
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
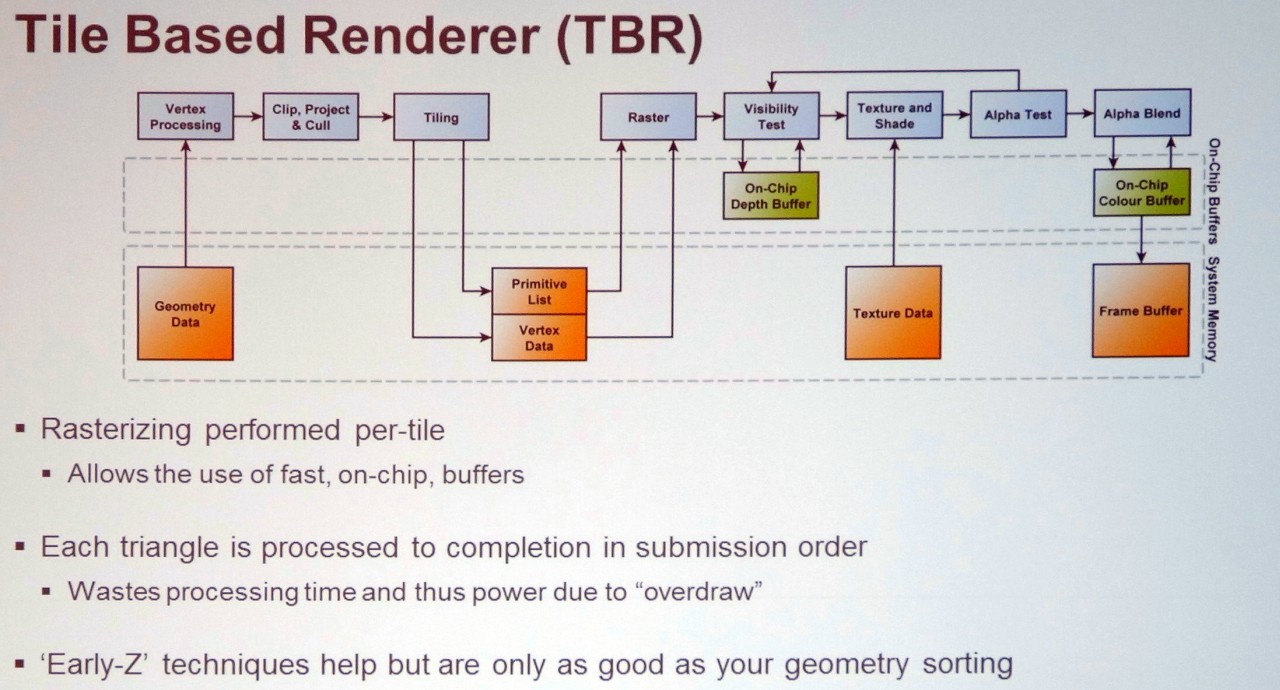
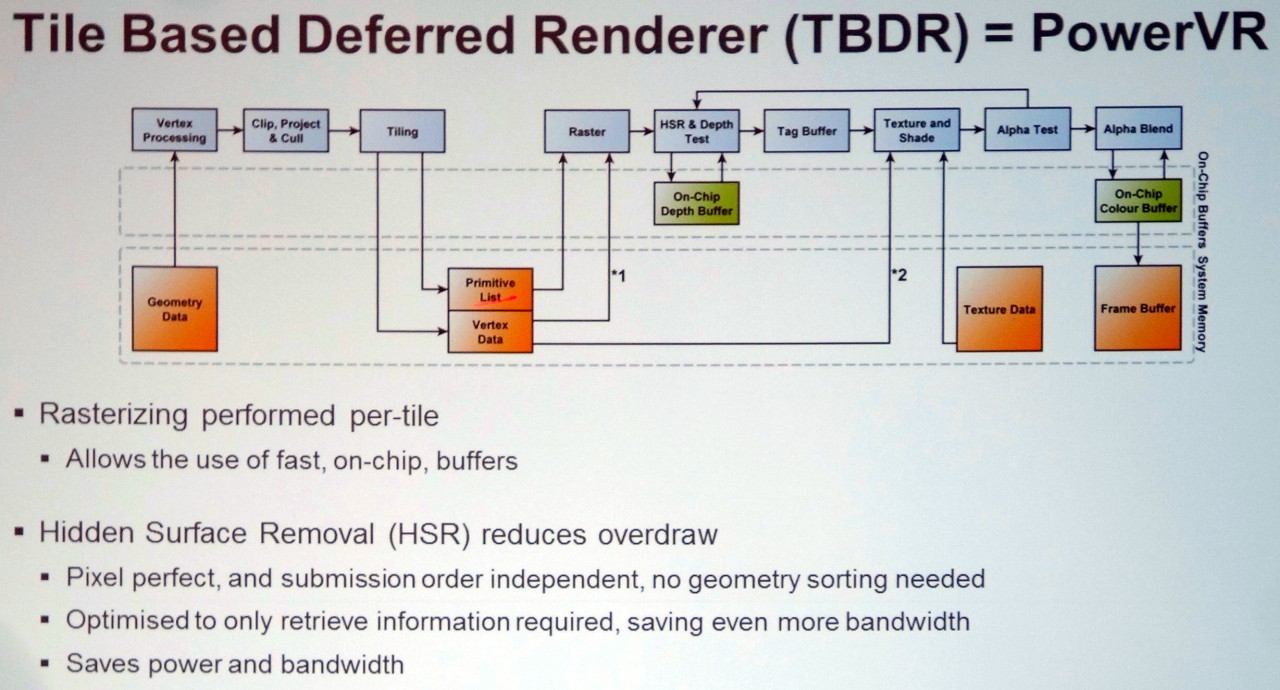
and TBDR is not the exact same thing as TBR ?
I don't think I ever implied that they were the "exact same thing" other than the fact that they share comparably many more implications to the driver design than either a TBR/TBDR would to an IMR. I simply think it's more fair to group TBR and TBDR together than it is to group TBR/TBDR with IMRs from a driver standpoint ...
Modern IMRs most definitely do break primitives down into screen space tiles to render them, there was even a thread on here a while back where someone managed to demonstrate this visually. This was a fundamental shift for IMR's that was required to fix the memory BW bottleneck for ROPs, in particular for multi-pass post processing ops.The only similarity between their tiling is that they can be used for exploiting spatial locality but it ends there. IMRs don't use tiling to break up rendering into screenspace tiles and store their framebuffer state to on-chip memory like a TBR architecture would ...
I'm pretty sure some TBR GPUs emulate geometry shaders on the CPU and I can't be certain but some of them out there might even use compute shaders to emulate geometry shaders. Are there any pure TBR architectures out there that natively support geometry shaders ?
I can't comment on specific architectures other than to say I know at of least 3 TB(D)R architectures that directly implement the GS stage, I know of 1 that uses compute for tessellation. Note that emulation does not impact tiling optimisations.
