
https://www.anandtech.com/show/12170/nvidia-titan-v-preview-titanomachy/2
https://www.anandtech.com/show/12170/nvidia-titan-v-preview-titanomachy/2
Hi all, i am curious about how this works. I posted this very same question in the anandtech forum but there are no replies.
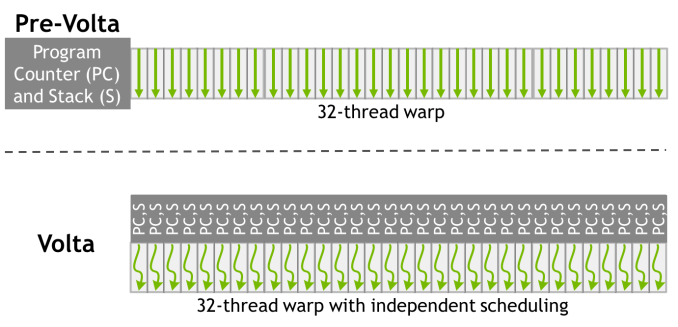
Does all the text below mean for volta that while all the 32 threads run in lockstep and some have different IF ELSE results to execute that no longer masking is needed ?
https://en.wikipedia.org/wiki/Single_instruction,_multiple_threads
https://www.anandtech.com/show/12170/nvidia-titan-v-preview-titanomachy/2
Hi all, i am curious about how this works. I posted this very same question in the anandtech forum but there are no replies.
Does all the text below mean for volta that while all the 32 threads run in lockstep and some have different IF ELSE results to execute that no longer masking is needed ?
Finally, and admittedly getting into the even more esoteric aspects of GPU design, NVIDIA has reworked how SIMT works for Volta. The individual CUDA cores within a 32-thread warp now have a limited degree of autonomy; threads can now be synchronized at a fine-grain level, and while the SIMT paradigm is still alive and well, it means greater overall efficiency. Importantly, individual threads can now yield, and then be rescheduled together. This also means that a limited amount of scheduling hardware is back in NV’s GPUs.
https://en.wikipedia.org/wiki/Single_instruction,_multiple_threads
A downside of SIMT execution is the fact that thread-specific control-flow is performed using "masking", leading to poor utilization where a processor's threads follow different control-flow paths. For instance, to handle an IF-ELSE block where various threads of a processor execute different paths, all threads must actually process both paths (as all threads of a processor always execute in lock-step), but masking is used to disable and enable the various threads as appropriate. Masking is avoided when control flow is coherent for the threads of a processor, i.e. they all follow the same path of execution. The masking strategy is what distinguishes SIMT from ordinary SIMD, and has the benefit of inexpensive synchronization between the threads of a processor
")