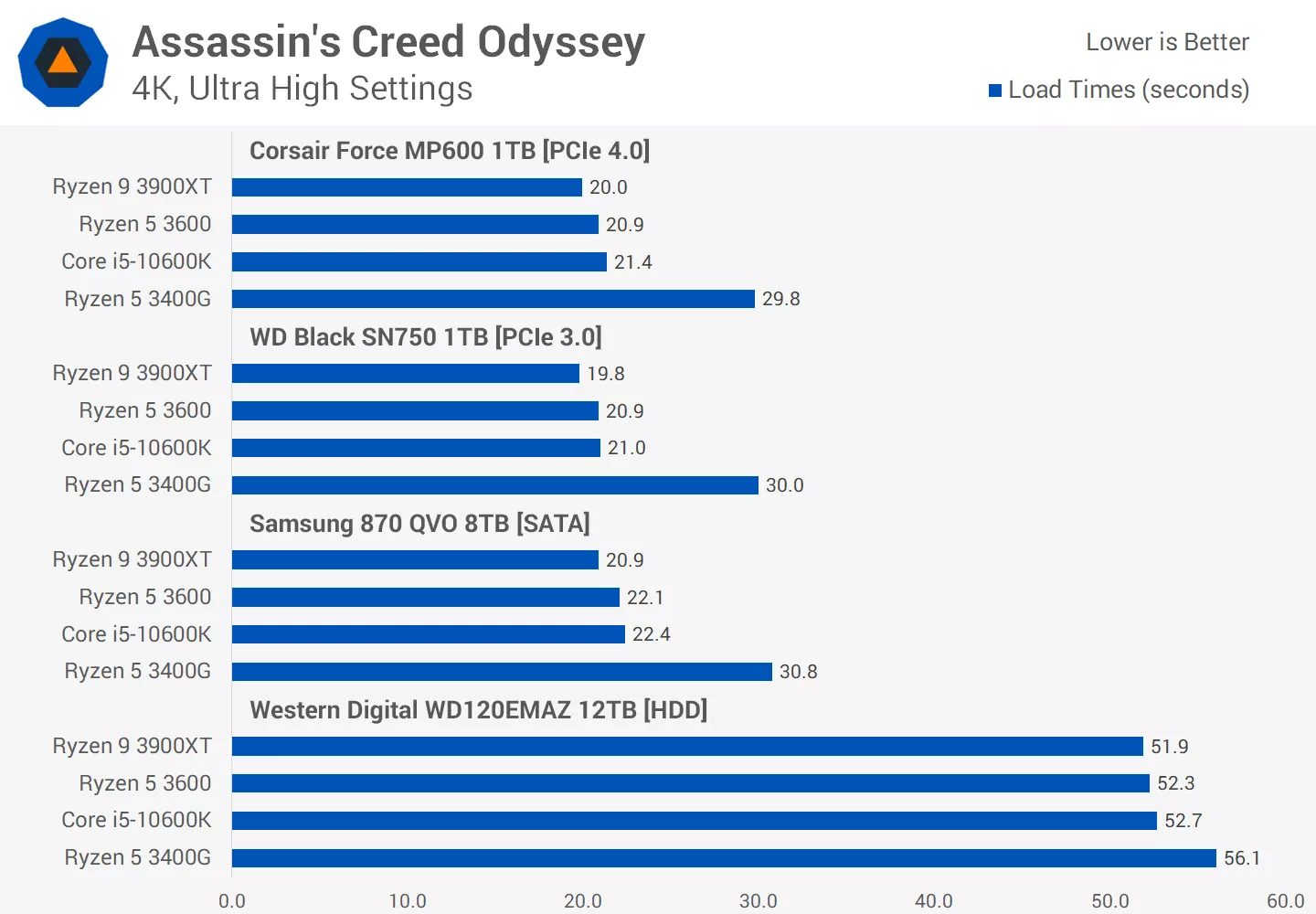
The level load time shows literally nothing about describing a bottleneck, pro or con.
