
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia Ampere Discussion [2020-05-14]
- Thread starter Man from Atlantis
- Start date
-
- Tags
- nvidia
that's a nice discovery, 'cos right now MSi Afterburner has auto OC, and it is working well for me. MSI Afterburner seems to use some kind of undervolt. But if it adapts to your computer's PSU -dunno how-, that's another reason to leave MSi Afterburner -maybe-.I wonder if the beta Automatic Tuning feature could accomplish a similar result.
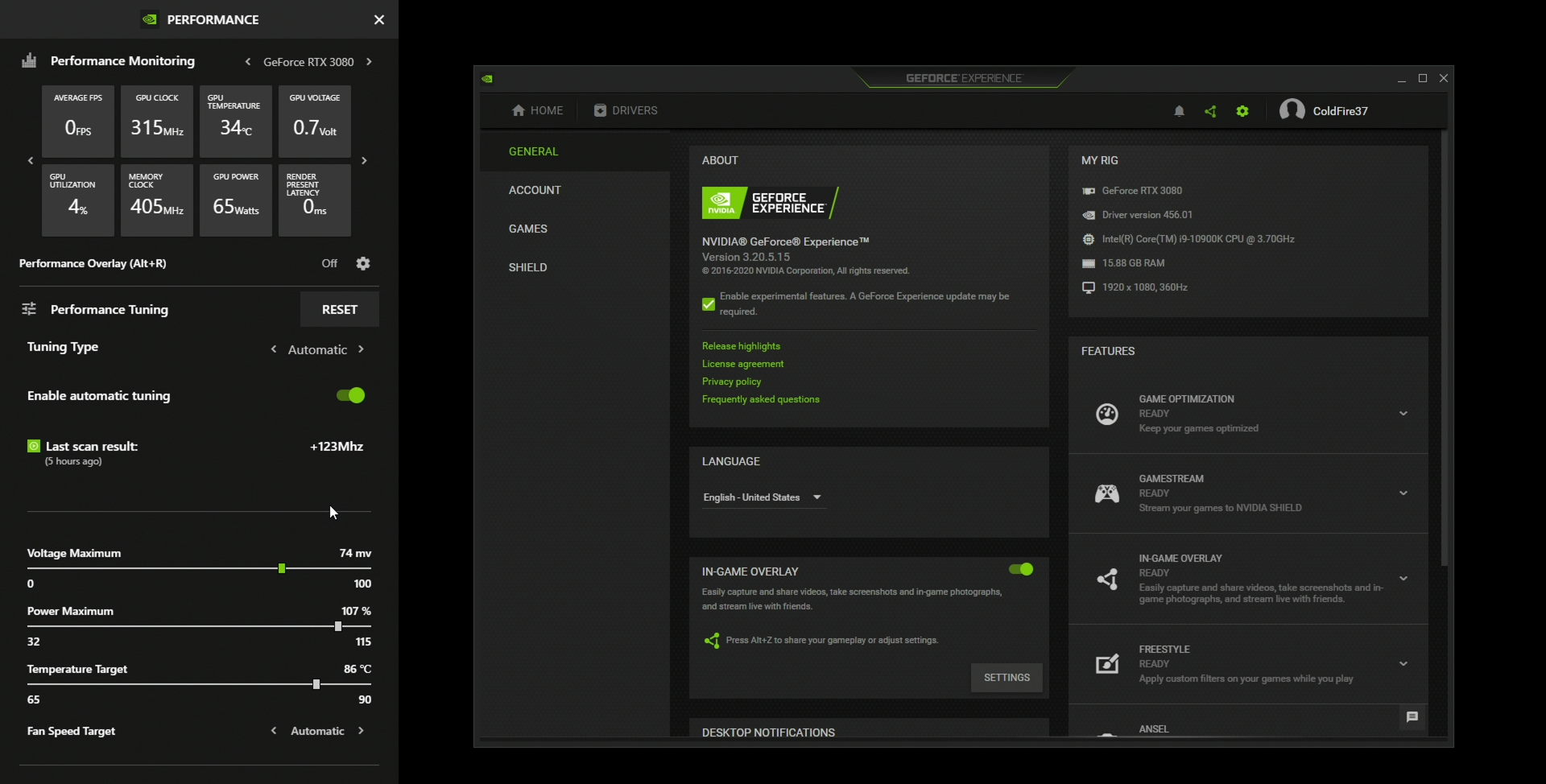
https://www.nvidia.com/en-us/geforc...tform/#automatic-tuning-in-geforce-experience
to sum some things up.