If a hypothetical TBR architecture did implement transform feedbacks then it has pretty much already lost. Transform feedbacks requires an ordered output with respect to the input data. Transform feedback interacts with the varyings. If transform feedback is enabled during varying shading then it must output the varying data with the corresponding input order. On tilers, varying shading is done on a per-tile basis so the output order for the varyings won't exactly match the input order since tilers can skip processing primitives that lie outside of the tile boundary. It could be possible to preserve the ordering by doing roundtrips to memory but at that point it might be more sane to design IMRs instead ...
The bolded part is not generically true of TB(D)R architectures, I know of at least 2 that don't do this. Further it is entirely possible to split the geometry pipeline at any point before tiling in order to retain sequential processing, so its relatively trivial to make the two pass approach work as well.
You might correctly suggest that this costs additional BW, and yes this is a negative. However in most practical cases that extra BW isn't sufficient to invalidate the TB(D)R approach.
I don't think this is necessarily true because on IMRs it's trivial to just change renderpasses with nearly no discernable performance impact. Mobile IHVs recommend the exact opposite by minimizing changing the renderpasses. Many TBR GPU drivers also don't support dual source blending or logical operations compared to IMRs where they've been standard functionality on IMRs since D3D11 ? On a few IMRs, it's not necessary to bake the blend state into PSOs so they have the potential advantage of not needing to do recompilations if the blend state changes compared to TBRs. On TBR GPUs, it's possible to expose pixel local storage on those devices while the same can't be said for IMRs. In the near future, IMRs will have a standardized mesh shading pipeline in stark contrast to TBR architectures which currently shows no signs of them going in the same direction ...