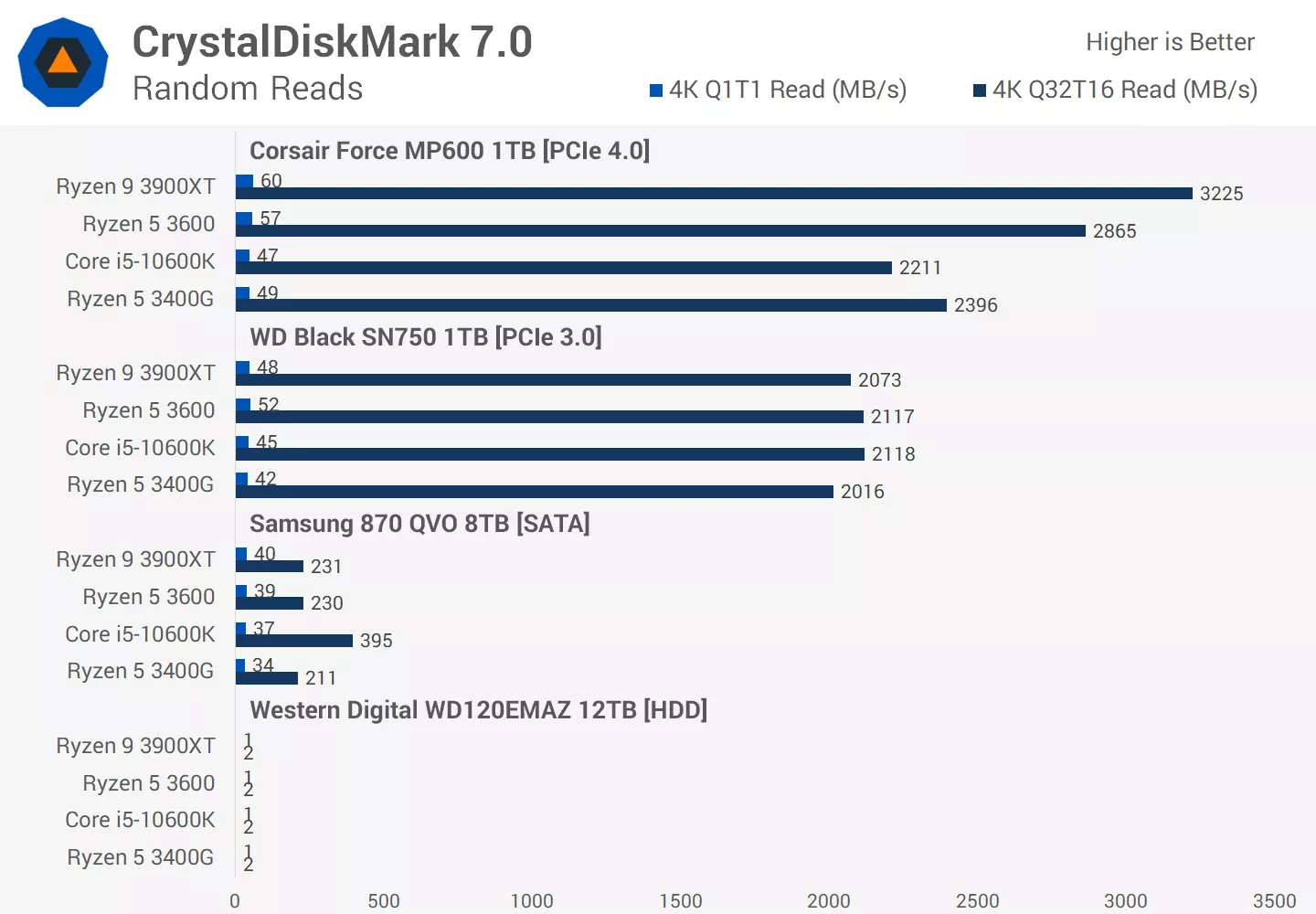
Those benchmarks show is precisely that there is a bottleneck in the system that is not the drive itself. So where does that bottleneck sit, and why? Generally the answer is on the CPU once you pass a certain threshold of drive speed:
https://www.techspot.com/review/2117-intel-vs-amd-game-loading-time/
The CPU bottlenecks will obviously be down to different factors, not all IO related, but IO and decompression will certainly be a factor there. So once they're largely removed by Direct Storage, the remaining bottleneck will primarily be the game code itself and ensuring that's written correctly to maximise the IO systems capabilities.