- CUDA Cores: int32 and fp32 operations are indifferently performed by a CUDA core. That's HUGE!! as shown by the graph below --no specific cuda cores for int32 and fp32 operations. Means: no idle int32 or fp32 cores because cuda cores either perform floating point or integer operations. (games perform around 20-30% operations in int32 format)
- Where you will notice the generational leap is in the fact that new GPUs perform muh better raytracing denoising.
- IMO, where series 3000 destroys previous generations is in RT games, which is the way to go.
- The 3070 performs as the 2080Ti despite having 20 teraflops vs 13 teraflops. This shows how different they are now -this imho means again, that where they truly shine is at RT games.

that's a nice discovery, 'cos right now MSi Afterburner has auto OC, and it is working well for me. MSI Afterburner seems to use some kind of undervolt. But if it adapts to your computer's PSU -dunno how-, that's another reason to leave MSi Afterburner -maybe-.
Yah, one way people undervolt is to let oc scanner in afterburner run and generate a curve. Then they know what frequency is stable at each voltage. So you kind flatten out from whatever frequency you have as your target. I would not be surprised if you can push things a little bit more manually, but it's a good starting point. You should be able to do the same with the power limit adjusted up or down. This nvidia tool looks like it can do the same thing, but if it requires geforce experience I'm not sure that I want it.
to sum some things up.
- CUDA Cores: int32 and fp32 operations are indifferently performed by a CUDA core. That's HUGE!! as shown by the graph below --no specific cuda cores for int32 and fp32 operations. Means: no idle int32 or fp32 cores because cuda cores either perform floating point or integer operations. (games perform around 20-30% operations in int32 format)
- Where you will notice the generational leap is in the fact that new GPUs perform muh better raytracing denoising.
- IMO, where series 3000 destroys previous generations is in RT games, which is the way to go.
- The 3070 performs as the 2080Ti despite having 20 teraflops vs 13 teraflops. This shows how different they are now -this imho means again, that where they truly shine is at RT games.
Not true. Supported modes are only 128+0 or 64+64.
Not sure about that. Isn't it really per SM partition? It should be at least. 32+0 or 16+16. I'm splitting hairs like this, because that's leaving the pure FP32 block idle only when you have a 1:2 ratio of FP vs. INT (and underutilized at anything less than 1:1).Not true. Supported modes are only 128+0 or 64+64.
In other news, and because it was mentioned earlier: This makes paper-TFlops IMO actually more comparable between Nvidia and AMD('s current gen), since now INT-ops go against the TFlops budget on both sides, where as they were kind of free on Nvidia with Turing, making it overperform wrt to its TFlops rating.
This picture is inaccurate. The GTX 1080 should be twice as fast as shown. It’s execution units are 32-wide vs the 16-wide units in Ampere and Turing.
agent_x007
Newcomer
I do it like this :Yah, one way people undervolt is to let oc scanner in afterburner run and generate a curve. Then they know what frequency is stable at each voltage. So you kind flatten out from whatever frequency you have as your target. I would not be surprised if you can push things a little bit more manually, but it's a good starting point. You should be able to do the same with the power limit adjusted up or down.
agent_x007
Newcomer
Shouldn't that split be like this :Not sure about that. Isn't it really per SM partition? It should be at least. 32+0 or 16+16. I'm splitting hairs like this, because that's leaving the pure FP32 block idle only when you have a 1:2 ratio of FP vs. INT (and underutilized at anything less than 1:1).
128:0 = 4x16 [FP32 fixed] + 4x16 FP32 ["mixed" units]
64:64 = 4x16 [FP32 fixed] + 4x16 INT32 ["mixed" units]
?
Shouldn't that split be like this :
128:0 = 4x16 [FP32 fixed] + 4x16 FP32 ["mixed" units]
64:64 = 4x16 [FP32 fixed] + 4x16 INT32 ["mixed" units]
?
No, instruction dispatch is handled independently each clock in each of the 4 SM partitions. Each partition has 16 FP32 fixed + 16 FP32/INT32 mixed pipelines. The mix of instructions each clock can be different between partitions in the same SM.
Maybe this is normalized to the same number of ALUs?This picture is inaccurate. The GTX 1080 should be twice as fast as shown. It’s execution units are 32-wide vs the 16-wide units in Ampere and Turing.