I certainly wouldn't describe these differences as being 'indistinguishable' ...
These are all implementation specific details or feature levels related to the targeted platforms, none are limitations of TB(D)R as an architectural approach.
Modern IMRs most definitely do break primitives down into screen space tiles to render them, there was even a thread on here a while back where someone managed to demonstrate this visually. This was a fundamental shift for IMR's that was required to fix the memory BW bottleneck for ROPs, in particular for multi-pass post processing ops.
How can you be so certain that tiling is contributing to the majority uplift in ROP performance rather than framebuffer/render target compression technology ? Even with tiling on IMRs, the draws are rendered out of order in the vast majority of the cases rather than in order as we can reasonably expect from a TB(D)R architecture ...
I can't comment on specific architectures other than to say I know at of least 3 TB(D)R architectures that directly implement the GS stage, I know of 1 that uses compute for tessellation. Note that emulation does not impact tiling optimisations.
Emulation is often not what I'd describe to be a robust solution ...
Mali GPU architectures are infamous for emulating geometry shaders on the CPU. Adreno GPUs are actually hybrid where you can enable/disable the tiling stage so it leaves me curious about their behaviour in the presence of geometry shaders/tessellation/transform feedbacks but I wouldn't be surprised if their driver disabled the tiling stage in those cases instead changed to an IMR pipeline. If we take the Metal API as a reference mostly for IMG GPUs, it doesn't inspire much confidence about their implementation (if there is any at the hardware level) since Apple doesn't expose geometry shaders at all ...
The bolded part is not generically true of TB(D)R architectures, I know of at least 2 that don't do this. Further it is entirely possible to split the geometry pipeline at any point before tiling in order to retain sequential processing, so its relatively trivial to make the two pass approach work as well.
You might correctly suggest that this costs additional BW, and yes this is a negative. However in most practical cases that extra BW isn't sufficient to invalidate the TB(D)R approach.
When you say "most practical cases" are you talking about low-end graphics on mobile devices or are you including cases like modern AAA games too where data keeps exponentially growing every several years ? With the latter I don't see that to be an insignificant amount of additional BW usage so how viable do you suppose a TB(D)R architecture would be in that scenario ?
I can be 100% certain because it's what I do for a living ;-) Seriously, practically FB compression is somewhat limited when compare to the benefits of tiling, consider complete elimination of interpass BW for tiling vs maybe 50% reduction for read/writing compressed, it's a night and day thing.How can you be so certain that tiling is contributing to the majority uplift in ROP performance rather than framebuffer/render target compression technology ?
And? Exactly what legal reordering optimisations do you think can't be applied to TB(D)R's and why?Even with tiling on IMRs, the draws are rendered out of order in the vast majority of the cases rather than in order as we can reasonably expect from a TB(D)R architecture ...
Emulation is often not what I'd describe to be a robust solution ...
That's simply a function of how well it's done or if it's there because underlying missing functionality.
However as I said before, these things are design choices that have nothing to do with an architecture being TB(D)R or not.
I can't really comment on the crappyness (or not) of ARM's Mali drivers.Mali GPU architectures are infamous for emulating geometry shaders on the CPU. Adreno GPUs are actually hybrid where you can enable/disable the tiling stage so it leaves me curious about their behaviour in the presence of geometry shaders/tessellation/transform feedbacks but I wouldn't be surprised if their driver disabled the tiling stage in those cases instead changed to an IMR pipeline. If we take the Metal API as a reference mostly for IMG GPUs, it doesn't inspire much confidence about their implementation (if there is any at the hardware level) since Apple doesn't expose geometry shaders at all ...
I'm not aware of the specific cases that Adreno drops back to "IMR" mode (outside of some obvious corner cases), although I'm reasonably sure that it isn't often as you think. Further I think its very interesting how easily you breeze over the switching between IMR and TB(D)R modes, you know, an architecture that's doing both when you claim they're so far apart?
All cases. The exponential growth of data has generally impacted the volume of geometry data less than pixel processing data. The later is where TB(D)Rs tend to excel, but in general that growth impacts both approaches to a similar extent.When you say "most practical cases" are you talking about low-end graphics on mobile devices or are you including cases like modern AAA games too where data keeps exponentially growing every several years ? With the latter I don't see that to be an insignificant amount of additional BW usage so how viable do you suppose a TB(D)R architecture would be in that scenario ?
You might point at UE5's use of micro polygons, but for the most part that case benefits neither architecture as it's a SW renderer executed on GPU compute. RT also further shifts us away from IMR vs TB(D)R, although the later makes a lot of sense in terms of the emission and management of inflight rays.
By the way, my personal view is that the best approach lies somewhere in the middle. However to suggest that many features are incompatible with TB(D)R or they are inherently difficult to use is simply wrong.
I can be 100% certain because it's what I do for a living ;-) Seriously, practically FB compression is somewhat limited when compare to the benefits of tiling, consider complete elimination of interpass BW for tiling vs maybe 50% reduction for read/writing compressed, it's a night and day thing.
FB/RT compression works very well with many of the usage patterns in modern AAA games. How would the tiling observed from TB(D)R be even compatible with the usage patterns seen in modern AAA games where they can freely switch between different FB/RT ? Switching between different FB/RT will often cause flushing to the on-chip memory with tiling architectures which is practically a performance killer ...
And? Exactly what legal reordering optimisations do you think can't be applied to TB(D)R's and why?
I think the tiling between IMRs and other tiling architectures are more profoundly different than what you would suggest ...
On TB(D)R architectures, they sort draws/primitives into bins for each tile and they then render from draw 0 to draw N in order per tile. There's a significant amount of batching going on in that example ...
On IMRs, the tiles are literally guaranteed to be flushed after every draw call so tiling in this case doesn't help reduce the memory traffic when the overdraw is spanning through multiple draw calls. Doing things this way is actually mostly consistent with the traditional IMR pipeline and their drivers. The behaviour I described before with TB(D)R doesn't match up at all with that model ...
Tiling on IMRs will not necessarily confer the same benefits or even drawbacks compared to TB(D)R architectures. The gains in reduced memory traffic by using tiling on IMRs are no where near as pronounced as you would believe them to be since it is very likely that tiles will often be accessed multiple times in their same screenspace locations during rendering and consequently this means that they don't have the same repercussions as TB(D)R architectures do when swapping different FB/RTs ...
That's simply a function of how well it's done or if it's there because underlying missing functionality.
However as I said before, these things are design choices that have nothing to do with an architecture being TB(D)R or not.
For them being design choices, there's an awfully high amount of correlation between their architecture and implementation quality of these features so your argument rests that this is somehow supposed to be a coincidence ?
I can't really comment on the crappyness (or not) of ARM's Mali drivers.
I'm not aware of the specific cases that Adreno drops back to "IMR" mode (outside of some obvious corner cases), although I'm reasonably sure that it isn't often as you think. Further I think its very interesting how easily you breeze over the switching between IMR and TB(D)R modes, you know, an architecture that's doing both when you claim they're so far apart?
If IMRs and TB(D)R architectures were similar as you imply them to be then why do Nvidia and Qualcomm design their drivers so differently around their tiling functionality ? On Nvidia HW, tiling is very nearly implicit since it can only be triggered by the driver so there's almost no ways for the developers to directly control this behaviour while on Qualcomm HW, there are several options to explicitly control their tiling behaviour with extensions or APIs like renderpasses ...
All cases. The exponential growth of data has generally impacted the volume of geometry data less than pixel processing data. The later is where TB(D)Rs tend to excel, but in general that growth impacts both approaches to a similar extent.
You might point at UE5's use of micro polygons, but for the most part that case benefits neither architecture as it's a SW renderer executed on GPU compute. RT also further shifts us away from IMR vs TB(D)R, although the later makes a lot of sense in terms of the emission and management of inflight rays.