Each SM-Partition (i.e. block consisting of 256kiB RF, 16xINT32, 16xFP32, 4xL/S, 4xSFU) has its own scheduler and dispatch, so they should be able to operate independently.Shouldn't that split be like this :
128:0 = 4x16 [FP32 fixed] + 4x16 FP32 ["mixed" units]
64:64 = 4x16 [FP32 fixed] + 4x16 INT32 ["mixed" units]
?
I wasn't sure how granular the split could be but Computerbase.de states its either 128FP or 64FP + 64INT. I figured it was a scheduling limitation of some type and would help explain the performance scaling deficit. With finer grained scheduling and higher utilization i would have expected the dramatic increase in core counts to result in a bigger performance increase even with other possible bottlenecks.Not sure about that. Isn't it really per SM partition? It should be at least. 32+0 or 16+16. I'm splitting hairs like this, because that's leaving the pure FP32 block idle only when you have a 1:2 ratio of FP vs. INT (and underutilized at anything less than 1:1).
In other news, and because it was mentioned earlier: This makes paper-TFlops IMO actually more comparable between Nvidia and AMD('s current gen), since now INT-ops go against the TFlops budget on both sides, where as they were kind of free on Nvidia with Turing, making it overperform wrt to its TFlops rating.
Last edited:
DegustatoR
Veteran
Bandwidth, CPU, etc are still there. The more shading limited Ampere is - the closer it gets to its peak flops.I wasn't sure how granular the split could be but Computerbase.de states its either 128FP or 64FP + 64INT. I figured it was a scheduling limitation of some type and would help explain the performance scaling deficit. With finer grained scaling and higher utilization i would have expected the dramatic increase in core counts to result in a bigger performance increase even with other possible bottlenecks.
Bandwidth, CPU, etc are still there. The more shading limited Ampere is - the closer it gets to its peak flops.
What is the level of granularity for FP and INT scheduling per SM?
DegustatoR
Veteran
As others said: either 16+16 FP32 or 16+16 FP32+INT.What is the level of granularity for FP and INT scheduling per SM?
Not sure why Nvidia would invest in more control logic (scheduler, dispatch, compared to Pascal) if not for more fine grained control. Haven't been in the briefings, so this is just me making assumptions, though.I wasn't sure how granular the split could be but Computerbase.de states its either 128FP or 64FP + 64INT. I figured it was a scheduling limitation of some type and would help explain the performance scaling deficit. With finer grained scheduling and higher utilization i would have expected the dramatic increase in core counts to result in a bigger performance increase even with other possible bottlenecks.
BTW I think TFlops was a somewhat fair indicative between turing and navi 10 gaming performance, but ampere is definitely another kind of beast. Nvdia said 14.2TFlop for 2080 Ti FE at 1635Mhz boost, and AMD 9.7 for 5700 XT at 1905Mhz, but 2080 Ti FE real gaming median clock is 1830Mhz and 1890Mhz for 5700 XT, so should be around 16TFlop and 9.5TFlop...in latest TPU performance chart, 2080 Ti is 50% faster at gaming 4K, so looks like neck and neck or even AMDs TFlops are already a bit ahead there.Not sure about that. Isn't it really per SM partition? It should be at least. 32+0 or 16+16. I'm splitting hairs like this, because that's leaving the pure FP32 block idle only when you have a 1:2 ratio of FP vs. INT (and underutilized at anything less than 1:1).
In other news, and because it was mentioned earlier: This makes paper-TFlops IMO actually more comparable between Nvidia and AMD('s current gen), since now INT-ops go against the TFlops budget on both sides, where as they were kind of free on Nvidia with Turing, making it overperform wrt to its TFlops rating.
Jawed
Legend
Which tests demonstrate this?Bandwidth, CPU, etc are still there. The more shading limited Ampere is - the closer it gets to its peak flops.
not too shabby. Still for my PC's psu in particular, the 3070 -still waiting for what AMD is going to show in november- seems the best value.
https://videocardz.com/newz/nvidia-details-geforce-rtx-30-ampere-architecture (screengrab from this article)

Are the die sizes and transistor counts from Nvidia directly? I haven't seen the numbers mentioned anywhere else. And the RTX 3070 uses 16 Gbps GDDR6 dosen't it?
Similar threads
- Replies
- 49
- Views
- 7K
- Replies
- 98
- Views
- 32K
- Replies
- 1
- Views
- 7K