Micropolygon rendering in UE5 can see usage of primitive shaders on the PS5 which features mostly an IMR GPU. For a more standard example of micropolygon rendering, I can also point you to Nvidia's Asteroids mesh shaders demo ...
Neither primitive or mesh shaders have been implemented so far on TB(D)R architectures ...
I agree it does work quite well, but to say it again it isn't sufficient to solve the back end ROP BW issue, not even close.FB/RT compression works very well with many of the usage patterns in modern AAA games.
There's two answer's here. The first is that it's a non problem, switching without any flushing was solved 20 years ago by PowerVR (I can't explain why Apple would chose not to exploit this capability). The other is that flushing doesn't need to be a big issue, fundamentally it has to be solved for other reasons e.g. back to back small renders.How would the tiling observed from TB(D)R be even compatible with the usage patterns seen in modern AAA games where they can freely switch between different FB/RT ? Switching between different FB/RT will often cause flushing to the on-chip memory with tiling architectures which is practically a performance killer ...
There's no requirement to guarantee a flush between draw calls in the IMR case, that's driven by resource usage, other than that I largely agree so far...I think the tiling between IMRs and other tiling architectures are more profoundly different than what you would suggest ...
On TB(D)R architectures, they sort draws/primitives into bins for each tile and they then render from draw 0 to draw N in order per tile. There's a significant amount of batching going on in that example ...
On IMRs, the tiles are literally guaranteed to be flushed after every draw call so tiling in this case doesn't help reduce the memory traffic when the overdraw is spanning through multiple draw calls. Doing things this way is actually mostly consistent with the traditional IMR pipeline and their drivers. The behaviour I described before with TB(D)R doesn't match up at all with that model ...
I agree up to here...Tiling on IMRs will not necessarily confer the same benefits or even drawbacks compared to TB(D)R architectures. The gains in reduced memory traffic by using tiling on IMRs are no where near as pronounced as you would believe them to be since it is very likely that tiles will often be accessed multiple times in their same screenspace locations during rendering
Here you go back assuming that switching RT's is implicitly an issue, as answered above, it isn't.and consequently this means that they don't have the same repercussions as TB(D)R architectures do when swapping different FB/RTs ...
Assuming correlation equals causation is a common mistake. I know the things you're raising don't need to be issues, but I can't contest what you might see in the field, however there's two things that have nothing to do with TB(D)R architectures that influence what you see,For them being design choices, there's an awfully high amount of correlation between their architecture and implementation quality of these features so your argument rests that this is somehow supposed to be a coincidence ?
1) Quality is a function of ecosystem fragmentation and device SW maintenance, this is a particular problem for Android devices.
2) Feature availability IS functional of platform requirements
In most TB(D)Rs the tiling is also mostly implicit, flushing is driven is much the same way as it is for IMR's, although they may work harder to avoid it.If IMRs and TB(D)R architectures were similar as you imply them to be then why do Nvidia and Qualcomm design their drivers so differently around their tiling functionality ? On Nvidia HW, tiling is very nearly implicit since it can only be triggered by the driver so there's almost no ways for the developers to directly control this behaviour while on Qualcomm HW, there are several options to explicitly control their tiling behaviour with extensions or APIs like render passes ...
Qualcomms control have always seemed strange to me, for the logic behind them you would have to ask them.
The point is UE5 on the PS5 is an example of how this discussion may become moot. A demonstration of an Nvidia feature written by Nvidia is somewhat less representative of reality.Micropolygon rendering in UE5 can see usage of primitive shaders on the PS5 which features mostly an IMR GPU. For a more standard example of micropolygon rendering, I can also point you to Nvidia's Asteroids mesh shaders demo ...
And we go back to point of about target platforms and required features not being indicative of an architecture limitations.Neither primitive or mesh shaders have been implemented so far on TB(D)R architectures ...
Not a GPU but I don't see why it should have a dedicated thread: https://www.imaginationtech.com/vision-ai/img-series4-nna/
Imagination Tensor Tiling sounds quite interesting.
Imagination Tensor Tiling sounds quite interesting.
Similar threads
- Replies
- 26
- Views
- 6K
- Replies
- 3
- Views
- 827
- Replies
- 6
- Views
- 6K